01 一种特殊的大数据
大数据可以用两种方式创造智能。
其一,大量的数据可以作为训练数据,让监督式机器学习方法特别是深度学习,发挥巨大潜力,从大量数据中学得智能,从而使智能机器能够大量代替人力来完成各种任务(此类智能系统可称为自主型智能系统)。
例如,大量的可用于训练无人驾驶车的数据可以很自然地从人的驾驶过程中通过传感器获得,使机器可以自动驾驶车辆;又如,大量的客户服务记录数据,可以用来训练客户服务机器人,自动回答客户的问题。
其二,大量的数据可以作为对我们生活的世界的感知和观察的结果的描述,用数据挖掘或非监督式机器学习方法对数据加以处理,获得关于被观察系统的各种有用知识,从而拓展人类的感知能力,增强人的智能(此类系统自身往往智能程度不高,可以称为助理型智能系统)。
例如,大量电子病历数据可以用来构造一个医生或病人的辅助诊疗的智能助手系统;又如,大量金融数据、社交媒体数据以及新闻数据可以用来构造金融方面的决策支持系统。
比较两类基于大数据的智能系统,自主型智能系统能完成的任务不能太复杂(因机器需独立完成任务),且对数据的要求较高,需要有标注的数据,而获取极大量的高质量的标注数据在很多问题领域并不现实,所以这类应用目前只能在少量的特定应用领域起作用。

而且,由于机器的智能主要来自于人工标注的数据,机器的智能不容易超越人的智能。
相反,助理型智能系统由于不需要有标注的数据,任何数据都可以利用,所以在任何领域都可以起作用,有着非常广泛的应用。而且,有趣的是,尽管助理型智能系统本身的智能不高,甚至没有太多智能,但这样的系统一旦与人结合,人与系统相加以后的综合智能往往能大大超越人的智能。
这种情形下,助理型智能系统的功能有与显微镜及望远镜的功能相似之处,即它们都可以拓展人对世界的感知能力,从而增强人的智能,特别是有助于在复杂应用领域优化决策。
作为一种特殊的大数据,文本数据泛指各种以自然语言形式存在的数据,包括万维网页、新闻报道、社交媒体、产品评论、科学文献、政府文件等;语音和视频数据,经语音识别后也能产生文本数据。文本数据有着极其广泛的应用。
第一,文本数据可被视为人,作为一个富有智能的主观“传感器”所产生的数据,它可以与所有其它非文本数据相结合,共同支持助理型智能系统;又因为任何应用领域都会涉及相关的人群,人们会以各种形式产生可用的文本数据,所以文本数据在任何领域都会有应用价值。
第二,由于人的主观性,文本数据富含关于人的观点、偏好以及需求等信息,所以特别有助于挖掘关于人的各种属性,使智能系统可以更好地理解用户,从而可以对每一个特定的用户进行优化服务(即个性化服务)。
第三,由于文本数据是人们用自然语言交流和通信的产物,它的语义很丰富,相比非文本数据来说,文本数据更加直接地表达知识。从数据挖掘的角度看,更容易让计算机自动获取知识。然而,由于自然语言是为人类通信而设计的,需要有大量的常识及推理能力,才能准确理解,所以尽管自然语言理解研究已取得很大进展,计算机目前还不能全面理解不受限的自然语言的结构和语义,所以在所有文本数据的应用中,必须充分利用人的自然语言理解能力,让计算机成为一个智能助理。
02 从文本中挖掘数据
在过去的20年里,我们经历了在线信息的爆炸性增长。根据加利福尼亚大学伯克利分校2003年的一项研究[Lyman等2003]:
……世界每年产生1~2EB(exabyte,艾字节)的不同信息,这对于地球上的男人、女人和孩子来说,每人大约250MB(megabyte,兆字节)。各类印刷文档仅占总量的0.03%。
大量的在线信息是文本信息(即自然语言文本)。例如,根据上面引用的伯克利的研究:
