sagemaker+deeplens报告
文章目录
Sagemaker学习
1. 使用boto3对S3操作
学sagemaker前先学习一下boto3库。因为使用Sagemaker要配合S3服务,使用这里 先学习boto3对S3服务的控制。
导入
import boto3
指定使用AWS上哪种服务
#获取s3服务资源对象(相比client对象拥有更高级的抽象调用)
s3 = boto3.resource('s3',region_name=region)
#获取S3客户端对象(原生)
s3_client = boto3.client('s3',region_name=region)
存储桶的三个操作对象
#通过资源对象
s3 = boto3.resource('s3',region_name=region)
#通过桶对象
s3.Bucket('mybucket')
#S3客户端对象
s3_client = boto3.client('s3',region_name=region)
创造一个S3存储桶
#定义区域,因为S3是全球服务,所以要声明要使用哪个区域的S3服务
region = 'us-west-2'
bucket_name = 'my-bucket'
#获取一个S3客户端对象
s3_client = boto3.client('s3',region_name=region)
s3_client.create_bucket(Bucket=bucket_name)
打印桶名
#s3 s3对象
#s3.buckets.all() 获得s3中的所有桶对象
#bucket.name 桶名
s3 = boto3.resource('s3')
for bucket in s3.buckets.all():
print(bucket.name)
删除存储桶
s3_client = boto3.client('s3',region_name=region)
s3_client.delete_bucket(Bucket='mybucket')
上传文件
#文件方式
s3 = boto3.resource('s3')
s3.Bucket('mybucket').upload_file('/tmp/hello.txt', 'hello.txt')
#对象方式
s3 = boto3.resource('s3')
with open('filename', 'rb') as data:
s3.Bucket('mybucket').upload_fileobj(data, 'mykey')
#s3.Bucket()方法返回指定的桶对象
#put_object() key:保存的文件名, Body:对象数据
s3 = boto3.resource('s3')
with open('filename', 'rb') as data:
s3.Bucket('my-bucket').put_object(Key='test.jpg', Body=data)
#使用客户端对象上传文件
s3_client = boto3.client('s3',region_name=region)
s3_client.upload_file('myfile', Bucket='my-bucket', Key='mys3file')
#使用客户端对象上传对象
s3_client = boto3.client('s3',region_name=region)
with open('filename', 'rb') as data:
s3_client.upload_fileobj(data, 'mybucket', 'mykey')
分段上传
关于分段上传这里解析一下:分段上传是将一个大型对象,切分为若干个中小片段,并对这若干个片段进行并行上传,从上传速度来将,分段上传可以明显比普通上传要快。
分段上传是一个三步过程:启动上传,上传对象部分,然后在上传所有部分之后,完成分段上传。
分段上传都有一个对应的ID号来识别唯一的上传操作。
s3_client = boto3.client('s3',region_name=region)
#创建分段上传
response = s3_client.create_multipart_upload(Bucket='my-bucket',Key='myfile')
#拿到上传ID
ID = response['UploadId']
#读取一个大型文件
data = open('file', 'rb')
#进行多段上传
s3_client.upload_part(Body=data,
Bucket='my-bucket',
Key='myfile',
PartNumber=5,
UploadId=ID)
#对上传到服务端多段数据发起合并请求
response2 = client.complete_multipart_upload(Bucket='examplebucket',
Key='myfile',
UploadId=ID)
从s3中下载文件
- bucket S3存储桶名字
- path 桶文件路径
- localhost_path 本地路径名
s3 = boto3.resource('s3')
#下载文件
s3.download_file(bucket, path, localhost_path)
#通过桶对象下载文件
s3.Bucket('mybucket').download_file('hello.txt', '/tmp/hello.txt')
#通过客户端下载文件对象
s3_client = boto3.client('s3')
with open('filename', 'wb') as data:
s3_client.download_fileobj('mybucket', 'mykey', data)
#通过客户端下载文件
s3_client.download_file('mybucket', 'hello.txt', '/tmp/hello.txt')
#通过get_object获取一个对象
#返回response,response包含对象的描述信息和数据体
response = s3_client.get_object_acl(
Bucket='examplebucket',
Key='HappyFace.jpg',
)
data = response['Body']
删除一个S3中的对象
#通过客户端删除
s3_client = boto3.client('s3',region_name=region)
s3_client.delete_object(Bucket='mybucket',Key='cat.jpg')
#通过桶对象删除
s3 = boto3.resource('s3')
s3.Bucket('mybucket').download_file('hello.txt', '/tmp/hello.txt')
获取区域名
boto3.Session.region_name
2.boto3调用sagemaker
2.1使用sagemakerRuntime
SageMakerRuntime.Client是一个运行时低级的客户端类,提供一些简易的方法供程序员调用sagemaker上的资源。
client = boto3.client('sagemaker-runtime')
SageMakerRuntime.Client提供了以下方法:
can_paginate()和get_paginator()
can_paginate(operation_name)用于判断一个方法是否允许分页。
get_paginator()用于个一个操作创建分页。
