数据库
数据库:是一个组织内被应用程序使用的逻辑相一致的相关数据的集合。
数据管理系统(DBMS)
是定义、创建、维护数据库的一种工具,由硬件、软件、数据、用户、规程组成;DBMS也允许用户来控制数据库中数据的存取。
硬件
是指允许物理上存取数据的计算机硬件系统。eg.用户终端、硬盘等
软件
软件是指允许用户存取,维护和更新物理数据的实际程序。
数据
数据库中的数据存储在物理存储设备上。数据是独立于软件的一个实体。这种独立的性质使得组织可以在不改变物理数据及其存取方式的情况下,更换所应用的软件。
用户
它的实质我们可以用图表来解释:
即我们可以将用户大致分为两类:
| 最终用户 | 应用程序 |
|---|
最终用户:指直接从数据库中获取信息的用户。其中我们可以再次细分为:
- 数据库管理员(DBA):拥有最大的权限,可以控制其他用户以及他们对数据库的存取;也可以将他的一些特权授予其他用户并保留随时收回特权的能力。
- 普通用户:只能使用部分数据库和有限的存取操作。
应用程序:数据库中数据的其他使用者就是应用程序,应用程序需要存取和处理数据。
规程
最后一个部分装的,也就是必须被明确定义并需要数据库用户遵循的规则的集合。
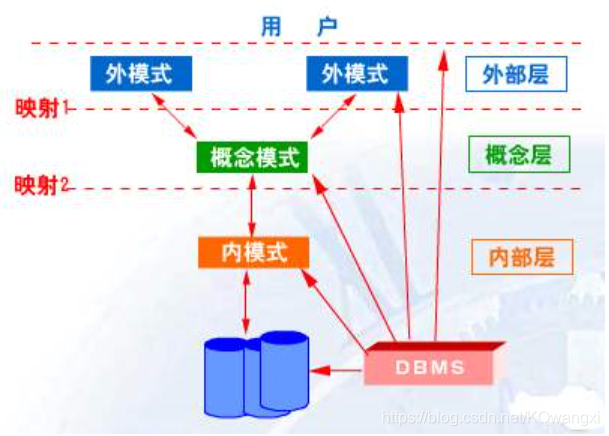
数据库管理系统的三层体系结构
内层
内层决定了数据在存储设备中的实际位置,这个层次用于处理低层次的数据存取方法和如何在存储设备间传输字节,换句话说,内层是直接与硬件交互的。
概念层
概念层定义了数据的逻辑视图,该层可以完成像查询这样的功能,它的设定使得用户不必与内层打交道了,因为它可以将数据库管理系统的数据内部视图转化为用户可以看到的外部视图。
外层
外层直接与用户交互,它可以将来自概念层的数据转化为用户所熟悉的格式和视图。
关系模型
关系模型中,数据组织成称为关系的二维表,表或关系之间相互关联。关系模型是目前数据库设计中最常用的模型。
关系数据库模型
在关系数据库管理系统(ROBMS)中,数据是通过关系的集合来表示的
关系
表面上,关系就是二维表,在ROBMS中,数据的外部视图就是关系或表的集合,但这并不代表数据以表的形式存储(要知道数据的物理存储与数据的逻辑组织的方式无关)
关系的特征:
- 名称:每种关系具有唯一的名称
- 属性:关系中的每一列都称为属性,每一个属性表示了存储在该列下的数据的含义,属性的总数决定了关系的度。
- 元组:关系中的每一行称为元组,元组定义了一组属性值,关系中元组的个数叫关系的基数。当对元组进行操作时(比如增加减少),关系的基数随之改变,从而实现了动态数据库。
关系的操作
我们在关系数据库中,定义一些操作来通过已知的关系创建新的关系。(eg.下文中我们可以了解到一些简单的一元关系如“插入,删除,更新,选择,投影”这些操作在数据库查询语言SQL中的定义)
SQL(结构化查询语言)
这是一种描述性的语言,意味着使用者不需要一步步地编写详细地程序而之只需声明它。
插入
插入属于一元操作,它只应用于一个关系,其作用是在表中插入新的元组,格式如下:
insert into RELATION-NAME values(...,...,...)
value子句定义了要插入的相应元组的所有属性,注意:在SQL语言中,字符串的值要用引号括起来,而数值不需要,我们看下面这个例子:

