
Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system's capability to withstand turbulent conditions in production.
——Principles of Chaos
混沌工程是在分布式系统上进行实验的学科,目的是建立对系统抵御生产环境中失控条件的能力以及信心。
一、概述
工程师团队最不愿碰到的便是大半夜被电话叫醒,开始紧张地查验问题,处理故障以及恢复服务。也许就是因为睡前的一个很小的变更,因某种未预料到的场景,引起蝴蝶效应,导致大面积的系统混乱、故障和服务中断,对客户的业务造成影响。特别是近几年,尽管有充分的监控告警和故障处理流程,这样的新闻在 IT 行业仍时有耳闻。问题的症结便在于,对投入生产的复杂系统有多少信心。监控告警和故障处理都是事后的响应与被动的应对,那有没有可能提前发现这些复杂系统的缺陷呢?
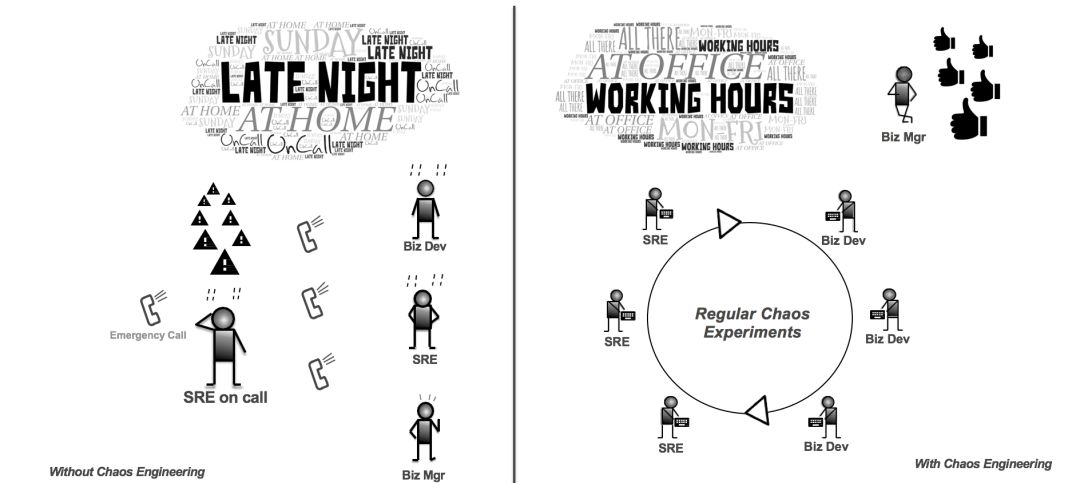
混沌工程在分布式系统上进行由经验指导的受控实验,观察系统行为并发现系统缺陷,以建立对系统在规模增大时因意外条件引发混乱的能力和信心。
1. 混沌工程的发展简史
2008年8月, Netflix 主要数据库的故障导致了三天的停机, DVD 租赁业务中断,多个国家的大量用户受此影响。之后 Netflix 工程师着手寻找替代架构,并在2011年起,逐步将系统迁移到 AWS 上,运行基于微服务的新型分布式架构。这种架构消除了单点故障,但也引入了新的复杂性类型,需要更加可靠和容错的系统。为此, Netflix 工程师创建了 Chaos Monkey ,会随机终止在生产环境中运行的 EC2 实例。工程师可以快速了解他们正在构建的服务是否健壮,有足够的弹性,可以容忍计划外的故障。至此,混沌工程开始兴起。

图中展示了混沌工程从2010年演进发展的时间线:
- 2010年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具:Chaos Monkey
- 2011年 Netflix release了其猴子军团工具集:Simian Army
- 2012年 Netflix 向社区开源由 Java 构建 Simian Army,其中包括 Chaos Monkey V1 版本
- 2014年 Netflix 开始正式公开招聘 Chaos Engineer
- 2014年 Netflix 提出了故障注入测试(FIT),利用微服务架构的特性,控制混沌实验的爆炸半径
- 2015年 Netflix release了 Chaos Kong ,模拟AWS区域(Region)中断的场景
- 2015年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
- 2016年 Kolton Andrus(前 Netflix 和 Amazon Chaos Engineer )创立了 Gremlin ,正式将混沌实验工具商用化
- 2017年 Netflix 开源 Chaos Monkey 由 Golang 重构的 V2 版本,必须集成 CD 工具 Spinnaker(持续发布平台)来使用
- 2017年 Netflix release了 ChAP (Chaos Automation Platform, 混沌实验自动平台),可视为应用故障注入测试(FIT)的加强版
- 2017年 由Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版
- 2017年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架
2. Chaos Monkey & Simian Army
为了更好的理解混沌工程,这里我们再着重介绍一下Chaos Monkey和Simian Army。Chaos Monkey 通过关停一个或多个虚拟机来模拟 service 实例的失效。Chaos Monkey 的名字来源于其工作的方式:如同一只野生的、武装了的猴子,在数据中心释放后,造成的严重破坏。
Chaos Monkey 的原则:避免大多数失效的主要方式就是经常失效。失效一定会发生,并且无法避免。在大多数情况下,我们的应用设计要保证当服务的某个实例下线时仍能继续工作,但是在那些特殊的场景下,我们需要确保有人在值守,以便解决问题,并从问题中进行经验学习。基于这个想法,Chaos Monkey 仅会在工作时间内被使用,以保证工程师能发现警告信息,并作出适当的回应。