关于分页请求这个概念,这里简单描述一下:有些AWS操作返回的结果不完整,需要后续请求才能获得整个结果集。在前一个请求未处理的情况下发送后续请求以继续的过程称为分页。例如,amazon s3的list objects操作一次最多返回1000个对象,您必须使用适当的标记发送后续请求,以便检索下一页的结果。
这里引用官方的案例:
import botocore.session
# Create a session and a client
session = botocore.session.get_session()
client = session.create_client('s3', region_name='us-west-2')
# Create a reusable Paginator
paginator = client.get_paginator('list_objects')
# Create a PageIterator from the Paginator
page_iterator = paginator.paginate(Bucket='my-bucket')
for page in page_iterator:
print(page['Contents'])
invoke_endpoint()
这个方法比较常用,该方法用于调用一个sagemaker终端节点去做模型的结果推断。
- sagemaker终端节点是sagemaker的一项服务,用于将训练好的模型进行快速的部署并用于对数据集进行结果推断。(一个容器化部署的模型)
invoke_endpoint()所有参数如下:
response = client.invoke_endpoint(
EndpointName='string', #终端节点名字
Body=b'bytes'|file, #推断的数据
ContentType='string', #数据的格式
Accept='string', #推断结果的格式
CustomAttributes='string',
TargetModel='string',
TargetVariant='string',
InferenceId='string'
)
一个小示例:
假设你有一个终端节点叫myEndPoint,用来做猫狗分类的推断。
ENDPOINT_NAME = 'myEndPoint'
with open('cat.jpg', 'wb') as data:
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='image/jpeg',
Body=data)
#输出结果
print(response)
#response的结构
#{
# 'Body': StreamingBody(), 结果
# 'ContentType': 'string', 结果格式
# 'InvokedProductionVariant': 'string',
# 'CustomAttributes': 'string'
#}
3.sagemaker库
3.1EstimatorBase类
sagemaker有一个Estimator Base类,用于执行端对端的sagemaker的训练和部署任务
class sagemaker.estimator.Estimator
其构造参数:
sagemaker.estimator.EstimatorBase(role, instance_count=None, instance_type=None, volume_size=30, volume_kms_key=None, max_run=86400, input_mode='File', output_path=None, output_kms_key=None, base_job_name=None, sagemaker_session=None, tags=None, subnets=None, security_group_ids=None, model_uri=None, model_channel_name='model', metric_definitions=None, encrypt_inter_container_traffic=False, use_spot_instances=False, max_wait=None, checkpoint_s3_uri=None, checkpoint_local_path=None, rules=None, debugger_hook_config=None, tensorboard_output_config=None, enable_sagemaker_metrics=None, enable_network_isolation=False, profiler_config=None, disable_profiler=False, **kwargs)
3.1.1 具有以下方法:
获取训练镜像
#返回为训练用的一个docker镜像路径
training_image_uri()
#如:
training_image_uri(sess.boto_region_name, 'object-detection', repo_version="latest")
设置超参
#设置算法的参数(这根据你用的是哪个算法)
hyperparameters()
判断Estimator是否需要网络隔离
#判断Estimator是否需要网络隔离,返回bool类型
enable_network_isolation()
指定训练名
#指定训练名
prepare_workflow_for_training(job_name=None)
执行训练
#执行训练任务,
#inputs:训练通道 logs:日志 job_name:训练任务名
fit(inputs=None, wait=True, logs='All', job_name=None, experiment_config=None)
Neo编译
#使用Neo编译一个模型
#target_instance_family:标识编译后要运行模型的设备
#input_shape:通过dict的形象指定输入通道,
#如:{‘data’:[1,3,1024,1024]}, or {‘var1’: [1,1,28,28], ‘var2’:[1,1,28,28]}
#output_path:编译后的模型存储路径
#framework:框架
#framework_version:版本
#compile_max_run:设置编译超时秒数
#target_platform_os:捆绑的操作系统,如:linux
#target_platform_arch:系统位数,如:X86_64
#target_platform_accelerator:硬件加速器平台,如NVIDIA
compile_model(target_instance_family, input_shape,
output_path, framework=None,
framework_version=None, compile_max_run=900,
tags=None, target_platform_os=None,
target_platform_arch=None,
target_platform_accelerator=None,
compiler_options=None, **kwargs)
附加训练任务
#附加一个训练任务
#作用:绑定某个训练任务,可以获取对应的任务的配置,如果绑定的训练任务还在训练,那么绑定操作将被阻塞。