报纸每年发表25TB(terabyte,太字节或称兆兆字节)内容,杂志发表10TB内容……办公文档包含195TB内容。据估计,每年发送的电子邮件总数达到6100亿封,包含11000TB信息。
当然,还有博客文章、论坛帖子、推文、科技文献以及政府文件等。Roe[2012]将电子邮件数量从2003年的6100亿封更新为2010年的107万亿封。根据IDC最近的一份报告[Gantz和Reinsel 2012],2005~2020年,数字宇宙将增长300倍,规模达130EB~40000EB。
一般来说,各种类型的在线信息都是有用的,但由于以下原因,文本信息起着特别重要的作用,可以说是最有用的一种信息。
文本(自然语言)是人类知识最自然的编码方式。因此,大多数人类的知识都是以文本数据的形式编码的。例如,科学知识几乎都整理在科学文献中,而技术手册包含如何操作设备的详细说明。
文本是人们遇到的最常见的信息类型。事实上,一个人每天产生和消费的大部分信息都是文本形式的。
文本是最具表达能力的信息形式。它可以用来描述其他媒体,如视频或图像,甚至图像搜索引擎(如Google和Bing支持的图像搜索引擎)也经常依靠匹配图像周围的文本来检索“匹配”用户关键字查询的图像。
网络文本信息的爆炸式增长强烈需要能够提供以下两种相关服务的智能化软件工具,帮助人们管理和利用文本大数据。

1. 文本检索
文本数据的增长使得人们无法及时消费数据。由于文本数据对我们积累的大部分知识进行了编码,因此通常不会被丢弃,从而导致大量文献数据的积累,这些文献数据现在超出了任何个人能够处理的能力范围,即便只是简单浏览。
在线文本信息的快速增长也意味着没有人能够消化每天产生的所有新信息。因此,迫切需要开发智能文本检索系统,以帮助人们快速、准确地获取所需的相关信息。这种需求促进了近期网络搜索行业的迅猛发展。
事实上,像Google和Bing这样的网络搜索引擎现在已经成为我们日常生活中不可或缺的一部分,每天都有数以百万计的查询。通常,在大量文本数据存在的地方,搜索引擎都是有用的(诸如桌面搜索、企业搜索或特定领域中的文献搜索,例如PubMed)。
2. 文本挖掘
文本数据是人类为了交流而产生的,所以它们通常含有丰富的语义内容,并且通常包含有价值的知识、信息、观点和个人的喜好。它们提供了很多机会来发掘对于许多应用有用的各种知识,特别是关于人类意见和偏好的知识。这些知识通常直接在文本数据中表达。
例如,现在人们习惯于通过产品评论、论坛讨论和社交媒体文本等包含主观见解的文本数据来获取有关他们感兴趣的话题的观点,并优化各种决策任务,如购买产品或选择一项服务。
同样,由于信息的巨大规模,人们需要智能的软件工具来帮助发现相关知识以优化决策或帮助他们更有效地完成任务。尽管支持文本挖掘的技术还没有像支持文本获取的搜索引擎那么成熟,但近年来在这方面已经取得了显著的进展,专业的文本挖掘工具已经在许多应用领域得到了广泛使用。
结构化数据采用定义良好的模式,使计算机处理起来相对容易,与结构化数据相比,文本没有明显的结构,所以计算机在上述智能软件工具开发过程中需要处理和理解文本编码的内容。
目前的自然语言处理技术还没有达到使计算机能够精确理解自然语言文本的水平(这也是人类往往应该参与到处理过程的主要原因),但是采用许多不同的统计和启发式方法来管理和分析文本数据已经在过去的几十年中得到了发展。它们通常非常健壮,可以用于对任何自然语言、任何主题的文本数据进行分析和管理。
上面讨论的两种服务(即文本检索和文本挖掘)在概念上对应于分析任何“大规模文本数据”过程中的两个自然步骤,如图1-1所示。
▲图1-1 文本检索与数据挖掘是分析大规模文本数据的两项主要技术