删除
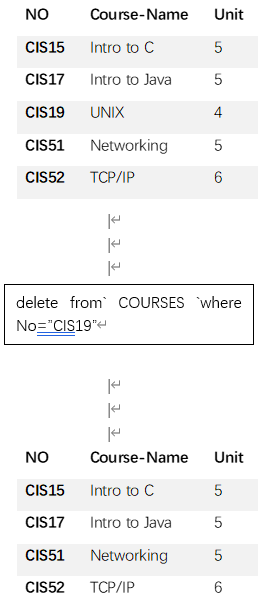
删除也是一元操作,根据要求删除表中相应的元组。删除操作格式如下:
delete from RELATION-NAME where criteria
删除条件是由where子句定义的,如图我们注意到条件为No=“CIS19”
更新
更新也属于一元操作,它应用于一个关系,用来更新元组中的部分属性值,更新操作使用如下格式:
update RELATION-NAME
set attributel=value1,attribute2=value2,...
where criteria
要改变的属性定义在set子句中,更新的条件定义在where子句中,如图:

选择
选择也是一元操作。它应用于一个关系并产生另外一个新关系,新关系中的元组(行)是原关系元组的子集。格式如下:
select *
from RELATION-NAME
where criteria
星号(*)表示所有的属性都被选择,如图:选择操作允许用户只选择含有5个单元的课程——

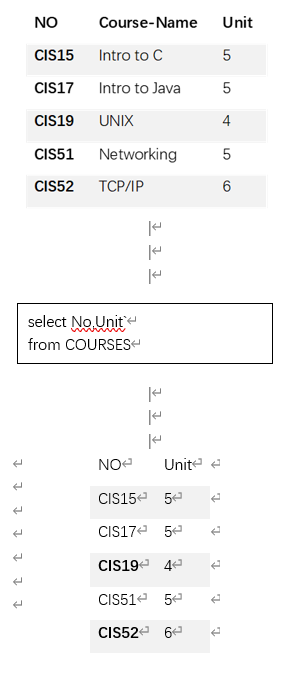
投影
投影也是一元操作,它应用于一个关系并产生另外一个新关系,新表中的属性(列)是原表中属性的子集,投影操作所得到的新关系中的元组属性减少,但元组(行)的数量保持不变。格式如下:
select attribute-list
from RELATION-NAME
如图:
以上,是较为浓缩的大概讲完了数据库的知识,而自己实际写的时候是简单模拟,重点其实放在了一元操作关系上。接下来,在试着用c++语言模拟一个数据库之前,自己整理了一些这次过程中新学到的知识:
- c库函数:strstr()的讲解
真正的sql有自己对应的函数,但在最开始写的时候自己是通过数组去保存信息的,而对于如何从输入流中提取需要保存的数据,我就是用这个函数进行关键字符的识别从而可以移动相应指针实现划分信息的目的。 - c++文件读写详解
- c++读写与getline()
在我模拟数据库实现的代码中最关键的就是对数据存储的控制和支配,在我的理解中,这次的尝试更像是通过设置类实现对应功能,操作结果以文本的形式保存下来,从而实现用户端(我)对整个数据流动的操控。 - 一些小细节:
①strcpy函数:strcpy(*a,*b)经过strcpy函数处理,是将b数组中的字符串复制到a数组中!
②c++中的c_str():
我们已知在c语言中没有string类型(string是c++中新的一个类),而假如我们遇到下列这个情况时:
char* c;
string s="1234";
c = s.c_str();
这样是不好的,因为:
(1)c_str()返回的是一个临时指针,不能对其进行操作
(2)c = s.c_str(); //c最后指向的内容是垃圾,string是一个类,这样的写法会使s对象被析构,其内容被处理
应该改为:
char c[20];
string s="1234";
strcpy(c,s.c_str());
这样其实是为了与c语言兼容,谨记在c语言中没有string类型(string是c++中新的一个类),故必须通过string类对象的成员函数c_str()把string 对象转换成c中的字符串样式。
总结:如果一个函数只要求得到char*参数同时不对该指针进行操作,这个时候可以使用c_str() 以 char* 形式传回 string 内含字符串内容。
string s = "Hello World!";
printf("%s", s.c_str()); //输出 "Hello World!"
- 编程devc++报错:error: no matching function for call to 'std::basic_ifstream::open(std::string&)
之后找到原因:
string filename = "1.txt";
ifstream fin;
fin.open(filename);
原因是C++的string类无法作为open的参数。
解决方案:使用C的字符串。
例:
char filename[10];
strcpy(filename, "1.txt");
ifstream fin;
fin.open(filename);