# 返回结果是:Estimator实例,通过该实例可以实现deploy()等操作
#training_job_name:绑定的训练任务名
#sagemaker_session: sagemaker的session
#model_channel_name:模型路径
classmethod attach(training_job_name, sagemaker_session=None, model_channel_name='model')
打印log
#打印log
logs()
部署终端节点
#部署终端节点
#只展示部分参数,具体看官方文档
#initial_instance_count:部署实例个数
#instance_type:实例类型
#返回:sagemaker.predictor.Predictor对象
#在sagemaker2.0中 RealTimePredictor已经被更名为Predictor
deploy(initial_instance_count, instance_type)
deploy(initial_instance_count, instance_type,endpoint_name=None)
注册模型包
#创建用于创建SageMaker模型或在市场上上市的模型包
#content_types:模型输入MIME类型(模型输入类型)
#response_types:模型输出MIME类型(模型输出类型)
#inference_instances:推断实例允许的实例类型列表
#transform_instances:批转换实例允许的实例类型
register(content_types, response_types, inference_instances, transform_instances)
创建模型对象
#创建一个模型
#返回的是:sagemaker.model.Model对象
create_model(**kwargs)
#接受以下参数:
#image_uri:一个docker容器镜像
#model_data:模型,一般是存放在s3中的模型(.tar.gz包)
#role:角色(与IAM服务有关)
#env:环境变量,dict类型,与image_uri指定的容器中有关变量
#name:模型名称
#vpc_config:vpc配置,部署时会用到
#enable_network_isolation:网络隔离,一般为false
#model_kms_key:kms的密钥(与kms服务有关)
3.1.2 使用小示例
本示例使用的是官方的示例,由于这个示例 有点久远,有些方法调用的还是sagemaker sdk v1版本的API,所有使用的时候可能会有提示警告。本人做了些许修改,完整代码请查阅:https://github.com/aws/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/object_detection_pascalvoc_coco/object_detection_incremental_training.ipynb
第一步:获取执行role
#本示例在jupyter notebook下运行
import sagemaker
from sagemaker import get_execution_role
#第一步获取执行权限
role = get_execution_role()
第二部:获取数据并进行处理
#从官方指定的地址下载2007年和2012年Pascal VOC 数据集
# Download the dataset
!wget -P /tmp http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
!wget -P /tmp http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
!wget -P /tmp http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# # Extract the data.
!tar -xf /tmp/VOCtrainval_11-May-2012.tar && rm /tmp/VOCtrainval_11-May-2012.tar
!tar -xf /tmp/VOCtrainval_06-Nov-2007.tar && rm /tmp/VOCtrainval_06-Nov-2007.tar
!tar -xf /tmp/VOCtest_06-Nov-2007.tar && rm /tmp/VOCtest_06-Nov-2007.tar
#如果你打算使用自己放在s3中的数据可以运行以下代码
#!aws s3 cp s3://my-bucket/data-path ./localhost-path
#运行官方提供的脚本文件
#这几行脚本代码是用于生成rec序列文件
#该文件在上面提供的网址的github目录下
!python tools/prepare_dataset.py --dataset pascal --year 2007,2012 --set trainval --target VOCdevkit/train.lst
!python tools/prepare_dataset.py --dataset pascal --year 2007 --set test --target VOCdevkit/val.lst --no-shuffle
#关于使用自己只定义的数据
#在使用官方提供的脚本时应该注意:如果你的数据集是按照Pascal VOC2007和Pascal VOC2012数据集
#构建的目录结构,请到脚本目录下的pascal_voc.names,更改你数据集中对应的便签名,官方提供的脚
#本将会读取该文件的label,用作生成.rec .lst等文件。更多的Pascal VOC目录结构请根据需要自行
#查找。
第三步:上传处理的数据到S3存储桶中
#上传到S3有很多方式,请参考上面boto3对s3的控制
import boto3
s3 = boto3.resource('s3')
#训练集的上传
train_localhost_path = ''
train_S3_path = ''
s3.Bucket('mybucket').upload_file(train_localhost_path, train_S3_path)
#验证集的上传
val_localhost_path = ''
val_S3_path = ''
s3.Bucket('mybucket').upload_file(val_localhost_path, val_S3_path)
第四步:获取内置算法镜像
#旧的API
#from sagemaker.amazon.amazon_estimator import get_image_uri
#training_image = get_image_uri(sess.boto_region_name, 'object-detection', repo_version="latest")
#新的API
sess = sagemaker.Session()
training_image = sagemaker.image_uris.retrieve("object-detection", sess.boto_region_name)
第五步:创建Estimator实例
s3_output_location = 's3的输出路径'
model = sagemaker.estimator.Estimator(training_image,