尽管原始文本数据可能很大,但是具体的应用通常只需要少量最相关的文本数据,因此在概念上,任何应用的第一步应该是根据具体的应用或者决策去识别相关的文本数据,避免对大量不相关文本数据做不必要的处理。
将原始大规模文本数据转换成规模更小但高度相关的文本数据的第一步通常是在用户帮助下利用文本检索技术来完成(例如,用户可以使用多个查询来收集所有相关文本数据以用于决策问题)。在这第一步中,主要目标是将用户(或应用程序)与最相关的文本数据连接起来。
一旦获得一个小规模的最相关文本数据,我们需要对文本做进一步的分析来帮助用户消化文本数据中的知识和模式。这是文本挖掘的一个步骤,其目标是从文本数据中进一步发现知识和模式,以支持用户的任务。
此外,需要对任何发现的知识的可信度进行评估,所以用户通常需要返回到原始的文本数据中去获得用来解释所获得知识的上下文,并通过上下文信息验证知识的可信度。
因此,作为主要用于文本获取的搜索引擎系统,也必须在任何基于文本的决策支持系统中提供知识来源。因此,这两个步骤在概念上是交错的,一个完整的智能文本信息系统必须在一个统一的框架中进行整合。
值得指出的是,在“大数据”的背景下,文本数据与其他类型的数据是非常不同的,因为它通常是由人类直接生成的,通常也意味着要被人类消费。相反,其他数据往往是机器生成的(例如通过使用各种物理传感器收集的数据)。
由于人类可以比计算机更好地理解文本数据,所以人类参与挖掘和分析文本数据的过程绝对是至关重要的(比其他大数据应用程序更为必要)。如何最佳地将人与机器之间的工作分开从而优化人与机器之间的协作,以最少的人力来最大化其“智能组合”,是所有文本数据管理和分析应用中的一个普遍挑战。
以上讨论的两个步骤可以被认为是文本信息系统协助人类的两种不同的方式:
信息检索系统帮助用户从大量的文本数据中找到解决具体应用问题所需的最相关文本数据,从而有效地将大规模原始文本数据转换成可以被人类更容易处理的规模较小的相关文本数据;
而文本挖掘应用系统可以帮助用户分析文本数据中的模式,以提取和发现对于完成任务或进行决策直接有用的、可操作的知识,从而为用户提供更直接的任务支持。

03 文本信息系统的功能
从用户的角度来看,文本信息系统(TIS)可以提供三种不同但相关的功能,如图1-2所示。
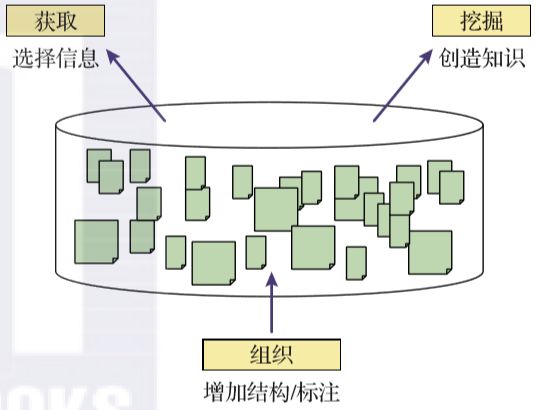
▲图1-2 信息获取、知识获取和文本组织是文本信息系统的三个主要功能,文本组织对信息获取和知识获取起到支撑作用,而知识获取也常被称为数据挖掘
1. 信息获取(information access)
这种能力使用户可以在需要时获取有用的信息。有了这个能力,文本信息系统可以在正确的时间连接正确的信息和正确的用户。例如,搜索引擎使得用户能够通过查询来获取文本信息,而推荐系统可以在发现可用的新信息项目时将相关信息推送给用户。
由于信息获取的主要目的是将用户与相关信息联系起来,提供这种能力的系统通常只对文本数据进行最小限度的分析,只需满足将相关信息与用户的信息需求匹配,而原始信息项目(例如,网页)通常以其原始形式交付给用户,但是也经常提供项目的摘要。
从文本分析的角度来看,用户通常需要阅读信息项目来进一步消化和利用所传递的信息。
2. 知识获取(knowledge acquisition)或文本分析(text analysis)
这种能力使得用户能够获得文本数据中蕴含的有用知识。如果没有对大规模的数据进行合成和分析,用户通常不容易获得这些知识。文本信息系统可以分析大量的文本数据以发现文本中隐藏的有趣模式。具有知识获取能力的文本信息系统可以被称为分析引擎。
例如,搜索引擎可以将产品的相关评论返回给用户,分析引擎可以使用户直接获得关于产品的主要的正面或负面意见,并比较人们对多个类似产品的意见。提供知识获取能力的系统通常需要更详细地分析文本数据,综合来自多个文本文档的信息,发现有趣的模式,创造新的信息或知识。
