论文名称:Objects as Points
论文地址:https://arxiv.org/pdf/1904.07850.pdf
早些时候的目标检测大多是基于anchor的,像Faster RCNN,Yolov2(v3),SSD等等。这些算法(1)都是在feature map上去撒满成百上千的anchor,虽然accuracy和recall不错,但计算开销会比较大;(2)需要进行NMS后处理,这一过程是不可导的,因此会给端到端训练带来困难。
基于以上两个弊端,作者提出了一种基于Heatmap的anchor-free的算法,即CenterNet。CenterNet不再需要人为的设置anchor的各种相关参数,也不用复杂的NMS后处理,那么我们简单的看看CenterNet是怎么work的。
Heatmap
假设输入图像 I ∈ R W ∗ H ∗ C I\in R^{W*H*C} I∈RW∗H∗C(W,H,C分别代表输入图像的宽高和通道数),我们的目标是得到一张有关instance中心点的Heatmap: Y ^ ∈ [ 0 , 1 ] W R ∗ H R ∗ C \hat{Y}\in [0,1]^{ {\frac{W}{R}*\frac{H}{R}*C}} Y^∈[0,1]RW∗RH∗C(R表示经过backbone以后下采样的尺寸,文中是4;C表示的是数据集类别数,如coco数据集C=80)。对于这样一张0-1之间的Heatmap,假设某个点 Y ^ x , y , c \hat{Y}_{x,y,c} Y^x,y,c越接近于1,则该点越有可能代表着物体的中心;反之 Y ^ x , y , c \hat{Y}_{x,y,c} Y^x,y,c越接近于0,则其属于background。backbone文中采用了DLA和Resnet等模型,在此不做赘述。
我们可以轻松地通过CNN去得到这样一张Heatmap,我们要怎样利用呢?既然得到了Heatmap,那也需要把annotation制作成一致的形式。对于该图像 I I I中所有的instance的中心点 p ∈ R 2 p\in R^{2} p∈R2,首先计算其低分辨率上的等价: p ~ = ⌊ p R ⌋ \tilde{p}=\lfloor \frac{p}{R} \rfloor p~=⌊Rp⌋,然后根据公式: Y x y c = e x p ( − ( x − p ~ x ) 2 + ( y − p ~ y ) 2 2 σ p 2 ) Y_{xyc}=exp(-\frac{(x-\tilde p_{x})^2+(y-\tilde p_{y})^2}{2\sigma_{p}^{2}}) Yxyc=exp(−2σp2(x−p~x)2+(y−p~y)2),计算每一点上的值 Y x y c Y_{xyc} Yxyc,得到通过GT计算出来的热图,并将其作为指导CenterNet训练的标注。注意,如果一个image中有多个instance,则一个点只取最大的高斯计算结果。
因此,对于Heatmap的损失函数如下:

该损失采用了focal loss,主要目的是平衡正负样本数量和加重惩罚一些hard example,具体原因可参见该博客。在这里 α = 2 , β = 4 \alpha=2,\beta=4 α=2,β=4,N表示image的关键点的个数,用以将positive的focal loss标准化为1。
Offset
在计算Heatmap中,我们将GT的box坐标统一到feature map的大小,但是采用了向下取整,因此会损失一些精度。因此在网络的预测输出中,再加入一个local offset O ^ ∈ R W R ∗ H R ∗ 2 \hat{O}\in R^{
{\frac{W}{R}*\frac{H}{R}*2}} O^∈RRW∗RH∗2。对于所有的类别c都共享offset,这部分损失函数可以表示为:
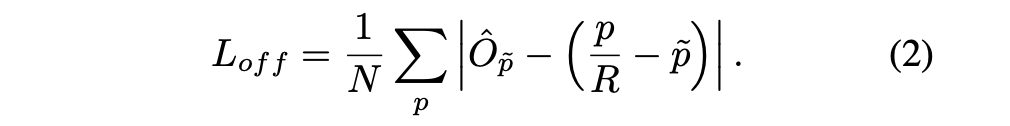
offset loss采用了常规的L1 loss。
Objects as Points
预测Heatmap和offset相当于得到instance的位置信息,除了他们,还需要预测instance的size S ^ ∈ R W R ∗ H R ∗ 2 \hat{S}\in R^{
{\frac{W}{R}*\frac{H}{R}*2}} S^∈RRW∗RH∗2。这里就是简单地预测宽高(并没有考虑尺度,只是采用原始的宽高),同样采用L1 loss:
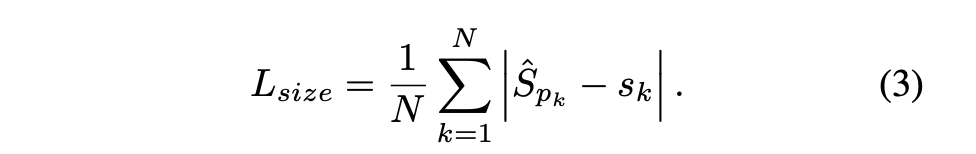
最终的loss形式如下:
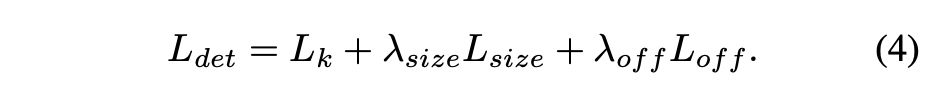
其中 λ s i z e = 0.1 , λ o f f = 1 \lambda_{size}=0.1,\lambda_{off}=1 λsize=0.1,λoff=1时效果最好。
总结一下,网络预测Heatmap,offset,以及size。因此对于feature map上的每个点,都拥有C+4维度的预测。这三部分预测都共享一个backbone,而在得到feature map以后各自通过3x3卷积,Relu,1x1卷积,得到各自不同的预测,如下图所示:

Inference
将一张image喂入CenterNet,即可得到 W R ∗ H R ∗ ( C + 4 ) \frac{W}{R}*\frac{H}{R}*(C+4) RW∗RH∗(C+4)维的输出。对于Heatmap来说,找出所有的比8邻域的值都要大的点,并取出top100个这样的点。然后再选出其中对应Heatmap的值(可看作confidence)大于某个阈值(文中设定0.3)的点,并进行最终的预测:
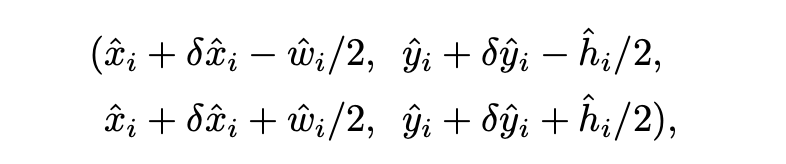
第一项就是Heatmap对应位置的整数坐标,第二项就是预测的offset,第三项的wh则是预测的instance的宽高,这样就能够得到instance的准确位置和大小了。
文章还将网络改造,用于3d Detection,pose estimation等task,本文在此不展开了。
实验结果