混沌工程实验像 Chaos Monkey 只是杀杀机器而已?这是错误的理解。回溯混沌工程发展的时间线,业界对混沌工程的理解是逐步深入的。Netflix 开发的 Chaos Monkey 成为了混沌工程的开端,但混沌工程不仅仅是 Chaos Monkey 这样一个随机终止 EC2 实例的实验工具。随后混沌工程师们发现,终止 EC2 实例只是其中一种实验场景。因此, Netflix 提出了 Simian Army 猴子军团工具集,除了 Chaos Monkey 外还包括:
- Chaos Gorilla:Chaos Monkey的升级版,模拟整个Amazon Availability Zone的故障,以此验证在不影响用户,且无需人工干预的情况下,能够自动进行可用区的重新平衡。
- Chaos Kong:Chaos Gorilla的升级版,模拟整个region(一个region由多个Amazon Availability Zone组成)的故障。
- Latency Monkey:在RESTful服务的调用中引入人为的延时来模拟服务降级,测量上游服务是否会做出恰当响应。通过引入长时间延时,还可以模拟节点甚至整个服务不可用。
- Conformity Monkey:查找不符合最佳实践的实例,并将其关闭。例如,如果某个实例不在自动伸缩组里,那么就该将其关闭,让服务所有者能重新让其正常启动。
- Doctor Monkey:查找不健康实例的工具,除了运行在每个实例上的健康检查,还会监控外部健康信号,一旦发现不健康实例就会将其移出服务组。(隔离出服务,并且给相关人员足够的纠错时间,最终再关闭。)
- Janitor Monkey:查找不再需要的资源,将其回收,这能在一定程度上降低云资源的浪费。
- Security Monkey:这是Conformity Monkey的一个扩展,检查系统的安全漏洞,同时也会保证SSL和DRM证书仍然有效。
- 10-18 Monkey:进行本地化及国际化的配置检查,确保不同地区、使用不同语言和字符集的用户能正常使用Netflix。
使用 Simian Army 进行混沌工程实验,看起来似乎已经很完美。类似像 Latency Monkey 的引入,由于服务之间的调用链传递,到最后这个小的扰动到底会引发多大的故障,没有人可以预测。在生产上做这样不可控的实验,是很危险的。随着故障注入测试(FIT,Failure Injection Testing)的提出,社区开始关注利用应用架构的特性(特别是微服务架构)来控制实验的爆炸半径,比如 Netflix 使用 Zuul 强大的流量检查和管理功能,将受影响的请求隔离到特定的测试帐户或特定设备,避免100%的混乱。(本文来自公众号:朱小厮的博客,ID: hiddenkafka)
进一步分析发现, FIT 的执行过程也影响了整个系统的监控指标,即实验群体与其他非实验群体的统计指标混合不可分辨:无法确定实验的进行时间,无法评估其影响是否超过了系统本身的噪音。为了进一步的区分,则需要进行更多更大的实验,这将有可能给用户带来不必要的中断。因此需要对实验集群和非实验群集的流量配比进行精细控制,同时因应无人值守的实验要求,则引入微服务架构中的断路器,如其超出预定义的误差预算,自动结束实验。这就是为何 Netflix 提出了新的 ChAP 以加强故障注入测试。
综上所述,混沌工程的发展不是一蹴而就的, Chaos Monkey 是其开端,但社区对混沌工程的理解在逐步深入,从对基础设施的扰动( EC2 实例随机终止等),到利用应用网关控制爆炸半径,再到精细化流量配比以区分影响,直至引入断路器实现真正的无人值守。
混沌工程9年来的发展,由浅入深,由基础设施演进到应用架构,不是单单运维看看就好。今天,许多公司(包括Google、Amazon、Microsoft、Germlin Inc.、University of California、Github、Thoughtworks等)都使用某种形式的混沌工程实验,来提高现代架构的可靠性。
混沌工程也同样适用于传统行业,如大型金融机构、制造业和医疗机构。交易依赖复杂系统吗?有大型银行正在使用混沌工程来验证交易系统是否有足够的冗余。是否有人命悬一线?在美国,混沌工程在许多方面被当做模型应用在了临床试验系统中,从而形成了美国医疗验证的黄金标准。横跨金融、医疗、保险、火箭制造、农业机械、工具制造、再到数字巨头和创业公司,混沌工程正在成为复杂系统改进学科的立足点。
3. 混沌工程与传统测试之间的区别
混沌工程和传统测试(故障注入FIT、故障测试)在关注点和工具集上都有很大的重叠。譬如,在Netflix的很多混沌工程实验研究的对象都是基于故障注入来引入的。混沌工程和这些传统测试方法的主要区别在于:混沌工程是发现新信息的实践过程,而故障注入则是对一个特定的条件、变量的验证方法。