3. 文本组织(text organization)
此能力使系统能够用有意义的(主题)结构来注释一组文本文档,从而可以连接分散的信息,使用户可以根据该结构在信息空间中巡览。
虽然这样的结构可以被认为是从文本数据中获得的“知识”,并且直接对用户有用,但是通常它们仅用于促进信息获取或知识获取,或者兼而有之。
从这个意义上说,文本组织的能力在文本信息系统中起到了支持作用,使得信息获取和知识获取更加有效。例如,添加的结构可以允许用户使用结构上的约束进行搜索,或者根据结构进行浏览。考虑到结构的约束,结构也可以用来进行详细的分析。
信息获取可以进一步分为两种模式:拉取和推送。在拉取模式下,用户主动从系统中“拉”出有用的信息,在这种情况下,系统是被动的,等待用户提出请求,然后系统用相关信息回应。
当用户具有临时信息需求(即临时需要关于产品的意见)时,这种信息获取模式通常非常有用。例如,像Google这样的搜索引擎通常为用户提供拉取模式信息获取。在推送模式下,系统主动向用户“推”(推荐)它认为对用户有用的信息。
当用户具有相对稳定的信息需求(例如,一个人的爱好)时,推送模式常常工作良好;在这种情况下,系统可以“预先”知道用户的偏好和兴趣,从而能够向用户推荐信息而不需要用户采取主动。
拉取模式还包括两种互补的方式让用户获得相关信息:查询和浏览。在查询的情况下,用户通过(关键字)查询指定信息需求,系统将该查询作为输入并返回估计与查询相关的文档。在浏览的情况下,用户简单地沿着将信息项目链接在一起的结构进行巡览并逐渐地获得相关信息。
由于查询也可以被看作是一步即导航到一组相关文档,很显然,浏览和查询可以自然地交织。事实上,网络搜索引擎的用户通常交错进行查询和浏览。
从文本数据中获取知识通常是通过文本挖掘过程来实现的。文本挖掘可以被定义为挖掘文本数据以发现有用的知识。数据挖掘社区和自然语言处理(Natural Language Processing,NLP)社区都开发了文本挖掘的方法,但两个社区对这个问题的看法往往略有不同。
从数据挖掘的角度来看,我们可能将文本挖掘视为挖掘一种特殊的数据,即文本。遵循数据挖掘的总体目标,文本挖掘的目标自然会被视为发现和提取文本数据中的有趣模式,其中可能包括潜在主题、主题趋势或异常值。
从NLP的角度来看,文本挖掘可以被看作是理解自然语言文本的一部分,将文本转化为某种形式的知识表示,并基于提取的知识进行有限的推理。因此,一个主要的任务是执行信息抽取(information extraction),它的目标是识别和提取所涉及的各种实体(例如人员、组织和位置)及其关系(例如谁与谁见面)。
实际上,任何文本挖掘应用都可能涉及模式发现(即数据挖掘角度)和信息抽取(即NLP角度)。信息抽取丰富了文本的语义表示,使得模式发现算法能够生成语义上更有意义的模式,而不是直接处理文本的字或字符串表示。
文本挖掘的应用可以被分类为直接应用和间接应用。直接应用中被发现的知识将被用户直接消费,而间接应用中发现的知识不一定直接对用户有用,但可以通过提供更好的支持间接地帮助用户获取信息。知识获取也可以基于发现了什么知识来进一步分类。
然而,由于“知识”涉及的范围广泛,所以不可能使用少量的类别来覆盖所有的形式。尽管如此,我们仍然可以找出几个常见的类别。例如,可以发现的一种知识类型是一组隐藏在文本数据中的主题或子主题,它们可以作为文本数据中主要内容的简明摘要。另一种可以从用户生成的主观性文本中获得的知识是关于某个主题的观点的总体情感极性。
04 文本信息系统的概念框架