role,
instance_count=1,
instance_type='ml.p3.2xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location,
sagemaker_session=sess)
第六步:设置超参数
关于sagemaker内置算法:目标检测算法,其是用那种方式实现的。sagemaker中的目标检测算法是使用SSD (Single Shot multibox Detector)框架实现的。并支持两个基本网络: VGG 和 ResNet。 可以从头开始训练网络,也可以使用已在 ImageNet 数据集上预先训练的模型进行训练。
#不同的内置算法会有不同的超参数
#目标检测的超参数可以在以下网址中找到:
#https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/object-detection.html
model.set_hyperparameters(base_network='resnet-50',
use_pretrained_model=1,
num_classes=20,
mini_batch_size=32,
epochs=1,
learning_rate=0.001,
lr_scheduler_step='3,6',
lr_scheduler_factor=0.1,
optimizer='sgd',
momentum=0.9,
weight_decay=0.0005,
overlap_threshold=0.5,
nms_threshold=0.45,
image_shape=300,
label_width=350,
num_training_samples=16551)
第七步:训练
#旧的API
#train_data = sagemaker.session.s3_input(s3_train_data, distribution='FullyReplicated',
# content_type='application/x-recordio', s3_data_type='S3Prefix')
#validation_data = sagemaker.session.s3_input(s3_validation_data, distribution='FullyReplicated',
# content_type='application/x-recordio', s3_data_type='S3Prefix')
#data_channels = {'train': train_data, 'validation': validation_data}
#新的API如下:
from sagemaker.inputs import TrainingInput
train_data = '训练集S3路径'
validation_data = '验证集的S3路径'
train_channel = TrainingInput(train_data, content_type='application/x-recordio')
valid_channel = TrainingInput(validation_data, content_type='application/x-recordio')
data_channels = {
'train': train_channel, 'validation': valid_channel}
#开启训练
model.fit(inputs=data_channels, logs=True)
第八步:部署
object_detector = model.deploy(initial_instance_count = 1,
instance_type = 'ml.m4.xlarge')
第九步:验证模型
验证模型之前,请下载一张用于验证的图片。
file_name = 'test.jpg'
with open(file_name, 'rb') as image:
f = image.read()
b = bytearray(f)
ne = open('n.txt','wb')
ne.write(b)
import json
#预测
object_detector.content_type = 'image/jpeg'
results = object_detector.predict(b)
detections = json.loads(results)
print (detections)
#结果格式
#https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/object-detection-in-formats.html
#可视化函数
def visualize_detection(img_file, dets, classes=[], thresh=0.6):
"""
visualize detections in one image
Parameters:
----------
img : numpy.array
image, in bgr format
dets : numpy.array
ssd detections, numpy.array([[id, score, x1, y1, x2, y2]...])
each row is one object
classes : tuple or list of str
class names
thresh : float
score threshold
"""
import random
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img=mpimg.imread(img_file)
plt.imshow(img)
height = img.shape[0]
width = img.shape[1]
colors = dict()
for det in dets:
(klass, score, x0, y0, x1, y1) = det
if score < thresh:
continue
cls_id = int(klass)
if cls_id not in colors:
colors[cls_id] = (random.random(), random.random(), random.random())
xmin = int(x0 * width)
ymin = int(y0 * height)
xmax = int(x1 * width)
ymax = int(y1 * height)
rect = plt.Rectangle((xmin, ymin), xmax - xmin,
ymax - ymin, fill=False,
edgecolor=colors[cls_id],
linewidth=3.5)
plt.gca().add_patch(rect)
class_name = str(cls_id)
if classes and len(classes) > cls_id:
class_name = classes[cls_id]
plt.gca().text(xmin, ymin - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor=colors[cls_id], alpha=0.5),
fontsize=12, color='white')
plt.show()