当你希望探究复杂系统如何应对异常时,对系统中的服务注入通信故障(如超时、错误等)不失为一种很好的方法。但有时我们希望探究更多其他的非故障类的场景,如流量激增、资源竞争条件、拜占庭故障(例如性能差或有异常的节点发出有错误的响应、异常的行为、对调用者随机性的返回不同的响应,等等)、非计划中的或非正常组合的消息处理等等。因为如果一个面向公众用户的网站突然收到激增的流量,从而产生更多的收入时我们很难称之为故障,但我们仍然需要探究清楚系统在这种情况下的影响。
和故障注入类似,故障测试方法通过对预先设想到的可以破坏系统的点进行测试,但是并没能去探究上述这类更广阔领域里的、不可预知的、但很可能发生的事情。
在传统测试中,我们可以写一个断言(assertion),即我们给定一个特定的条件,产生一个特定的输出。测试一般来说只会产生二元的结果,验证一个结果是真还是假,从而判定测试是否通过。严格意义上来说,这个过程并不能让我们发掘出对于系统未知的、尚不明确的认知,它仅仅是对我们已知的系统属性可能的取值进行测验。而实验可以产生新的认知,而且通常还能开辟出一个更广袤的对复杂系统的认知空间。
混沌工程是一种帮助我们获得更多的关于系统的新认知的实验方法。它和已有的功能测试、集成测试等以测试已知属性的方法有本质上的区别。(本文来自公众号:朱小厮的博客,ID: hiddenkafka)
混沌工程实验的可能性是无限的,根据不同的分布式系统架构和不同的核心业务价值,实验可以千变万化。下面是部分混沌实验的输入示例:
- 模拟整个云服务区域或整个数据中心故障;
- 跨多实例删除部分 Kafka 主题来重现生产环境中发生过的问题;
- 挑选一个时间段,和针对一部分流量,对其涉及的服务间调用注入一些特定的延时;
- 方法级别的混乱(运行时注入):让方法随机抛出各种异常;
- 在代码中插入一些指令可以允许在这些指令之前运行故障注入;
- 强制系统节点间的时间不同步;
- 在驱动程序中执行模拟 I/O 错误的程序;
- 让某个 Elasticsearch 集群 CPU 超负荷。
4. 实施混沌工程的先决条件
在引入混沌工程之前先要确定你的系统是否已经具备一些弹性来应对真实环境中的一些异常事件,像某个服务异常、网络闪断、瞬间延迟提高等。
混沌工程非常适合揭露生产系统中的未知缺陷,但如果确定混沌工程实验会导致系统出现严重的问题,那么运行这样的实验是没有任何意义的。你需要先解决这个缺陷,然后再引入混沌工程,然后你不仅能继续发现更多不知道的缺陷,还能提高对系统真实弹性水平(resilient)的信心。
引入混沌工程的另一个先决条件是监控系统,你需要用它来判断系统当前的各项状态。如果你没有对系统行为的可见能力,那么也就无法从实验中得出有效的结论。
二、混沌工程的五大原则
为了具体地解决分布式系统在规模上的不确定性,可以把混沌工程看作是为了揭示系统缺陷而进行的实验。破坏稳态的难度越大,我们对系统行为的信心就越强。如果发现了一个缺陷,那么我们就有了一个改进目标。避免在系统规模化之后问题被放大。
以下原则描述了应用混沌工程的理想方式,这些原则来实施实验过程,对这些原则的匹配程度能够增强我们在大规模分布式系统的信心。
1. 建立一个围绕稳定状态行为的假说(Build a Hypothesis around Steady State Behavior)
“稳定状态”是指系统正常运行时的状态。具体来说,系统的稳定状态可以通过一些指标来定义,当系统指标在测试完成后,无法快速恢复稳态要求,可以认为这个系统是不稳定的。
指标可以分为系统指标和业务指标。系统指标(如CPU 负载、内存使用情况、网络 I/O等)有助于帮助我们诊断性能问题,有时也能帮助我们发现功能缺陷。在混沌工程中,业务指标通常比系统指标更有用,因为它们更适合衡量用户体验或运营。业务指标通常回答这样的问题:
- 我们正在流失用户吗?
- 用户目前可以操作网站的关键功能吗?例如在电商网站里为订单付款,添加购物车等。
- 目前存在较高的延迟致使用户不能正常使用我们的服务吗?
Netflix使用客户点击视频流设备上播放按钮的速率作为指标,称为“视频每秒开始播放数(SPS)”,在文末会有相关介绍。
如果你还不能直接获取和业务直接相关的指标,可以暂时先利用一些系统指标,比如系统吞吐率,错误率,pct99延迟等。你选择的指标和业务关系越强,得到的可以采取可执行策略就越强。同样重要的是,在客户端验证服务产生的告警可以提高整体效率,而且可以作为对服务端指标的补充,以构成某一时刻用户体验的完整画面。
定义好指标并理解其稳定状态的行为之后,你就可以使用它们来建立对实验的假设。思考一下当你向系统注入不同类型的事件时,稳定状态行为会发生什么变化。例如,你向某个服务增加请求数,其稳定状态是被破坏还是保持不变?如果被破坏了,你所期待系统该如何表现?
