Kafka集群:
首先,下载解压压缩包 kafka_2.11-2.0.0.tgz
到 /usr/kafka/
配置/usr/kafka/kafka_2.11-2.0.0/config/server.properties文件:
打开监听端口(打开这一行注释):
![]()
修改zookeeper.connect:
![]()
配置 broker 的ID:
![]()
修改 log 的目录:
![]()
然后就配置完成了
接着使用远程复制将/usr/下的kafka目录分发到其他节点
之后进入其他节点的server.properties文件修改如:
![]()
其他节点的broker.id=2 ....依次递增就好。
然后在每个节点上启动kafka命令如下:
![]()
/usr/kafka/kafka_2.11-2.0.0/bin/kafka-server-start.sh /usr/kafka/kafka_2.11-2.0.0/config/server.properties &
创建topic(命令):
kafka-topics.sh --create --zookeeper spark1:2181,spark2:2181,spark3:2181 --replication-factor 3 --partitions 3 --topic xxx (rf参数副本数,par参数分区数,xxx是topic的名称)创建topic
查看topic(命令):
/usr/kafka/kafka_2.11-2.0.0/bin/kafka-topics.sh -list --zookeeper spark1:2181,spark2:2181,spark3:2181
测试kafka是否可用:
创建生产者(在kafka的根目录下执行):
bin/kafka-console-producer.sh --broker-list spark1:9092,spark2:9092,spark3:9092 --topic test
创建消费者:
bin/kafka-console-consumer.sh --bootstrap-server spark1:9092 --topic test --from-beginning
生产者中输入消息:
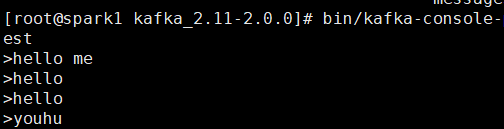
消费者实时接收消息:
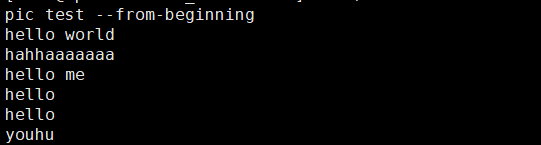
完成测试