object_categories = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
# Setting a threshold 0.20 will only plot detection results that have a confidence score greater than 0.20.
threshold = 0.20
# Visualize the detections.
visualize_detection(file_name, detections['prediction'], object_categories, threshold)
最后一步:关闭终端节点
sagemaker.Session().delete_endpoint(object_detector.endpoint)
部署基于SSD的目标检测模型上AWS deeplens
1.AWS deeplens的两版本
AWS deeplens有两个版本,分别是:V1.1,和V1.0
关于这两个版本的硬件区别:https://docs.aws.amazon.com/zh_cn/deeplens/latest/dg/deeplens-hardware.html
关于硬件和软件的版本区别这里就不多说,这里主要介绍如何将自己的深度学习模型部署到deeplens上面。
2.关于注册
关于注册我就不多说了,官方文档有具体说明https://docs.aws.amazon.com/zh_cn/deeplens/latest/dg/deeplens-getting-started-register.html
2.1关于摄像头恢复出厂设置后注册的坑
如果你重置摄像头恢复了出厂设置,(假设你当前的设备为V1.1版本)使用V1.1版本的注册方法,但是控制台中怎么都无法检测到摄像头的USB注册口,那可能是重置后的版本没有装好USB注册口的驱动,那么你应该使用一下V1.0的方式注册,V1.0注册中有一个步骤是更新设备软件,更新完软件后可以改为V1.1的方式进行设备的注册。
3.支持的框架
当前AWS deeplens支持一下深度学习框架:MXNet,TensorFlow,Caffe
如果你使用的是其他的算法框架,并要部署到AWS deeplens上面部署,你可能需要一些使用工具将你当前使用的框架训练出来的模型转换为MXNet,TensorFlow,Caffe这三个框架模型。
之所以使用这三个框架,很大一部分原因是:他那个AWS deeplens摄像头里面用的是Intel® Atom 处理器因为摄像头会使用英特尔的一些模型优化工具将这三个框架训练处理的模型转换为摄像头可以处理的优化中间件,关于这个中间件,我后面会详细说明。
现在你需要知道的是AWS deeplens只支持三种框架,而sagemaker内置算法训练处理的模型用的是MXNet,所以如果你使用的是sagemaker训练的深度学习模型,基本可以无缝地放到AWS deeplens上面跑。(但是如果是基于SSD的目标检测模型,可以还需要一些格外的处理。)
4.选择算法
改步骤主要针对sagemaker和AWS deeplens集成服务,因为这里选择的是SSD的目标检测模型(一种目标检测算法),所以在选择算法的时候请选择:Object Detection
关于更多的算法需要去官方文档看。
AWS DeepLens 是一款支持深度学习的视频摄像机。它与多个 AWS 机器学习服务集成,并可根据从 AWS 云预配置的部署模型执行本地推理。所以DeepLens主要是搭载那些机器视觉模型的,主要还是:Object Detection,image classification,图像风格转换
5.将MXNet框架下的SSD模型转发为可部署模式
这个只针对MXNet框架下的训练的SSD模型。