我们的假设可以是实验措施不会使系统行为偏离稳定状态,比如:向我们的系统中注入的事件不会导致系统稳定状态发生明显的变化。
最后我们还需要思考一下这个问题:如何衡量稳定状态行为的变化。即便你已经建立了稳定状态行为模型,你也需要定义清楚,当偏离稳定状态行为发生时你要如何测量这个偏差。只有定义清楚“正常”的偏差范围,才可以获得一套验证假设的完善的测试集。
2. 多样化真实世界的事件 (Vary Real-world Events)
每个系统,从简单到复杂,只要运行时间足够长,都会受到不可预测的事件和条件的影响。例如负载的增加、硬件故障、软件缺陷、还有非法数据(有时称为脏数据)的引入。
我们无法穷举所有可能的事件或条件,但常见的有以下几类:
- 硬件故障;
- 功能缺陷;
- 状态转换异常(例如发送方和接收方的状态不一致);
- 网络延迟或隔离;
- 上行或下行输入的大幅波动以及重试风暴;
- 资源耗尽;
- 服务之间的不正常的或者预料之外的组合调用;
- 拜占庭故障;
- 资源竞争条件;
- 下游依赖故障。
也许最复杂的情况是上述事件的各类组合导致系统发生异常行为。
要彻底阻止对可用性的各种威胁是不可能的,但是我们可以尽可能减轻这些威胁。**在决定引入哪些事件时,我们应当估算这些事件发生的频率和影响范围,然后权衡引入他们的成本和复杂度。**我们不需要穷举所有可能对系统造成改变的事件,只需要注入那些频繁发生且影响重大的事件,同时要足够理解会被影响的故障域(故障的影响范围和隔离范围被称为故障的故障域)。
3. 在生产环境中运行实验 (Run Experiments in Production)
根据环境与流量模式的不同,系统运行效果亦将受到影响。由于运行效果可能随时改变,因此我们应将对实际流量进行采样作为获取可靠请求路径的惟一方法。为了保证系统运行方式的真实性以及同现有部署系统间的关联性,混沌工程原则强烈建议您直接面向生产流量进行实验。
即便你不能在生产环境中执行实验,你也要尽可能的在离生产环境最接近的环境中运行。越接近生产环境,对实验外部有效性的威胁就越少,对实验结果的信心就越足。
4. 持续自动化运行实验 (Automate Experiments to Run Continuously)
当今的系统越来越复杂,这意味着我们无法预先地知道生产环境的哪些变动会改变混沌工程实验的结果。基于这个原因,我们必须假设所有变动都会改变实验结果。在共享状态、缓存、动态配置管理、持续交付、自动伸缩、时间敏感的代码等等的作用之下,生产环境实际上处在一个无时不在变化的状态。
最开始执行混沌实验,可能就是手动执行,但是实验的手动运行工作属于劳动力密集型任务,因此难以长久持续。相反的,我们应该自己投入精力来开发混沌工程的工具和平台,以期不断降低创建新实验的门槛,并能够完全自动运行这些实验。
5. 最小化爆炸半径 (Minimize Blast Radius)
混沌实验通过很多方法来探寻故障会造成的未知的、不可预见的影响,关键在于如何让这些薄弱环节曝光出来而不会意外造成更大规模的故障。我们称之为最小化“爆炸半径”。
当我执行混沌实验时,一般先只作用于很少的用户之上,这样的风险也最小,他们不能代表全部生产流量,但他们是很好的早期指标。当自动化实验成功之后,就需要扩大实验范围:运行小规模的扩散实验,再进行小规模的集中实验,最后就是大规模无自定义路由的实验。扩大实验范围的目的是进一步暴露小范围实验无法发现的一些问题。
除了不断扩大实验范围,在实验造成过多危害时及时终止实验也是必不可少的。有些系统设计会使用降级模式来给用户带来稍小的影响,这还好,但是当系统完全中断服务的时候,就应该立即终止实验。(本文来自公众号:朱小厮的博客,ID: hiddenkafka)
我们也会经常运行本来只会影响一小部分用户的测试,却由于级联故障无意中影响到了更多的用户。在这些情况下,我们不得不立即中断实验。虽然我们绝不想发生这种情况,但随时遏制和停止实验的能力是必备的,可以避免造成更大的危机。
为了让尽可能高效地应对实验发生不可预期的情况,我们要避免在高风险的时间段运行实验。例如我们只在所有人都在办公室工作的时间段运行实验。
三、混沌成熟度模型(Chaos Maturity Model)
标准化混沌工程定义的一个目的是,在执行混沌工程项目时,我们有标准来判断这个项目做得是好是坏,以及如何可以做得更好。混沌工程成熟度模型(CMM)给我们提供了一个评估当前混沌工程项目成熟度状态的工具。把你当前项目的状态放在这个图上,就可以据此设定想要达到的目标,也可以对比其他项目的状态。
CMM 的两个坐标轴分别是“熟练度(Sophistication)”和“接纳度(Adoption)”。缺乏熟练度时,实验会比较危险、不可靠、且有可能是无效的。缺乏接纳度时,所做的实验就不会有什么意义和影响。要在适当的时候变换在两个不同维度的投入,因为在任何一个时期,要发挥混沌工程项目的最大效果需要在这两个维度上保持一定的平衡。
1.混沌工程实验熟练度等级
