pandas
1、导入数据并查看
1、导入相关库
# -*- coding : utf-8 -*-
#coding: unicode_escape
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
2、读入数据并复制,防止后续处理损坏源数据
data_features=pd.read_csv('./dataset/550_70s.csv',error_bad_lines=False,encoding='gbk')
data_object=pd.read_csv('./dataset/class1.csv',error_bad_lines=False,encoding='gbk')
data1=data_features.copy()
data2=data_object.copy()
data1
3、查看数据
每一行代表一个样本,每一列代表一个特征。

4、查看最后几行数据
data1.tail()

5、获取Dataframe中的每个样本的标号信息
data1.index

6、将Dataframe转化为矩阵
data1.to_numpy()
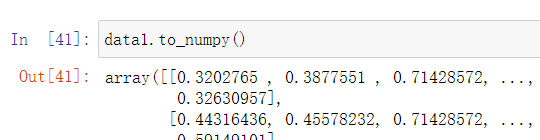
注意:转换结果没显示全。
7、查看每个特征的均值、最大值、最小值等信息
data1.describe()

注意:结果仅显示重要部分。
8、查看数据信息
data1.info()

2、对DataFrame信息进行提取
1、按照某一列的数值大小对所有样本进行升序或者降序排列
# 如果axis=0,那么by等于“列名”;如果axis=1,那么by=“行名”,默认为0。ascending是布尔型,True则升序,False则降序。
data1.sort_values(by='AN',axis=0, ascending=True)

注意:结果仅显示重要部分。
2、将DataFrame的行列进行交换
data1.T

注意:结果仅显示重要部分。
3、提取某一列
data1.AN # 与data1['AN']等效

注意:结果仅显示重要部分。
4、切片处理
data1[2:4] # 提取出第2,3行

data1.loc[:,['AN','VA']] # 提取出所有行,提取出抬头为‘AN’和VA列

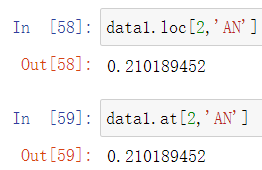
5、提取出指定位置的标量值
data1.loc[2,'AN'] # 与data1.at[2,'AN']等效
6、提取指定行、指定列的值
# 按照位置选择
data1.iloc[[1,4,5],[0,2]] # 行取1、4、5行,列取0和2列。
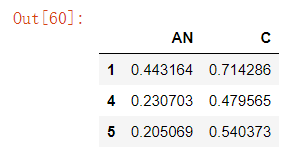
data1.iloc[1:3,:]
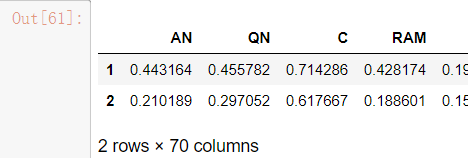
data1.iloc[4:,2:6]

暂时更新到这儿。