OCR,光学字符识别(OPTICAL CHARACTER RECOGNITION),作为计算机视觉领域的经典问题之一
它指对图像中的文字进行检测识别(包括文字检测+文字识别),并获取文本的结果。常见于拍照检查、文档识别、证照票据识别、车牌识别、自然场景下的文本定位识别等,相关技术在数字时代得到了广泛的应用。
如下图是OCR识别结果:
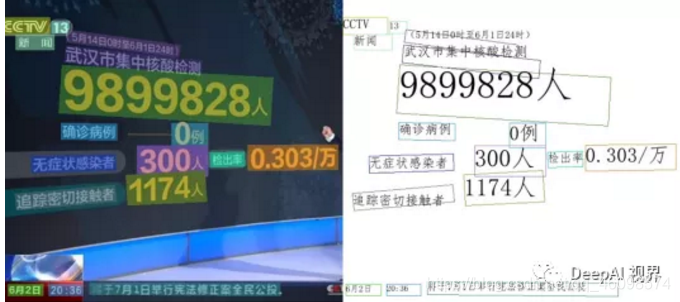
作为计算机视觉领域的OCR识别在训练的时候当然也会需要大量的图片数据来供神经网络的学习,一般需要数以千万计的图片才能训练一个文字识别系统,才能达到识别文字的目的。但是如果采用人工标注会浪费大量的人力财力,导致入不敷出。本文接下来介绍一种能够根据场景生成大量的文字图片的工具。
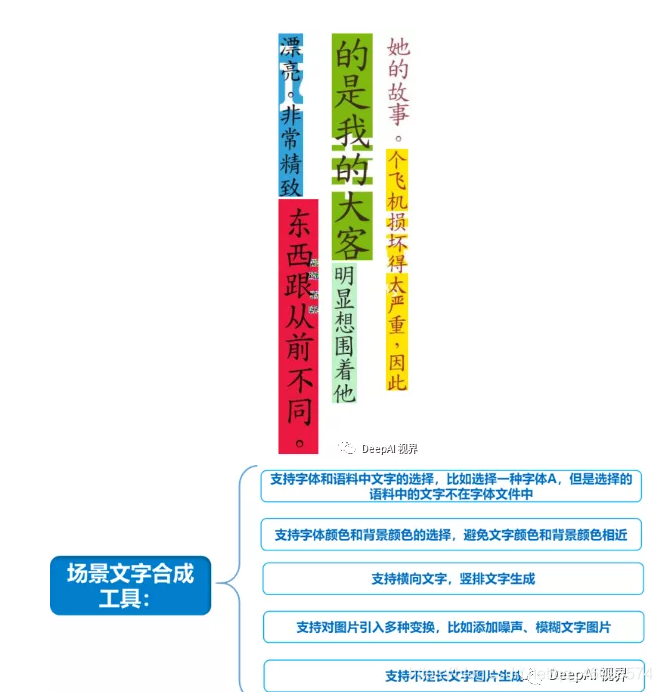
一、总体预览,它主要具有如下功能:
- 生成横、竖排文字。
- 生成彩色图片的文字图。
- 能够选择生成文字的语料。
- 能够生成定长或者不定长的文字图片。
- 对生成的文字图片引入多种变换,比如增加文字的随机倾斜角度,模拟小图放大,大图放小,上下左右运动模糊等功能。


话不多说,先上图展示一波文字合成的效果,如下是生成图片的效果展示:
图片
横排文字:

二、模块解析
场景文字合成工具,它具体包括如下几个模块,字符选择单元,字体选择单元,背景图片选择单元,字体颜色选择单元,以及数据增强单元。
第一, 构建字典文件,首先是要根据自己的场景文字,确定要生成哪些字符到图片上,建立一个生成字符的字典文件。
图片第二, 构建语料文件,由于文字识别一般会采用双向的LSTM来对语料进行学习,这样通过前后文的语义信息提高文字识别的准确率,所以需要一个具有语义信息的语料文件(语料文件需要和场景类似)。
- 获取语料文件以后,需要对语料文件进行字符过滤,过滤掉不在字典文件中的字符。
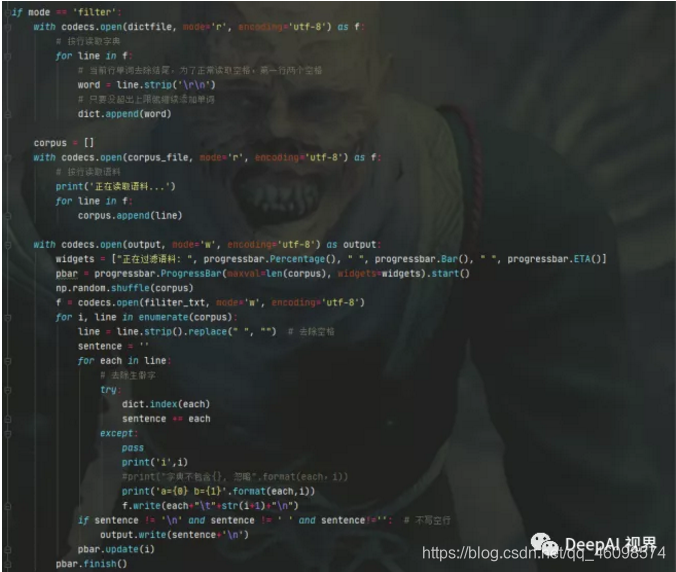
图片2. 语料的切分,经过字符的过滤以后,确保语料中的字符都会出现在字典文件中,接下来就需要进行语料的切分,切分成定长或者是不定长的语料,字符长度一般设置在1-25以内
elif mode == 'split':
corpus = []
with codecs.open(output, mode='r', encoding='utf-8') as f:
# 按行读取语料
print('正在读取语料...')
for line in f:
corpus.append(line)
with codecs.open('split_sentences.txt', mode='w', encoding='utf-8') as output:
widgets = ["正在分行语料: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(corpus), widgets=widgets).start()
for i, line in enumerate(corpus):
row = line
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
# 对大于max_row_len的句子进行分行,直到最后小于max_row_len
while len(row) > max_row_len:
# 长句子分行
# 偶尔出现单字
spliter = np.random.random_integers(1, max_row_len-1)
output.write(row[0:spliter] + '\n')
# if np.random.randint(0, 1000) < 2: # 0.2%的概率加空白行
# output.write('\n')
row = row[spliter:]
#每行会含有一个换行符,去掉换行符
if len(row)>=6:
re_punctuation = "[{}]+".format(punctuation)
row = re.sub(re_punctuation, "", row)
if len(row)>=6:
output.write(row)
pbar.update(i)
pbar.finish()
- 经过字符过滤,语料分割以后生成的语料文件格式如下:
图片
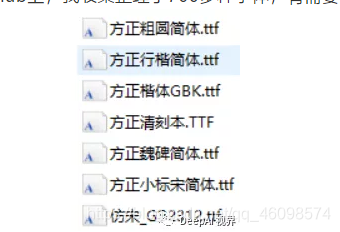
第三, 字体文件的选择,比如你想在图片上生成楷体、宋体或明体等,需要你下载字体文件,当然在我的github上,我收集整理了700多种字体,有需要的可以自行下载。
图片
- 由于每个字体文件所支持的字符种类不一样,如果不加判断的直接使用该字体,如果字典中的字符正好该字体不支持的字符,那么生成的图片上就不会显示该字符,出现乱码或者是空字符的情况,在本代码中采用了加了判断,会防止以上情况的发生,具体可以详细的精度代码。
- 如下是代码中的对每个加载的字体文件支持的字符进行显示,

第四, 图片背景的选择,此时仍然需要你根据自己的场景来收集背景图片,将其存入文件夹中,比如你做的是车牌识别,那么你的背景图片基本就是蓝色、绿色等,你只需要收集这和这类背景图相似的放入文件夹即可。

第五, 字体颜色的生成,你可以设置生成文字的字体颜色,假设你的场景中的文字只有白色,那么你只需要设置成白色字体即可,当然如果你的场景是自然场景,什么样子的字体颜色都有,这个时候就需要使用本文提出的算法来解决这类问题,防止字体的颜色和背景的颜色相近,导致生成的图片无用情况。
- 本代码对字体颜色的选择采用了kmeans聚类的方法,首先对背景进行设置聚类中心,加载彩色图片的字体颜色库,该颜色库包含9882中字体颜色,计算每个聚类中心和当前所选取颜色距离的标准差之和,随机选择颜色距离的标准差较大的100种颜色作为字体的颜色,可以有效防止了背景颜色和字体颜色相近的情况。
第六,如下图是根据以上各个模块生成的文字图片。

最后附上Github 源码:
https://github.com/zcswdt/Color_OCR_image_generator
这么好的东西,记得star哦~
有任何疑问,欢迎下方公众号联系我~(公众号有大量好文和百份AI数据哦)

最全的深度学习数据分享、最前沿的AI科技分享、深度学习技术交流群、计算机视觉与自然语言处理方向实战项目与源码分享~
附赠我的csdn,欢迎来看实战文~
https://blog.csdn.net/qq_46098574