熟练度可以反映出,在你的组织中混沌工程项目的有效性和安全性。项目各自的特性会反映出不同程度的熟练度,有些完全不具备熟练度,而有些可能具备很高的熟练度。
| 熟练度等级 | 1级 | 2级 | 3级 | 4级 | 5级 |
|---|---|---|---|---|---|
| 架构抵御故障的能力 | 无抵御故障的能力 | 一定的冗余性 | 冗余且可扩展 | 已使用可避免级联故障的技术 | 已实现韧性架构 |
| 实验指标设计 | 无系统指标监控 | 实验结果只反映系统状态的指标 | 实验结果反映应用的健康状况指标 | 实验结果反映聚合的业务指标 | 可在实验组和可控组之间比较业务指标的差异 |
| 实验环境 | 选择只敢在开发和测试环境中运行实验 | 可在预生产环境中运行实验 | 未在生产环境中,用复制的流量来运行实验 | 在生产环境中运行实验 | 包括生产在内的任意环境都可以运行实验 |
| 实验自动化能力 | 全人工流程 | 利用工具进行半自动运行实验 | 自动式创建实验,自动运行实验,但需要手动监控和停止实验 | 自动结果分析,自动终止实验 | 全自动的设计、执行和终止实验实验 |
| 工具使用 | 无实验工具 | 采用实验工具 | 使用实验框架 | 实验框架和持续发布工具集成 | 工具支持交互式的比对实验组和控制组 |
| 故障注入场景,爆炸半径范围 | 只对实验对象注入一些简单事件,如突发高CPU高内存等 | 可对实验对象进行一些较复杂的故障注入,如实例终止、高可用故障等等 | 对实验对象注入较高级的事件,如网络延迟 | 对实验组引入如服务级别的影响和组合式的故障时间 | 可注入如对系统的不同使用模式、返回结果和状态的更改等类型的事件 |
| 环境恢复能力 | 无法恢复正常环境 | 可手动恢复环境 | 可半自动名恢复环境 | 部分可自动恢复环境 | 韧性架构自动恢复 |
| 实验结果整理 | 没有生成的实验结果,需要人工整理判断 | 可通过实验工具得到实验结果,需要人工整理、分析和解读 | 可通过实验工具持续收集实验结果,但需要人工分析和解读 | 可通过实验工具持续收集实验结果和报告,并完成简单的故障分析 | 实验结果可预测收入损失、容量规划、区分出不同服务实际的关键程度。 |
可以基于实验成熟度等级的8个方面进行混沌实验可行性评估。
2. 混沌工程实验接纳度等级
接纳度用来衡量混沌工程实验覆盖的广度和深度。接纳度越高,暴露的脆弱点就越多,你对系统的信心也就越足。
| 接纳度等级 | 描述 |
|---|---|
| 1级 | 公司重点项目不会进行混沌工程实验;只覆盖了少量的系统;公司内部基本上对混沌工程实验了解甚少;极少数工程师尝试且偶尔进行混沌工程实验 |
| 2级 | 混沌工程实验获得正式授权和批准;由工程师兼职进行混沌工程实验;公司内部有多个项目有兴趣参与混沌工程实验;极少数重要系统会不定期进行混沌工程实验 |
| 3级 | 成立了专门的混沌工程团队;事件响应已经集成在混沌工程实验框架中以创建对应的回归实验;大多数核心系统都会定期进行混沌工程实验;偶尔以Game Day的形式,对实验中发现的故障进行复盘验证 |
| 4级 | 公司所有核心系统都会经常进行混沌工程实验;大多数非核心系统也都会经常进行混沌工程实验;混沌工程实验是工程师日常工作的一部分;所有系统默认都要参与混沌工程实验,不参与需要特殊说明 |
四、混沌工程的目标——韧性架构
“故障是注定的,随着时间的流逝,一切终将归于失败”。我们必须接受故障发生是新常态的想法,处在部分故障的系统正常运行是完全可行的。当我们处理多达几十个服务实例的小型系统时,100%的健康运行通常是正常状态,故障则是一种特殊情况。然而,在处理大规模系统时,即100%的健康运行几乎是不可能实现的。因此,运维的新常态便是接受部分故障。处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力,这里的Resilient即为韧性(具备恢复能力)。
混沌工程就是利用实验提前探知系统风险,通过架构优化和运维模式的改进来解决系统风险,真正实现上述韧性架构,降低企业损失,提高故障免疫力。
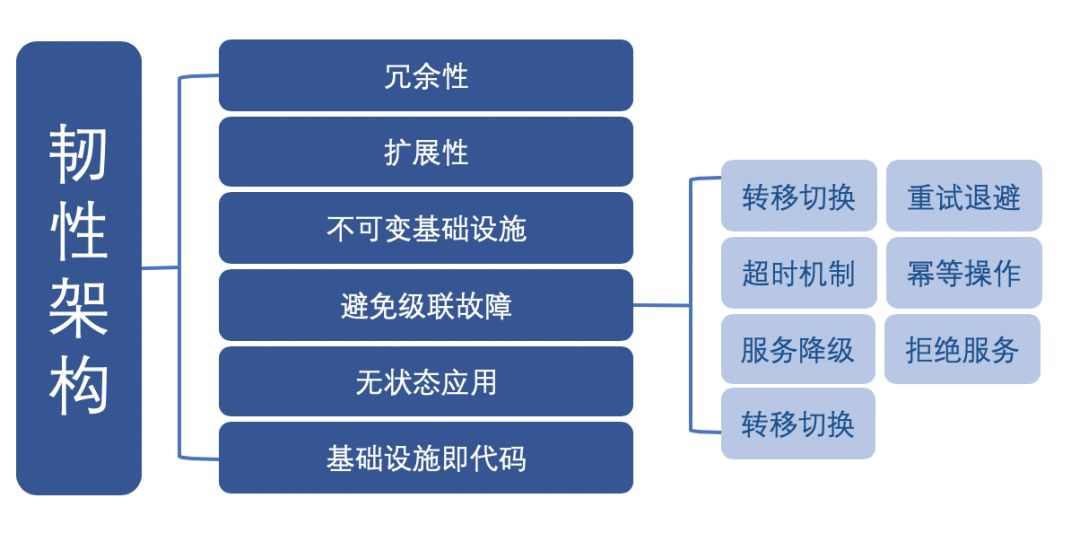
韧性架构的重要特征:
- 冗余性。架构的设计要增加冗余性,以便提高该系统的整体可用性。
- 扩展性。架构的设计必须要考虑扩展性,即启用 Auto Scaling ,根据需求动态扩展资源( 而不是手动执行) ,确保可以满足各种流量模式。
- 不可变基础设施。不可变基础设施指的是,每次部署都会替换相应的组件,不做更新。应用部署则使用金丝雀发布(俗称灰度发布),以减少部署新版本应用时出现故障的风险。使用这种技术,可以在真实的生产环境中进行测试,并在需要时进行快速回滚。
- 避免级联故障。级联故障指的是因依赖关系引发的局部故障导致整个系统崩溃(俗称蝴蝶效应)。架构设计必须考虑级联故障的处理方式:
- 转移切换:当一个集群宕机时,所有的流量都转移到另一个集群,如跨可用区切换,或者跨区域切换。
