概述
STL(Standard Template Library),即标准模板库,是一个高效的C++程序库,包含了诸多常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。
STL容器主要分为
- 顺序容器
- vector(向量容器)
- deque(双端队列容器)
- list(双向链表)
- 关联容器
- set(单重集合)
- multiset(双重集合)
- map(单重映射表)
- multimap(多重映射表)
- 容器适配器
- stack(栈)
- queue(队列)
- prority_queue(优先级队列,又叫二叉堆)
顺序容器
vector
在内存中分配一块连续的内存空间进行存储。支持不指定vector大小的存储。STL内部实现时,首先分配一个非常大的内存空间预备进行存储,即capacity()函数返回的大小, 当超过此分配的空间时再整体重新放分配一块内存存储,这给人以vector可以不指定一个连续内存的大小的感觉。通常此默认的内存分配能完成大部分情况下的存储。
vector是按照数据push_back进入的顺序进行存放的
#include <vector>
//vector属于std命名域的,因此需要通过命名限定,如下完成你的代码:
using std::vector;
vector<int> v;
//或者连在一起,使用全名:
std::vector<int> v;
//建议使用全局的命名域方式:
using namespace std;
//1.vector的声明
vector<ElemType> c; //创建一个空的vector
vector<ElemType> c1(c2); //创建一个vector c1,并用c2去初始化c1
vector<ElemType> c(n) ; //创建一个含有n个ElemType类型数据的vector;
vector<ElemType> c(n,elem); //创建一个含有n个ElemType类型数据的vector,并全部初始化为elem;
c.~vector<ElemType>(); //销毁所有数据,释放资源;
//2.vector容器中常用的函数。(c为一个容器对象)
c.push_back(elem); //在容器最后位置添加一个元素elem
c.pop_back(); //删除容器最后位置处的元素
c.at(index); //返回指定index位置处的元素
c.begin(); //返回指向容器最开始位置数据的指针
c.end(); //返回指向容器最后一个数据单元的指针+1
c.front(); //返回容器最开始单元数据的引用
c.back(); //返回容器最后一个数据的引用
c.max_size(); //返回容器的最大容量
c.size(); //返回当前容器中实际存放元素的个数
c.capacity(); //同c.size()
c.resize(); //重新设置vector的容量
c.reserve(); //同c.resize()
c.erase(p); //删除指针p指向位置的数据,返回下指向下一个数据位置的指针(迭代器)
c.erase(begin,end) //删除begin,end区间的数据,返回指向下一个数据位置的指针(迭代器)
c.clear(); //清除所有数据
c.rbegin(); //将vector反转后的开始指针返回(其实就是原来的end-1)
c.rend(); //将vector反转后的结束指针返回(其实就是原来的begin-1)
c.empty(); //判断容器是否为空,若为空返回true,否则返回false
c1.swap(c2); //交换两个容器中的数据
c.insert(p,elem); //在指针p指向的位置插入数据elem,返回指向elem位置的指针
c.insert(p,n,elem); //在位置p插入n个elem数据,无返回值
c.insert(p,begin,end) //在位置p插入在区间[begin,end)的数据,无返回值
//3.vector中的操作
operator[] //如: c.[i];
// 同at()函数的作用相同,即取容器中的数据。
下面用一段程序说说明vector的用法
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
int i, n;
std::vector<int> v;
std::vector<int>::iterator it;
for (i = 1; i <= 10; i++) {
v.push_back(i);
}
for (it = v.begin(); it != v.end(); it++) {
std::cout << *it << std::endl;
}
//下面是查询
it = find(v.begin(), v.end(), 3);
if (it == v.end()) {
std::cout << "这个数不在程序中" << std::endl;
}
else
{
std::cout << *it << std::endl;
}
//下面是排序
sort(v.begin(), v.end()); //升序进行排序
reverse(v.begin(), v.end()); //降序进行排序
for (i = 0; i < v.size(); i++) {
std::cout <<v.at(i) << std::endl;
std::cout << v[i] << std::endl;
