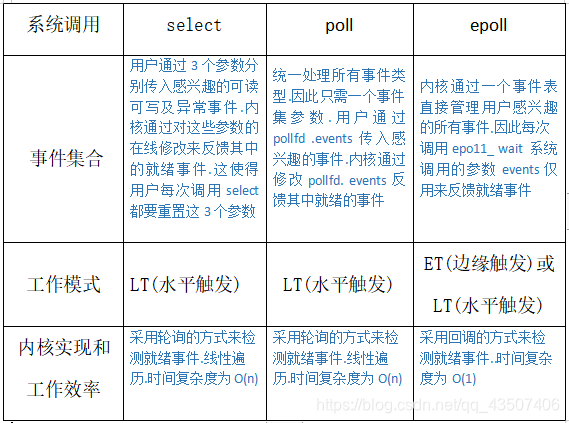
原理:
select
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理.这样所带来的缺点是:
单个进程可监视的fd数量被限制
需要维护一个用来存放大量fd的数据结构.这样会使得用户空间和内核空间在传递该结构时复制开销大
对socket进行扫描时是线性扫描
poll
pol本质上和select没有区别.它将用户传入的数组拷贝到内核空间.然后查询每个fd对应的设备状态.如果设备就绪则在设备等待队列中加入一项并继续遍历.如果遍历完所有fd后没有发现就绪设备.则挂起当前进程.直到设备就绪或者主动超时.被唤醒后它又要再次遍历fd.这个过程经历了多次无谓的遍历
它没有最大连接数的限制.原因是它是基于链表来存储的,但是同样有一个缺点:大量的fd的数组被整体复制于用户态和内核地址空间之间.而不管这样的复制是不是有意义pol还有一个特点是“水平触发”.如果报告了fd后.没有被处理.那么下次poll时会再次报告该fd
epoll
复制问题上.epoll使用mmap减少复制开销.还有一个特点是.epoll使用"事件"的就绪通知方式.通过epoll_ ctl注册fd. 一旦该fd就绪.内核就会采用类似callback的回调机制来激活该fd.epoll_wait便可以收到通知
效率
select
每次调用都会对连接进行线性遍历.所以随着fd增加会造成遍历速度缓慢的问题.
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数
来实现的.只有活跃的socket才会主动调用callback
. 所以在活跃socket较少的情况下.使用epolI没有前
面两者的线性下降的性能问题.