关于将SSD模型转发为可部署模式,这里需要说明一下为什么要转换为部署模式,在sagemaker训练的过程中,sagemaker的内置算法会在模型的网络结构中添加一些只在训练中才有用的网络结构:如dropout,smooth等,但我们部署模型时是不需要这些层的,这时我们需要将模型转化为部署模式。
官网文档中提供的地址不对了(不知道现在改了没),现在打开这个地址:https://github.com/apache/incubator-mxnet/tree/master/,然后使用GitHub将MXnet整个库下载下来,然后在git中运行如下命令:
git reset --hard 73d88974f8bca1e68441606fb0787a2cd17eb364
该命令是将GitHub的本地仓库回滚到指定的版本,因为官方是要求用这个版本的MXnet的进行部署模式的转换。
然后进入到这个库目录中,部署脚本就在MXnet项目目录下的:
cd incubator-mxnet/example/ssd/
然后将模型放到model文件夹下面然后对模型压缩包进行解压,解压后会发现两个文件,一个叫:
- model_algo_1-0000.params
- model_algo_1-symbol.json
后缀为.params的文件是模型,.json的文件是模型网络的拓扑结构。
转化为部署模式
然后运行以下命令:
python deploy.py --network resnet50 --prefix F:\Mxnet\incubator-mxnet\example\ssd\model\model_algo_1 --data-shape 300 --num-class 2
这里只解析我使用的参数,更多的参数自己看那个脚本或者使用 –help。
- –network 网络结构
- –prefix 模型的工程前缀(去掉文件后缀后的路径就是你的工程前缀)
- –data-shape 模型输入成的大小(这里300,是指图片是300*300的格式,图片通道数默认是3)
- –num-class 检测分类的个数
保存到S3存储桶
将转化为部署模式的SSD模型,重新打包成tar.gz压缩包,并放到存储桶进行存储。如果你用的是window系统的话,去下载个7Z压缩,7Z压缩能制作tar.gz压缩包。如果你是使用Linux系统,在命令行输入:
tar czvf my.tar.gz file1 file2 ....fileN
- file1 file2 …fileN是要压缩的文件
- my.tar.gz是压缩后压缩包的名字
6.创建样例模板的lambda函数
官方文档的lambda样例比较旧,所以使用控制台中官方样例中的lambda样例,进入AWS deeplens控制台选择Projects,创建项目
然后到lambda函数服务的控制台,会发现多出一个lambda函数,如下:

进入这个lambda函数的编辑页
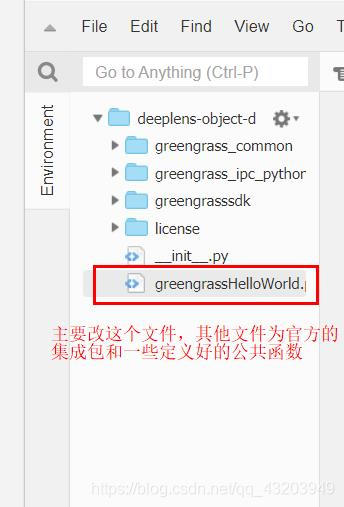
编辑好自定义的lambda函数,记得发布版本,只有发布了的版本才能部署到deeplens上

7.关于lambda函数
AWS deeplens需要lambda函数协助,利用lambda函数AWS deeplens可以调用模型进行推断,AWS deeplens里面保存了模型和lambda函数,在AWS deeplens中创建项目需要绑定一个模型和一个lambda函数,当摄像头进行模型部署的时候,AWS deeplens将会上传模型和lambda函数到摄像头设备上。当摄像头运行时,将调用lambda的函数将视频帧传递给模型进行处理,并将处理后的视频帧传到项目流那里。
在AWS deeplens摄像头注册成功时,会创建如下两个lambda函数,请勿删除:
- deeplens_admin_version_poller
