1.现象:
昨晚集群夯住,内存不够,导致HBase RegionServer挂了!
紧跟着CDH HBase Master(active)节点是红色的,显示信息:HBase Regions In Transition Over Threshold
这时我知道又遇见HBase RIT了。
2.常见解决方法:
2.1 重启HBase,尝试了2次后,发现HBase Master(active)节点是依旧红色的
虽然我们可以连接HBase,但是查询速度(dbeaver工具+Phoenix)上是非常慢的,
还抛错一个错误: Cache of region boundaries are out of date.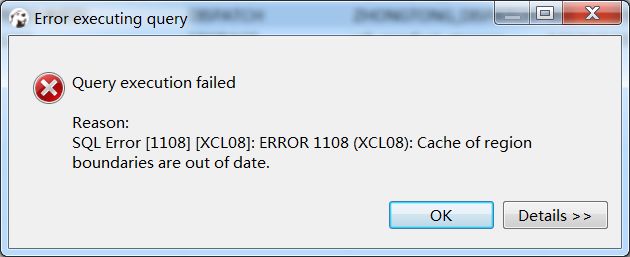
2.2 在master节点:使用hbase进程所在的用户
su - hbase
hbase hbck -fixAssignments
用于修复region assignments错误,观察发现越来越多的RIT的Regions,及时终止命令
也尝试了一下 hbase hbck、hbase hbck -repair,日志刷了很久也没解决。
2.3 查看master节点日志,发现如下日志
2018-08-21 09:50:47,924 INFO org.apache.hadoop.hbase.master.SplitLogManager: total tasks = 1 unassigned = 0 tasks={/hbase/splitWAL/WALs%2Fhadoop49%2C60020%2C1534734073978-splitting%2Fhadoop49%252C60020%252C1534734073978.null0.1534762936638=last_update = 1534816154977 last_version = 22 cur_worker_name = hadoop47,60020,1534815723497 status = in_progress incarnation = 2 resubmits = 2 batch = installed = 1 done = 0 error = 0}
由于日志刷的很快,加上是info级别,刚开始真心没注意!
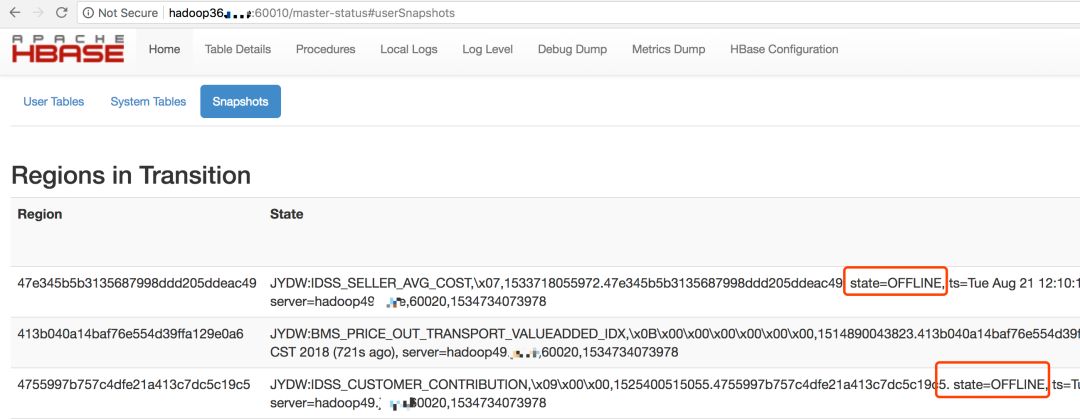
后来通过分析HBase master web界面,发现:
a.RIT的regions都是在hadoop49机器
b.master的log日志也是显示hadoop49机器的splitting log,
一直在in_progress状态
(观察差不多10分钟,一直再刷info级别且此状态)
3.暴力解决:
3.1 直接使用hdfs命令先找到日志,再rm删除(移除到回收站)
hadoop36:hdfs:/var/lib/hadoop-hdfs:>hdfs dfs -ls hdfs://nameservice1/hbase/WALs/*splitting
Found 1 items
-rw-r--r-- 3 hbase hbase 21132987 2018-08-20 19:02 hdfs://nameservice1/hbase/WALs/hadoop49,60020,1534734073978-splitting/hadoop49%2C60020%2C1534734073978.null0.1534762936638
hadoop36:hdfs:/var/lib/hadoop-hdfs:>
hadoop36:hdfs:/var/lib/hadoop-hdfs:>
hadoop36:hdfs:/var/lib/hadoop-hdfs:>hdfs dfs -rm hdfs://nameservice1/hbase/WALs/hadoop49,60020,1534734073978-splitting/hadoop49%2C60020%2C1534734073978.null0.1534762936638
18/08/21 12:46:15 INFO fs.TrashPolicyDefault: Moved: 'hdfs://nameservice1/hbase/WALs/hadoop49,60020,1534734073978-splitting/hadoop49%2C60020%2C1534734073978.null0.1534762936638' to trash at: hdfs://nameservice1/user/hdfs/.Trash/Current/hbase/WALs/hadoop49,60020,1534734073978-splitting/hadoop49%2C60020%2C1534734073978.null0.1534762936638
hadoop36:hdfs:/var/lib/hadoop-hdfs:>3.2 重启HBase,等待一会,一切正常,保证HBase对外提供服务。
3.3 因为我们删除的是HLOG文件,必然会丢失数据,故使用MCP实时中间件,web界面定制数据重刷job(昨晚19:00~21:00故障范围时间),恢复数据。