从概念上讲,文本信息系统可能由几个模块组成,如图1-3所示。
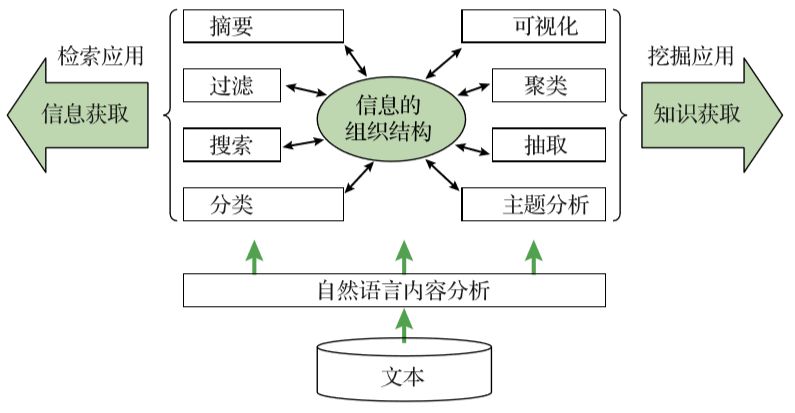
▲图1-3 文本信息系统的概念框架
首先,需要基于自然语言处理技术的内容分析模块。该模块允许系统将原始文本数据转换为更有意义的表示,以便在搜索引擎中可以更有效地与用户的查询匹配,在文本分析中可以更有效地进行处理。
目前的NLP技术主要依赖于统计机器学习,以有限的语言知识作为辅助,进行不同深度的文本数据理解;浅层技术是健壮的,但更深层的语义分析只适用于非常有限的领域。一些文本信息系统能力(如摘要)会比其他能力(如搜索)需要更深的NLP。
大多数文本信息系统使用非常浅的NLP,其中文本将被简单地表示为“词袋”,词是表示的基本单位,并且文本中词的顺序被忽略(尽管保留了词频)。然而,也可以使用更复杂的表示,可以基于识别出的实体、关系或其他更深层的文本理解技术。
以内容分析为基础,文本信息系统中有多个组件以不同的方式帮助用户。以下是管理和分析文本信息的一些常见功能。

1. 搜索(search)
接收用户查询并返回相关文档。文本信息系统中的搜索组件通常称为搜索引擎。网络搜索引擎是最有用的搜索引擎之一,它使用户能够有效和高效地处理大量的文本数据。
2. 过滤/推荐(filtering/recommendation)
监督传入的数据流,确定哪些项目与用户的兴趣相关(或不相关),然后向用户推荐相关项目(或者过滤掉不相关的项目)。
根据系统是否侧重于识别相关项目或不相关项目,这个组件可以被称为推荐系统(其目标是向用户推荐相关项目)或者过滤系统(其目标是过滤掉非相关项目,允许用户只保留相关项目)。文献推荐器和垃圾邮件过滤器分别是推荐系统和过滤系统的典型例子。
3. 分类(categorization)
将文本对象划分到一个或多个预定义类别,其中类别可根据应用程序而变化。文本信息系统中的分类组件可以用各种有意义的类别对文本对象进行注释,从而丰富了文本数据的表示,进一步提升了文本分析的效率和深度。类别也可用于组织文本数据,便于文本访问。
将文章分类为一个或多个主题类别的主题分类器和将句子分类为正面、负面或中性的情感极性的情感标注器都是文本分类系统的具体例子。
4. 摘要(summarization)
对一个或多个文本文件生成一个简要的内容摘要。摘要减少了人们消化文本信息的负担,也可以提高文本挖掘的效率。生成摘要的组件称为摘要器。新闻摘要和意见摘要都是摘要器的实例。
5. 主题分析(topic analysis)
提取并分析给定文档集合的主题。主题直接促进了用户对文本数据的理解,并支持浏览文本数据。当与相关的非文本数据如时间、地点、作者等元数据相结合,主题分析可以产生许多有趣的模式,如主题的时间趋势、主题的时空分布和作者的主题概况。
6. 信息抽取(information extraction)
从文本中提取实体、实体之间的关系或其他“知识单元”。信息抽取组件可以构建实体关系图。这种知识图有多种用途,包括支持导航(沿着图的边和路径)以及进一步应用图挖掘算法去发现有趣的实体关系模式。
7. 聚类(clustering)
发现相似文本对象(例如术语、句子及文档等)的群组。聚类组件在帮助用户探索信息空间方面起着重要的作用。它使用经验数据来创建有意义的结构,这对于浏览文本对象和快速理解大型文本数据集都非常有用。它对识别无法与其他对象聚集的异常对象也是非常有用的。
8. 可视化(visualization)
以可见的方式显示文本数据中的模式。可视化组件对于吸引人们参与发现有趣模式的过程非常重要。由于人类非常善于识别视觉模式,所以将各种文本挖掘算法产生的结果可视化有很大需求。