- deeplens_admin_model_downloader
关于编写lambda函数
lambda函数可以使用官方的简单案例的模板,然后看他那个核心代码。因为要调用模型对视频帧进行处理,所以要调用一些核心接口:
关于设备库看官方文档:https://docs.aws.amazon.com/zh_cn/deeplens/latest/dg/deeplens-device-library.html
mo模块
mo模块是用来优化模型并生成AWS DeepLens 表示形式(也就是中间件)
import mo
error, model_path = mo.optimize(model_name, input_width, input_height, platform, aux_inputs)
- model_path 中间件路径
awscam模块
awscam模块用来获取视频帧
import awscam
#获取视频帧,video_frame是视频帧
ret, video_frame = awscam.getLastFrame()
awscam模块有个Model类,用来加载机器学习模型
import awscam
#加载的是经过mo模块优化后的模型
#model = awscam.Model(model_topology_file, loading_config),如:
model = awscam.Model(model_path, {
'GPU': 1})
#调用模型的接口进行视频帧推断
#raw_inference_results = model.doInference(video_frame)
#解析结果
#result = model.parseResult(model_type, raw_infer_result)
#如:
parsed_inference_results = model.parseResult(model_type,
model.doInference(frame_resize))
8.deeplens的模型中间件
将 AWS DeepLens 模型构件从 Caffe(.prototxt 或 .caffemodel)、MXNet(.json 和 .params)或 TensorFlow (.pb) 表示形式转换为 AWS DeepLens 表示形式并执行必要的优化。
关于这个优化模块去Intel优化工具OpenVINO的官网看:https://docs.openvinotoolkit.org/latest/index.html
关于这个中间件去这里看:https://docs.openvinotoolkit.org/latest/openvino_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html
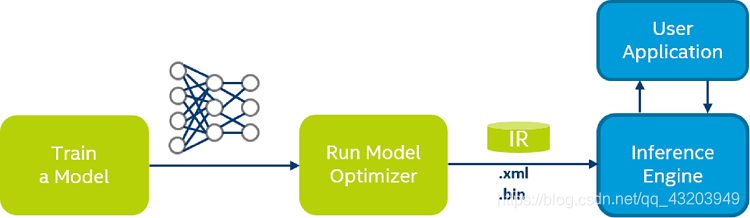
.xml-描述网络拓扑.bin-包含权重并偏置二进制数据。
deeplens中的优化脚本在目录
cd /opt/awscam/intel/deeplearning_deploymenttoolkit/deployment_tools/model_optimizer
有几个优化脚本:
- mo_caffe.py
- mo_kaldi.py
- mo_mxnet.py
- mo_onnx.py
- mo_tf.py
- mo.py
我用的mxnet框架,所以使用的是mo_mxnet.py
#查看有哪些参数
python3 mo_mxnet.py -h
#一些使用案例
python3 mo_mxnet.py --input_model /home/aws_cam/model/model_algo_1-0000.params --data_type FP16 --scale 1 --model_name model_algo_1 --reverse_input_channels --input_shape [1,3,300,300] --legacy_mxnet_model