- 重试退避:指数退避算法逐渐对客户端重试请求减速,避免网络拥塞,同时添加抖动保证性能。
- 超时机制:过载请求会将连接耗尽,导致系统宕机。超时机制的引入,服务的质量会下降但不至于系统全面崩溃。
- 幂等操作:由于暂时的错误,客户端可能多次发送相同的请求,可能导致系统处理错误。幂等操作,一种可以反复重复的操作,没有副作用或应用程序的失败,可以消除上述隐患。
- 服务降级:当服务器压力剧增的情况下,有策略地减少或退化部分服务,以此释放服务器资源以保证核心任务的正常运行,如只读模式、停用耗时耗资源的功能等等。
- 拒绝服务:请求过载时,按优先级开始丢弃相应的请求。
- 服务熔断:若某个目标服务调用过慢或者有大量超时,直接熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回响应,快速释放资源,待目标服务情况好转则恢复调用。
- 无状态应用。无状态应用是自动扩展和不可变基础设施的先决条件,要求应用必须独立于先前的请求或会话,处理所有客户端请求,并且不会存储在本地磁盘或内存中。
- 基础设施即代码。基础设施即代码可减轻繁琐的手工配置和部署任务,由于可用完全相同的方式反复执行,因此解决了随时间推移引发的配置漂移问题,当有故障发生,基础设施的恢复快速且有效。同时可对基础架构以代码的形式进行版本控制,管理其更新、审核、验证和回溯分析。(本文来自公众号:朱小厮的博客,ID: hiddenkafka)
五、混沌工程实践
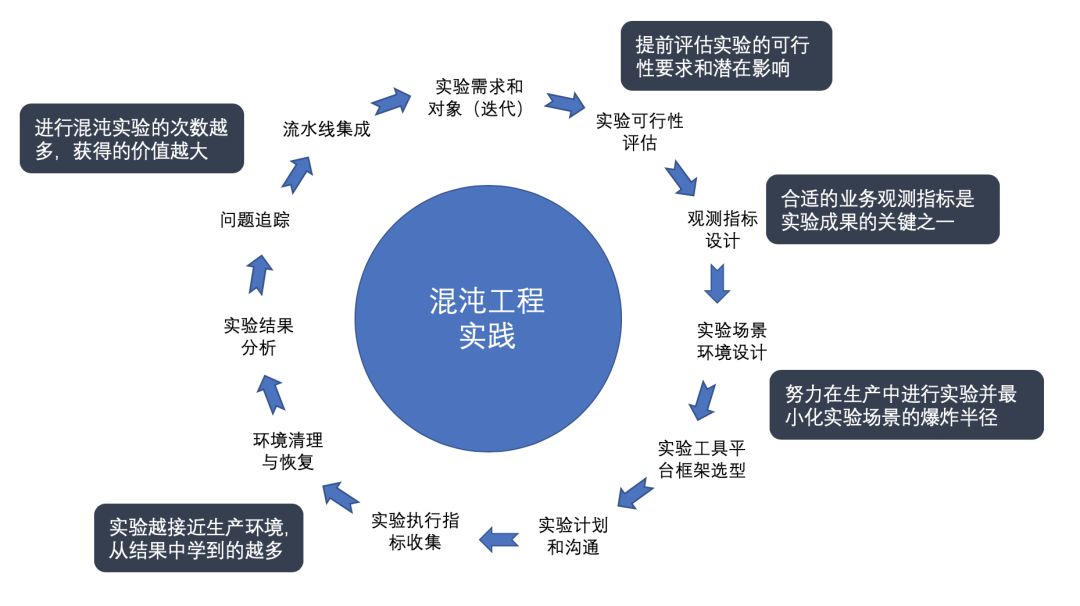
完整的混沌工程实验是一个持续性迭代的闭环体系,大致分为以下几个步骤:
- 确定初步的实验需求和实验对象;
- 通过实验可行性评估,确定实验范围;
- 设计合适的观测指标;
- 设计合适的实验场景和环境;
- 选择合适的实验工具和平台框架;
- 建立实验计划,和实验对象的干系人充分沟通,进而联合执行实验过程;
- 搜集预先设计好的实验指标;
- 待实验完成后,清理和恢复实验环境;
- 对实验结果进行分析;
- 追踪根源并解决问题;
- 将以上实验场景自动化,并入流水线,定期执行;之后,便可开始增加新的实验范围,持续迭代和有序改进。
1. 实验可行性评估
在前面的提及了混沌成熟度模型CMM,从熟练度和接纳度对实验技术的成熟度做了定下分析。此处的实验可行性评估,依照这个可行性评估模型,会针对具体的实验需求和实验对象进行细致评估。常见的一个形式是对照“可行性评估问题表”,对实验对象的干系人进行访谈。可行性评估问题表的内容会包含以下几个方面:
- 架构抵御故障的能力:通过对实验对象的架构高可用性的分析和评估,找出潜在的系统单点风险,确定合理的实验范围。
- 实验指标设计:评估目前实验对象判定业务正常运行所需的业务指标、应用健康状况指标和其他系统指标。
- 实验环境选择:选择实验对象可以应用的实验环境:开发、测试、预生产、生产。
- 实验工具使用:评估目前实验对象对实验工具的熟悉程度。
- 故障注入场景及爆炸半径:讨论和选择可行的故障注入场景,并评估每个场景的爆炸半径。
- 实验自动化能力:衡量目前实验对象的平台自动化实施能力。
- 环境恢复能力:根据选定的故障注入场景,评估实验对象对环境的清理和恢复能力。
- 实验结果整理:根据实验需求,讨论确定实验结果和解读分析报告的内容项。
2. 观测指标设计与对照
观测指标的设计是整个混沌工程实验成功与否的关键之一。在进行混沌工程实验过程中,系统可观测性已成为一种“强制性功能”,良好的系统可观测性会给混沌工程实验带来一个强有力的数据支撑,为后续的实验结果解读、问题追踪和最终解决提供了坚实的基础。
以下是常见混沌工程实验的观测指标类型:
- 业务性指标:价值最大,探测难度最大
- 应用健康指标:反映应用的健康状况
- 其他系统指标:较易获取,反映基础设施和系统的运行状况
指标对照是指将“观测指标”与“指标的稳定状态”进行对照。很多的用户还是无法定义一个合适的业务指标,如无法准确定义一个稳定状态,那么我们也可以退而求其次,使用多个指标进行联合分析来对照。
3. 实验场景和环境的设计
实验场景和环境的设计要努力遵循以下三大设计目标:
- 在生产环境运行实验
- 持续自动化运行实验
- 最小化实验场景的“爆炸半径”
实验场景(故障注入)设计
| 实验场景 | 具体描述 |
|---|---|
| 依赖性故障 | 托管服务异常:ELB/ DNS/ NTP, ... |
| 主机型故障 | 实例异常终止,实例异常关闭,磁盘卷异常卸载, RDS数据库实例故障切换,... |
| 操作系统内故障 | CPU、内存、磁盘空间、IOPS沾满或突发过高占用、大文件、只读系统、系统重启、熵耗散,... |
| 网络故障 | 网络延迟,网络丢包,DNS解析故障,DNS缓存度化,VIP移动,网络黑洞,... |
| 服务层故障 | 不正常关闭连接,进程被杀死,暂停/启动进程,内核崩溃,...请求拦截型故障异常请求,请求处理延迟,... |
