“orderby”是怎么工作的
假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前1000个人的姓名、年龄。
假设这个表的部分定义是这样的:
`CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;`
这时,你的SQL语句可以这么写:
`select city,name,age from t where city='杭州' order by name limit 1000 ;`
那么它的具体流程是怎么样的?以下将介绍order by的具体流程
全字段排序
通常情况下,这个语句执行流程如下所示 :
- 初始化sort_buffer,确定放入name、city、age这三个字段;
- 从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
- 到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中;
- 从索引city取下一个记录的主键id;
- 重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
- 对sort_buffer中的数据按照字段name做快速排序;
- 按照排序结果取前1000行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示:
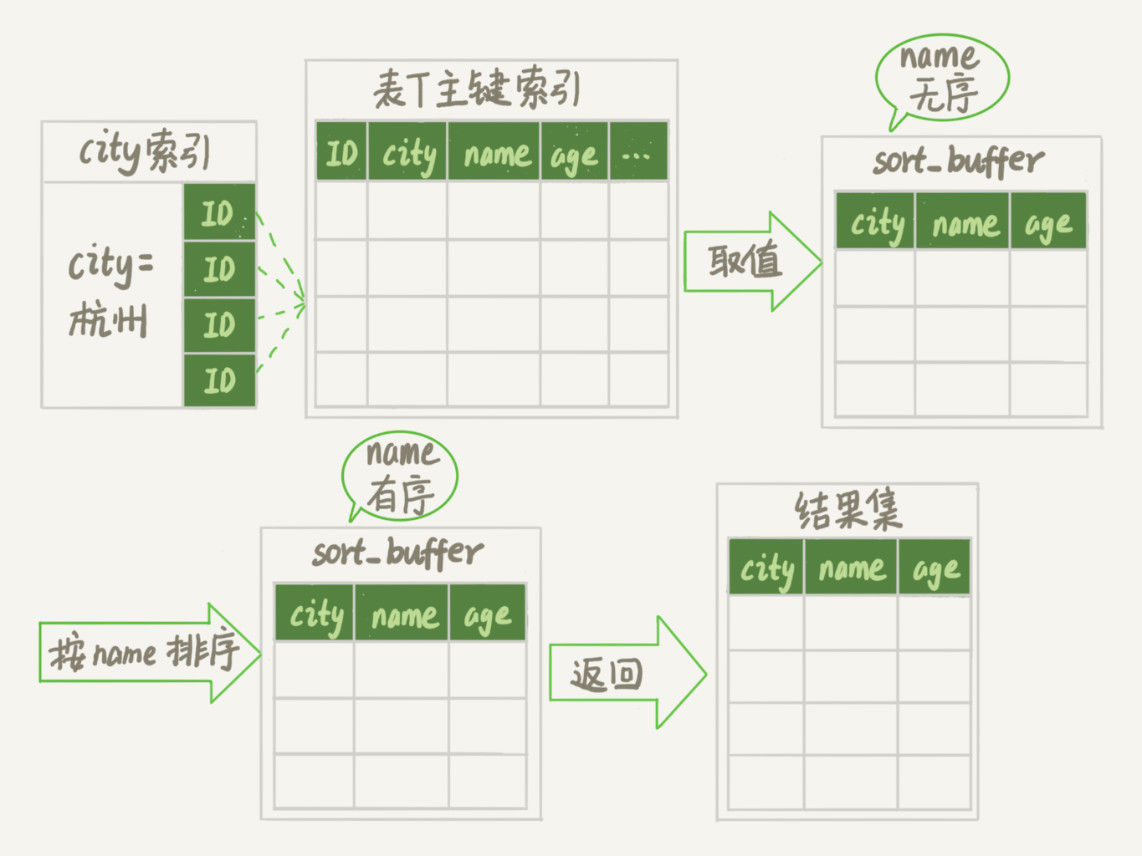
总的来说就一句话:从储存引擎层,获取满足条件的所需数据后,将数据放在内存进行排序后,返回给用户。
rowid排序
全字段排序是在原表的数据读了一遍,放在内存(sort——buffer)中排序后将数据返回给用户。但是如果需要的数据单行字段过大,在增大内存损耗的同时又减低了排序
那么,如果MySQL认为排序的单行长度太大会怎么做呢?