}
system("pause");
return 0;
}
链表
首先来说下单链表,单链表作为一个数据结构来说,里面有两个域:存储元素的数据域,存储下一个节点的指针域(存放的是下一个节点的地址)。

下面用一段程序来说明链表的数据结构
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <stdio.h>
//下面这个就是链表的结构
struct ListNode
{
int val;
ListNode *next;
};
using namespace std;
int main()
{
ListNode a;
ListNode b;
ListNode c;
ListNode d;
ListNode e;
a.val = 10;
b.val = 20;
c.val = 30;
d.val = 40;
e.val = 50;
a.next = &b;
b.next = &c;
c.next = &d;
d.next = &e;
e.next = NULL;
ListNode *head = &a;
while (head) {
cout << head->val << endl;
head = head->next;
}
system("pause");
return 0;
}
关联容器
set
Set的特性是。所有元素都会根据元素的键值自动被排序。multiset特性及用法和set完全相同,唯一的差别在于它允许键值重复。set和multiset的底层实现是红黑树,红黑树为平衡二叉树的一种。
set的一些函数具体如下:
#include<set> //set 的头文件
set<int> s; //声明一个int型set变量,名为s
s.empty() //判定 s 是否为空
s.insert(1); //把数字1插入到s中
s.clear(); //清空s
s.erase(1); //假若s存在1,则删除1
s.begin(); //返回s中第一个元素地址 所以 *s.begin()
s.end(); //返回s中最后一个元素地址
//这个特殊一点,返回的是s中最后一个元素的下一个元素
//所以 *(--s.end())是s最后一个元素
s.rbegin(); //rbegin可以看做逆向的第一个地址 相当于(--s.end()) 此处取的已经是s最后一个元素
s.rend(); //rend可以看做逆向的最后一个地址 相当于 s.begin()
s.count(1); //计算s中1出现的次数,而次数只存在0与1,所以可以借来查找是否存在1
s.size(); //返回s中元素的个数
s.max_size(); //s最大能存元素的数目
s.find(2); //查找2
set<int>::iterator iter; //迭代器
erase(iterator) //删除定位器iterator指向的值
erase(first,second) //删除定位器first和second之间的值
erase(key_value) //删除键值key_value的值
//lower_bound(key_value) ,返回第一个大于等于key_value的定位器
//upper_bound(key_value), 返回最后一个大于等于key_value的定位器
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(3);
s.insert(4);
cout<<*s.lower_bound(2)<<endl;
cout<<*s.lower_bound(3)<<endl;
cout<<*s.upper_bound(3)<<endl;
return 0;
}
下面用代码来说明一下set的用法
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <queue>
#include <set>
#include <functional> //需要注意的是,如果使用less<int>和greater<int>,需要头文件
int main()
{
std::set<int> test_set;
const int A_LEN = 7;
const int B_LEN = 8;
int a[A_LEN] = { 5,1,4,8,10,1,3 };
int b[B_LEN] = { 2,7,6,3,1,6,0,1 };
for (int i = 0; i < A_LEN; i++) {
test_set.insert(a[i]);
}
for (std::set<int>::iterator it = test_set.begin(); it != test_set.end(); it++) {
std::cout << *it << std::endl;
}
//下面是set集合find的一般用法,如果找到这个数的话,会返回这个数的地址,也就是迭代器的值,如果没有找到的话,就会返回end()的地址
//实际上这个end()地址就是set集合最后一个元素的后面的地址
for (int i = 0; i < B_LEN; i++) {
if (test_set.find(b[i]) != test_set.end()) {
std::cout << "b" << i << "=" << b[i] << "在A中" << std::endl;
}
}
system("pause");
return 0;
}
map
