目录:
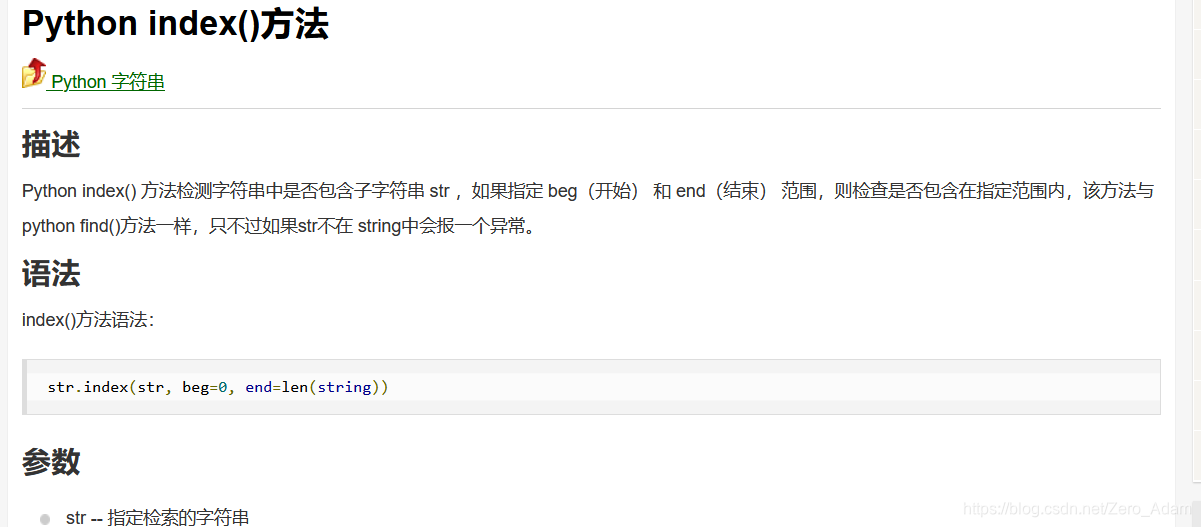
index和 find 一样,只不过,没有找到的话,find函数,会返回 -1
index会报错。
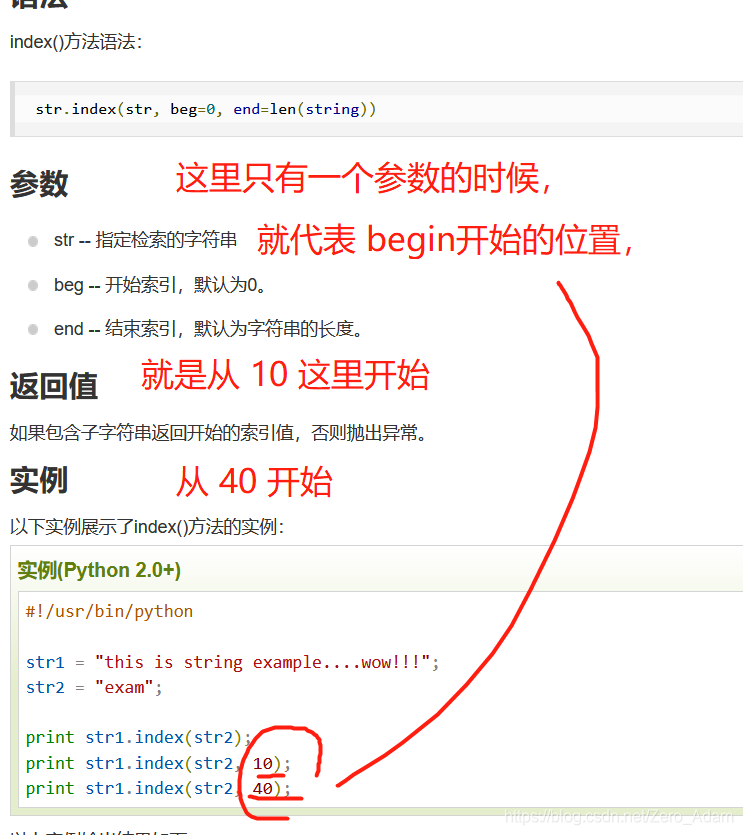

实践
def get_domain(url):