当然我们一般不用这些脚本,我们一般在lambda函数中通过mo.optimize来进行模型的转化和优化。
本地上传模型到deeplens摄像头并生成中间件,避免模型下载慢问题
不过这里也引出了一些小技巧,因为AWS deeplens只在部分区开放了服务,当涉及到跨区域时,就可能会面临网络带宽问题。因为上传模型到云端,然后通过摄像头自动化部署从云端的下载模型到摄像头本地并部署,这个下载的过程可能十分缓慢。这是我们可以优先在本地上传模型到摄像头内部,然后通过脚本在deeplens内部生成模型中间件,然后在lambda函数指明模型中间件位置即可。而云端可以捆绑的一个空壳的模型和一个改写好路径的lambda函数,然后调用自动部署功能。
9.进行部署
部署步骤如下:
- 导入模型
- 创建项目
- 部署
9.1导入模型
导入模型可以从一下地方导入:
- S3
- sagemaker
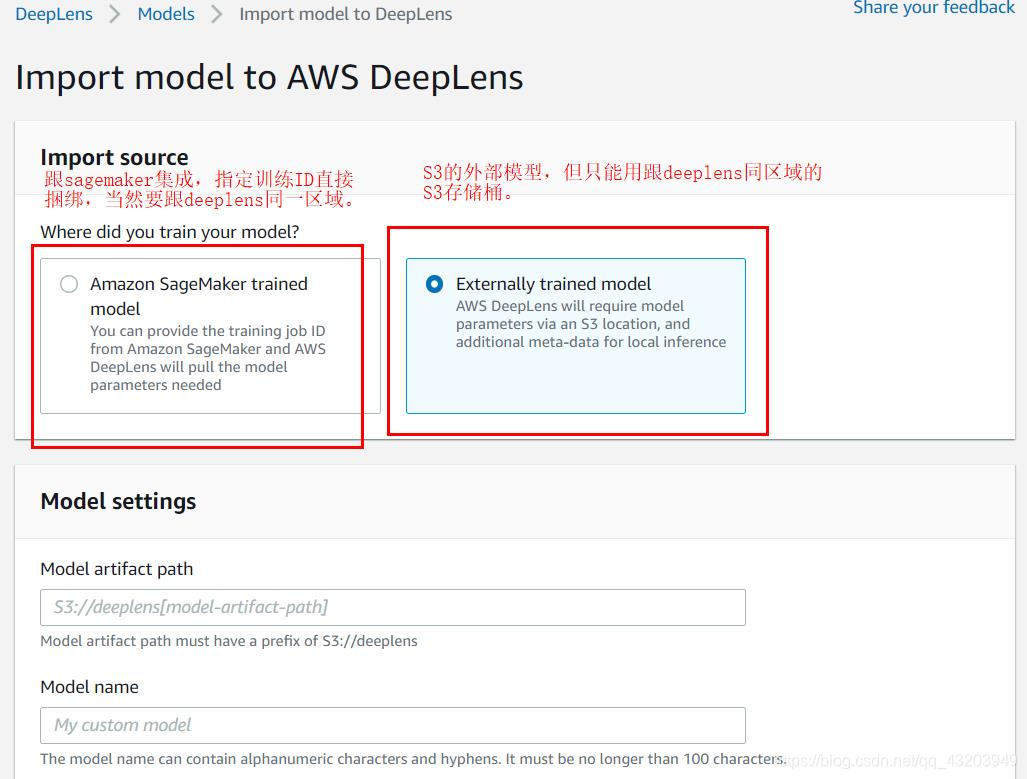
9.2创建项目
创建一个项目需要两样东西:一个是模型,一个是lambda函数
模型只能有一个,而lambda函数至少有一个。
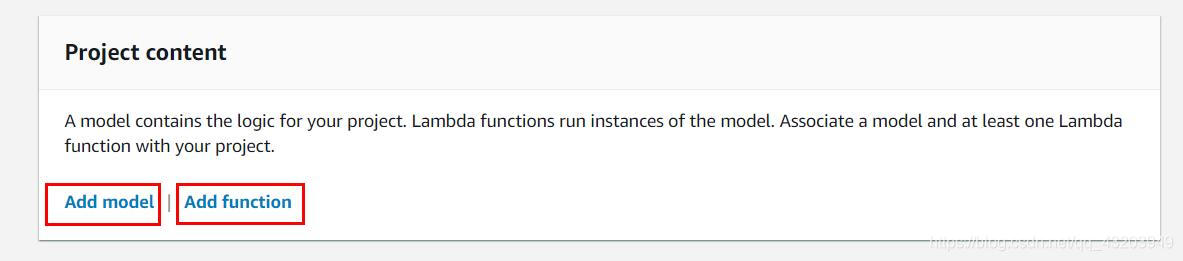
9.3部署
因为是自动化部署,选择好部署的项目一键部署即可,这个部署过程并不难,好部署好项目核心内容主要还是如何使用lambda函数进行视频帧的处理,和如何对深度学习的网络的输出进行解析。

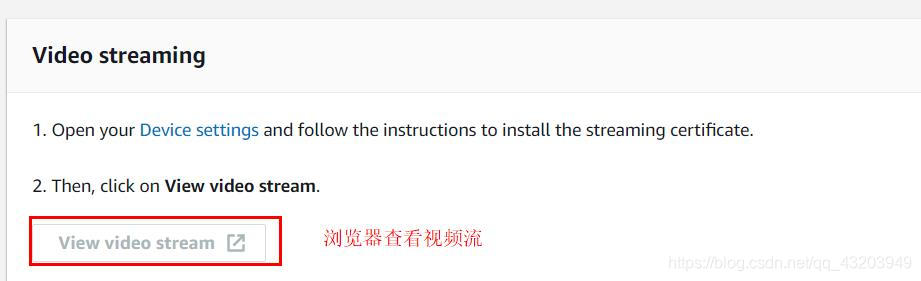
10.在浏览器中查看项目输出流
deeplens本来就是一台计算机,设备开放4000端口,供给其他计算机用浏览器访问,并查看项目视频流的输出,
地址:https://your-device-ip-address:4000,your-device-ip-address是你设备的私网IP地址。
用浏览器对摄像头的指定开放端口进行访问前请确保你是有下载证书的,关于证书下载去官方文档看,整个执行的过程可以分一下基本分:
- 下载证书到本地
- 将证书导入到浏览器
- 通过浏览器访问deeplens的指定端口
- 查看项目流的输出
11.制作U盘成为可引导设备
这里主要是制作USB 闪存驱动器成为可引导设备,这是为了制作将AWS Deeplens恢复到出厂设置的引导U盘。官方文档提供的在Ubuntu下制作为引导U盘,我这里在window系统下制作。
11.1格式化U盘并对U盘分区
U盘要分两个区
- 第一个分区:2 GB 的 FAT32
- 第二个分区:至少 9 GB 的 NTFS
第一分区是用来引导设备安装,而第二分区就是你的摄像头系统镜像了。
分区可以使用分区助手或其他分区软件,window系统自带的分区功能应该也能分U盘, FAT32和NTFS是U盘的两种系统,式化时可以选择的。
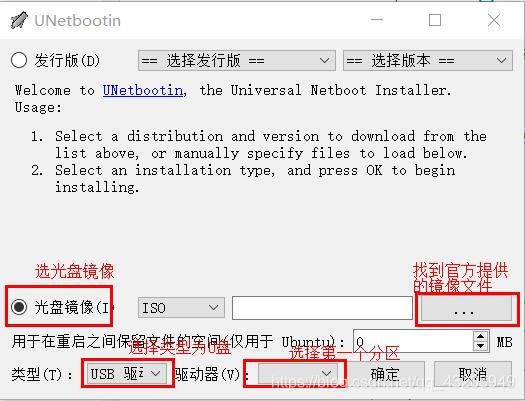
11.2 将第一个盘制作成可引导盘
去下载一个叫unetbootin的软件,软件长这样,然后安装我给的截图操作即可。
11.3 剩余步骤
剩余步骤按官方文档操作即可,https://docs.aws.amazon.com/zh_cn/deeplens/latest/dg/deeplens-device-factory-reset-preparation.html
12.排坑
deeplens连接到WiFi了,但是还控制台还是长时间显示offline
可能是greengrassd服务卡住了,在deeplens终端运行一下代码:
sudo systemctl restart greengrassd.service --no-block