将max_length_for_sort_data设置为16后,流程如下所示:
- 初始化sort_buffer,确定放入两个字段,即name和id;
- 从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
- 到主键id索引取出整行,取name、id这两个字段,存入sort_buffer中;
- 从索引city取下一个记录的主键id;
- 重复步骤3、4直到不满足city='杭州’条件为止,也就是图中的ID_Y;
- 对sort_buffer中的数据按照字段name进行排序;
- 遍历排序结果,取前1000行,并按照id的值回到原表中取出city、name和age三个字段返回给客户端。
我们暂且把这个排序过程,称为roeid排序,执行流程的示意图如下所示:
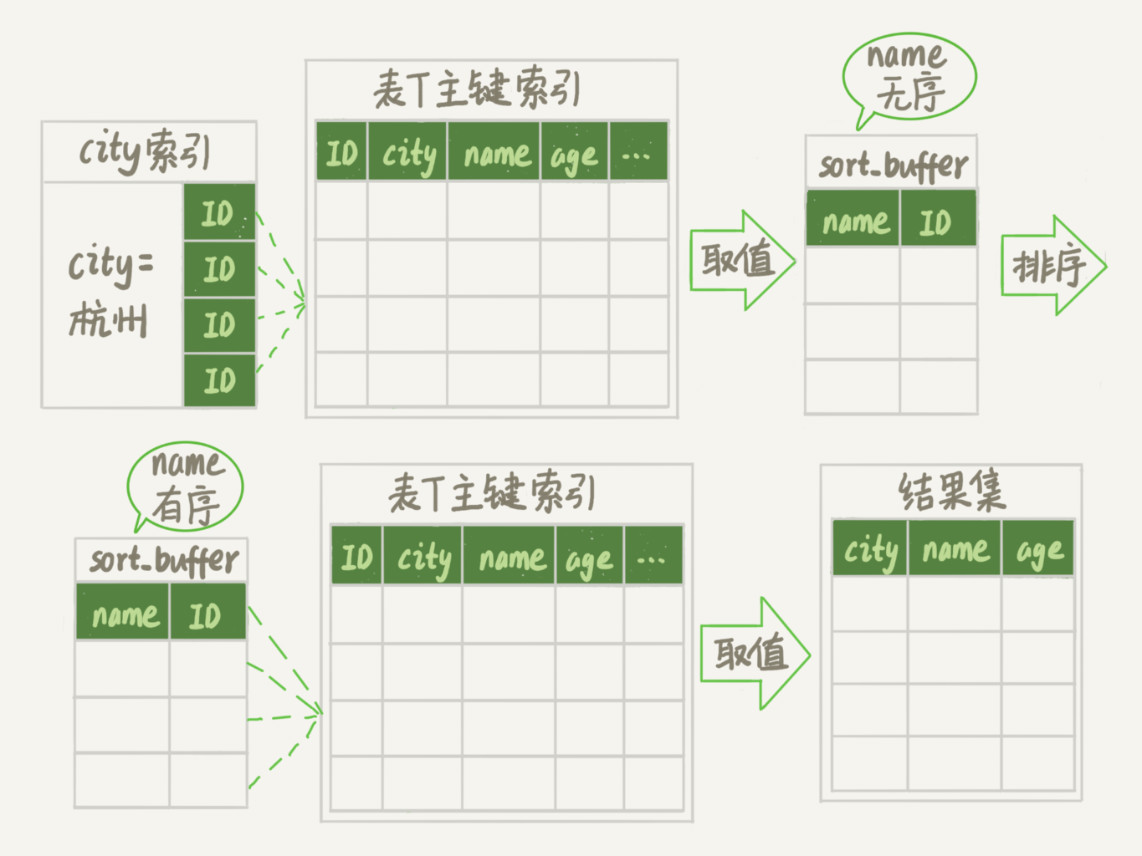
总的来说就一句话:从存储引擎层,获取满足条件的数据后,将数据放在内存中进行排序后,根据主键查询所需要的数据,返回给用户。
全字段排序 VS rowid排序
mysql的核心思想:如果内存够,就要多利用内存,尽量减少磁盘访问
- rowid对比对全字段排序流程图你会发现,rowid排序多访问了一次表t的主键索引。
- 当内存足够时,mysql优先使用全字段排序。
优化:正常是取出来的数据进行排序后,将数据返回给用户,又没有办法使取出来的数据就是有序的?
方法一:使用索引(city,name),这个需要回表操作
方法二:使用索引(city, name, age),覆盖式索引直接返回数据给用户
总结
需要掌握如下:
-
明白orderby的工作机制(全字段排序)
-
如何建立索引
面试题:
8.一个订单表有三种查询(1)按日期查询订单(2)按用户查询订单(3)查询用户一段时间内的订单SQL怎么写?怎么建索引?答曰: id-date; date
9.追问:那date-id; id可不可以?为什么?哪个好?
解答:
暴力解——又(1)(2)(3)建立3个索引:date,id,date-id/id-date
在暴力法下优化——date,id-date(最左原则)
再优化——id,date-id(时间序列式递增的,更好维护)