if url.startswith('http://'):
url = url[7:]
if not url.find("/") == -1:
domain = url[url.find("@")+1:url.index("/",url.find("@"))]
else:
domain = url[url.find("@")+1:]
return domain
else:
return False
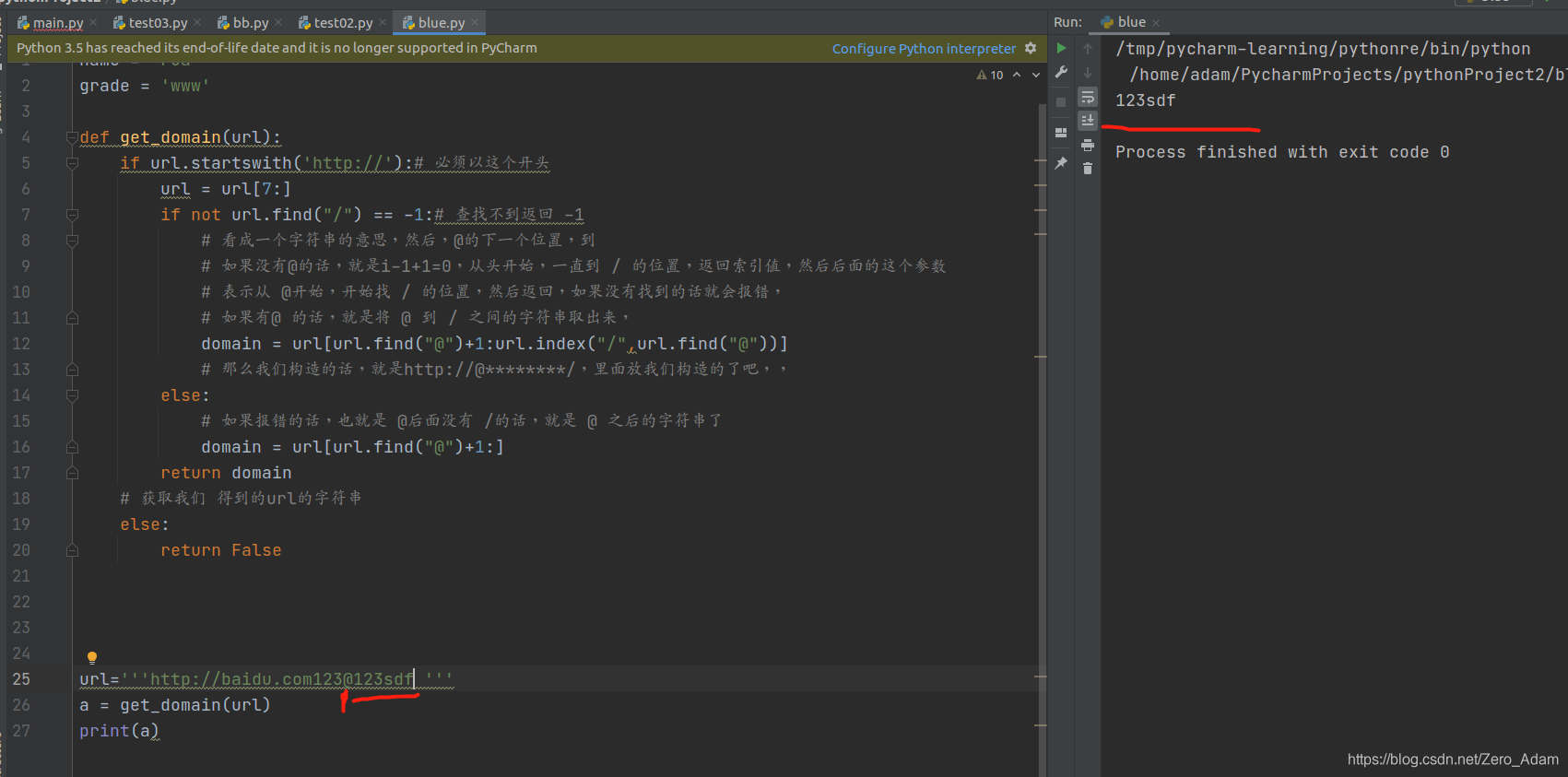
有@ 就从@到最后
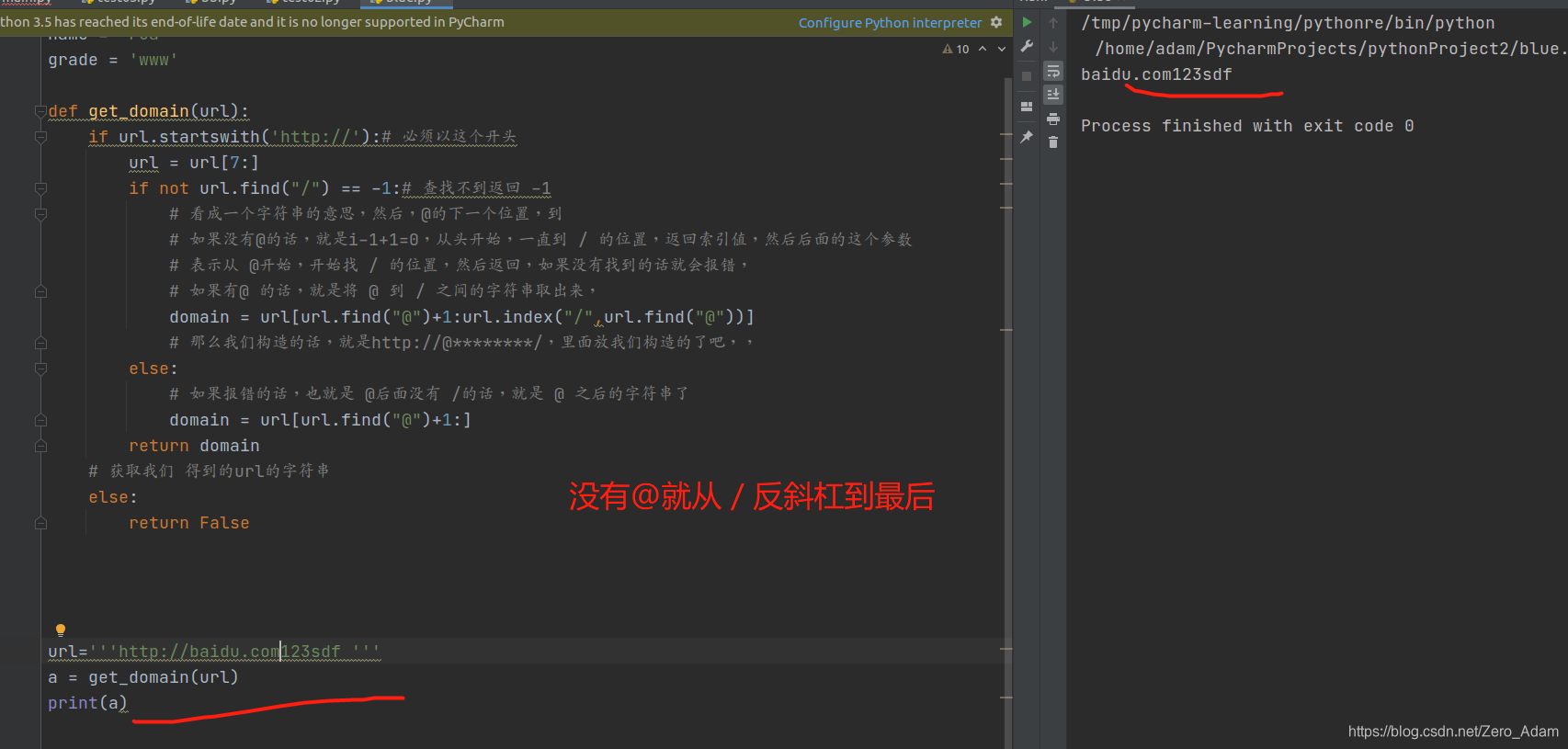