Map的特性是,所有元素都会根据元素的键值自动排序。Map所有的元素都是pair,同时拥有实值和键值,
pair的第一元素被视为键值,第二元素被视为实值,map不允许两个元素有相同的键值。
且不可以通过map的迭代器改变map的键值,修改map的实值,是可以的。
Multimap和map的操作类似,唯一区别multimap键值可重复。
map的基本操作函数
begin() //返回指向map头部的迭代器
clear() //删除所有元素
count() //返回指定元素出现的次数
empty() //如果map为空则返回true
end() //返回指向map末尾的迭代器
equal_range() //返回特殊条目的迭代器对
erase() //删除一个元素
find() //查找一个元素
get_allocator() //返回map的配置器
insert() //插入元素
key_comp() //返回比较元素key的函数
lower_bound() //返回键值>=给定元素的第一个位置
max_size() //返回可以容纳的最大元素个数
rbegin() //返回一个指向map尾部的逆向迭代器
rend() //返回一个指向map头部的逆向迭代器
size() //返回map中元素的个数
swap() //交换两个map
upper_bound() //返回键值>给定元素的第一个位置
value_comp() //返回比较元素value的函数
具体的细节操作看下面这个博客,很不错
容器适配器
栈(stack)
栈的基本知识(无法使用迭代器,无法对队列进行遍历,所以如果有遍历要求的话就不能使用栈)

栈的基本方法(5个)
- 队列的基本属性
- S.size() ——栈的存储元素个数
- S.empty() ——判断栈是否为空
- 队列的基本操作
- S.top() ——取出栈顶
- S.pop() ——弹出栈顶
- S.push(x) ——将X压入栈
队列
队列的基本知识(这里需要注意的是queue中无法使用迭代器,无法对队列进行遍历,所以如果有遍历要求的话就不能使用队列)。
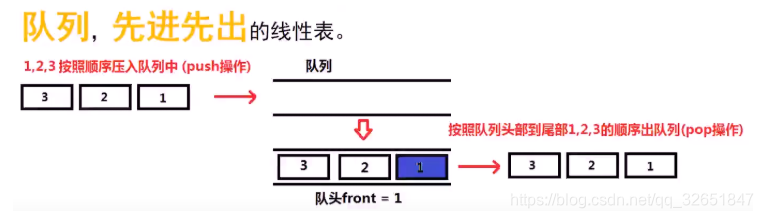
队列的基本方法(6个)
- 队列的基本属性
- Q.size() ——返回队列存储元素的个数
- Q.empty() ——判断队列是否为空
- 队列的基本操作
- Q.front() ——返回队列头部元素
- Q.back() ——返回队列尾部元素
- Q.pop() ——弹出队列头部元素
- Q.push(x) ——将x添加至队列(正常添加到队列的后面)
堆
预备知识:
二叉堆属性
最大(小)二叉堆,最(大)小值先出的完全二叉树。堆的top为O(1)的时间复杂度,调整和插入、删除是logn的时间复杂度,n就是第几大的数字。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5vecwxxc-1614154550201)(C:\Users\wl\AppData\Roaming\Typora\typora-user-images\image-20210218163520098.png)]](https://img-blog.csdnimg.cn/20210224161731148.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMyNjUxODQ3,size_16,color_FFFFFF,t_70)
基本方法
- 自身的属性方法
- heap.empty();
- heap.size();
- 自身的操作的方法
- heap.top();
- heap.pop();
- heap.push()
下面是示例代码
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <queue>
#include <functional> //需要注意的是,如果使用less<int>和greater<int>,需要头文件
int main()
{
std::priority_queue<int> big_heap; //默认构造是最大堆
std::priority_queue<int, std::vector<int>,std::greater<int>> small_heap; //最小堆构造方法
std::priority_queue<int, std::vector<int>, std::less<int>> big_heap2; //最大堆构造方法
if (big_heap.empty()) {
std::cout << "big_heap is empty" << std::endl;
}
int test[] = { 6,10,1,7,99,4,33 };
//下面是最大堆的方法,最小堆同样的道理
for (int i = 0; i < 7; i++)
{
big_heap.push(test[i]);
}
std::cout << "big_heap.top is=" << big_heap.top() << std::endl;
big_heap.push(1000);
std::cout << "big_heap.top is=" << big_heap.top() << std::endl;
for (int i = 0; i < 3; i++) {
big_heap.pop();
std::cout << big_heap.top() << std::endl;
}
system("pause");
return 0;
}