实验环境设计
实验环境的不同,带来不同的业务风险。生产环境的业务风险最大,开发环境的业务风险最小,其他依次类推。(本文来自公众号:朱小厮的博客,ID: hiddenkafka)
建议用户在生产环境上进行混沌工程实验,当然前提是这些实验场景和工具已经在开发、测试和预生产环境得到了验证。当然在生产环境上进行混沌工程实验也不是强制的,用户可以选择适合自己的推进节奏,逐步向生产环境靠拢。因为实验越接近生产环境,从结果中学到的越多。同时,为了体现实验对照的效果,在生产环境进行的混沌实验可以通过真实生产流量分支的方式,组建控制组和对照组,以此区分故障注入的影响,从一定程度上控制了爆炸半径。对于非生产环境的混沌工程实验,可采用模拟生产流量的方式,尽量和生产流量相似,来验证实验场景和工具的可靠性。
六、混沌实验工具整理
| 工具名称 | 最新版本 | 项目维护状态 | 主要构建语言 | 涉及场景 | 特定依赖 | 链接地址 |
|---|---|---|---|---|---|---|
| Chaos Monkey | 2.0.2 | 2016.11之后不在功能开发 | Go | 终止EC2实例 | Spinnaker | https://github.com/Netflix/chaosmonkey |
| Simian Army | 2.5.3 | retired | Java | 终止EC2实例;阻断网络流量;卸载磁盘卷;CPU/IO/磁盘空间突发过高;杀进程;路由失败;网络丢包;DynamoDB故障…… | 无 | https://github.com/Netflix/SimianArmy和https://queue.acm.org/detail.cfm?id=2499552 |
| orchestrator | 3.1.1 | alive | Go | 纯MySQL集群故障场景 | 无 | https://github.com/github/orchestrator |
| kube-monkey | 0.3.0 | 只发布了一个正式版本 | Go | 杀K8s Pods | 针对K8s集群 | https://github.com/asobti/kube-monkey |
| chaostoolkit | 1.2.0 | alive | Python | 实验框架,可集成多个IaaS或PaaS平台,可使用多个故障注入工具定制场景,可与多个监控平台合作观测和记录指标信息 | 通过插件形式支持多个IaaS、PaaS,包括AWS/Azure/Google/K8s | https://github.com/chaostoolkit/chaostoolkit |
| PowerfulSeal | 2.2.0 | alive | Python | 杀K8s、Pods,杀容器,杀虚拟机 | 支持OpenStack/AWS/本地机器 | https://github.com/bloomberg/powerfulseal |
| toxiproxy | 2.1.4 | alive | Go | 网络代理,模拟网络故障 | 无 | https://github.com/Shopify/toxiproxy |
| Pumba | 0.6.4 | alive | Go | 杀停删容器;暂停容器内进程;网络延迟;网络丢包;网络带宽限流 | 依赖Docker | https://github.com/alexei-led/pumba |
| blockade | 0.4.0 | 停滞 | Python | 杀容器、网络终端、网络延迟、网络丢包、网络分区 | 依赖Docker | https://github.com/worstcase/blockade |
| chaos-lambda | 0.3.0 | 停滞 | Python | 杀自动伸缩组的EC2示例 | 依赖于Lambda | https://github.com/bbc/chaos-lambda |
| namazu | 0.2.1 | 停滞 | Go | 文件系统故障;网络故障;Java功能调用故障 | 针对类Zookeeper分布式系统 | https://github.com/osrg/namazu |
| chaos-monkey-spring-boot | 2.0.2 | alive | Java | 应用延迟;异常处理;内存过高 | 依赖于Spring Boot框架 | https://github.com/codecentric/chaos-monkey-spring-boot |
| byte-monkey | 1.0.0 | 停滞 | Java | 异常处理;应用延迟 | https://github.com/mrwilson/byte-monkey | |
| chaosblade | 0.4.0 | alive | Java | 实验框架,目前支持JVM | https://github.com/chaosblade-io/chaosblade |