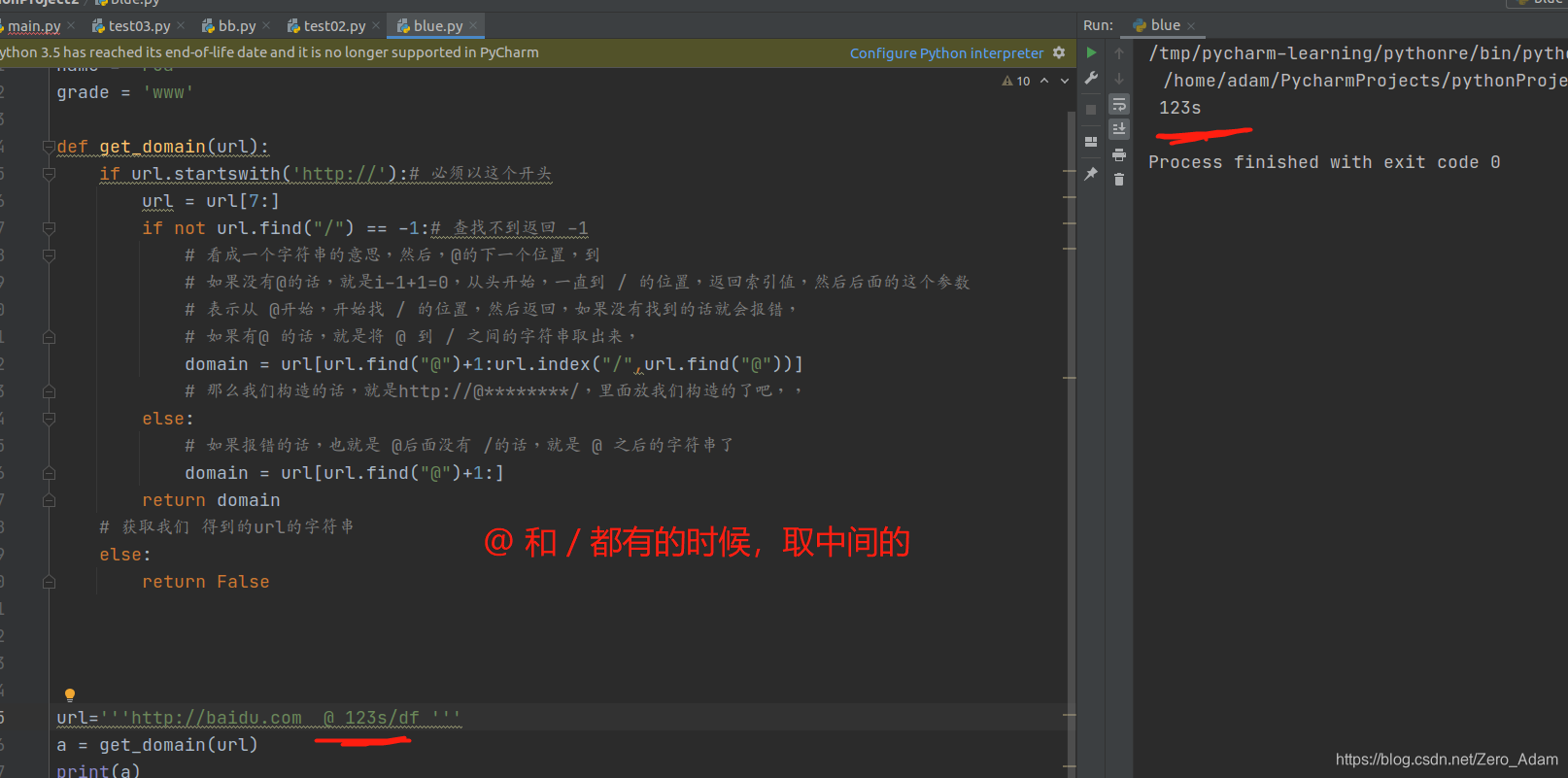 所以get_domain()我i们开头 用http://来绕过,然后把我们的恶意数据放到 @ 和 / 之间就好了,
所以get_domain()我i们开头 用http://来绕过,然后把我们的恶意数据放到 @ 和 / 之间就好了,