七、混沌工程案例
1. Netflix: SPS
某些组织有非常明确的,和收入直接相关的实时指标。例如像 Amazon 和 eBay 会跟踪销售量,Google 和 Facebook 会跟踪广告曝光次数。由于 Netflix 使用的是按月订阅模式,所以没有这类指标。Netflix也会测量注册率,这是一个重要的指标,但是只看注册率不能反映整体系统的健康状况。
Netflix真正想要的是一个可以反映当前活跃用户的满意状况的指标,因为满意的用户才有可能连续订阅。可以这么说,如果当前和系统做交互的用户是满意的,那么我们基本可以确定系统目前是健康的。
遗憾的是,Netflix目前还没找到一个直接、实时的可以反映用户满意度的指标。Netflix会监控客服电话的呼叫量,这或许是一个可以间接反映客户满意度的指标,但是从运营角度出发,我们需要更快、更细粒度的反馈。Netflix 有一个还不错的可以间接反映用户满意度的指标——播放按钮的点击率。Netflix管这个指标叫做视频每秒开始播放数,简称为 SPS(Starts per sencond)。
SPS 很容易测量,而且因为用户付费订阅服务的直接目的就是看视频,所以 SPS 应该和用户满意度密切相关。这个指标在美国东海岸下午 6 点会明显高于早上 6 点。Netflix就可以据此来定义系统的稳定状态了。
相比某个服务的 CPU 负载来说,Netflix 的可靠性工程师(SREs)更关注 SPS 的下降:SPS 下降会立刻向他们发送告警。CPU 负载的尖刺有时重要有时不重要,而像 SPS 这样的业务指标才是系统边界的表述。这才是需要关注并验证的地方,而不是那些像 CPU 负载类的内部指标。
在 Netflix,SPS 也不是一个和人体体温一样的稳定指标,它也随着时间波动。下图描绘的就是 SPS 随时间变化的波动情况,可以看出,它有一个稳定的模式。这是因为人们习惯于在晚餐时间看电视节目。因为 SPS 随时间的变化可以预期,所以我们就可以用一周前的 SPS 波动图作为稳定状态的模型。Netflix 的可靠性工程师们总是将过去一周的波动图放在当前的波动图之上,以发现差异。就像下图中当前的图线是红色,上一周的图线是黑色。
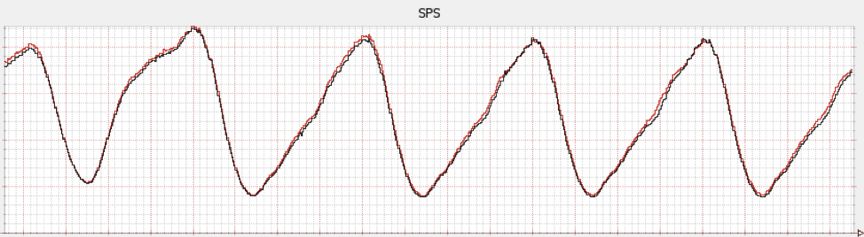
你所处的行业决定了你的指标是否以一种可以预期的方式随时间波动。例如,如果你负责一个新闻网站,流量的尖刺可能来源于一个大众关注度高的新闻事件。某些事件的尖刺可以预期,比如选举、重大赛事,但是其他类型的事件不太可能被预测到。在这一类场景中,准确描述系统的稳定状态将会非常复杂。无论哪种情况,描述稳定状态都是建立有意义假设的必要前提。
2. 阿里巴巴ChaosBlade
2012 年阿里内部就上线了 EOS 项目,用于梳理分布式服务强弱依赖问题,同年进行了同城容灾的断网演练。15 年 实现异地多活,16 年内部推出故障演练平台 MonkeyKing,开始在线上环境实施混沌实验,然后 18 年输出了 ACP 专有云产品 和 AHAS 公有云产品,其中 AHAS 旨在将阿里的高可用架构经验以产品的形式对外输出,服务于外部。19 年推出 ChaosBlade 项目,将底层的故障注入能力对外开源,同年也推出混沌实验平台专有云版本 AHAS Chaos。
ChaosBlade 中文名混沌之刃,是一款混沌实验实施工具,支持丰富的实验场景,比如应用、容器、基础资源等。工具使用简单,扩展方便,其遵循社区提出的混沌实验模型。具体可以参考:阿里巴巴混沌测试工具ChaosBlade两万字解读。
参考资料
- Principles of Chaos Engineering
- Chaos Engineering: the history, principles, and practice
- Chaos Engineering White Paper —— Chaos Engineering: Breaking Your Systems for Fun and Profit
- Simian Army —— The Antifragile Organization, Embracing Failure to Improve Resilience and Maximize Availability
- The Netflix Simian Army
参考书籍
- 《Chaos Engineering ——Building Confidence in System Behavior through Experiments 》

想知道更多?扫描下面的二维码关注我

【混沌工程系列文章】
- 科普 | 明星公司之Netflix
- 看我如何作死 | 将CPU、IO打爆
- 看我如何作死 | 网络延迟、网络丢包、网络中断一个都没落下过
- 混沌系列 | 其实制造“假死”很容易
- 干货 | 这次我们看看阿里的人是如何蹂躏CPU的
- 阿里巴巴混沌测试工具ChaosBlade两万字解读