文章转载请注明出处,加上原文地址链接,谢谢!
https://blog.csdn.net/weixin_46959681/article/details/105739995
文章目录
前言
该篇文章以非齐次线性方程组例题引出增广矩阵(A,b)的解集,配合矩阵的QR分解对增广矩阵(A,b)重新构造。在转置方面从代数的角度切入,但这个角度比较浅显。我们需要真正明白的是转置在向量空间层面发挥了什么作用。重要提醒,在阅读该文章之前,必须将MIT线性代数习题公开课第11题的习题观看完毕并消化理解,这是串联所有知识点的脉络,其余只是模块组成。
增广矩阵(Augmented matrix)
e.g. 求出非齐次方程组的通解
{ x 1 + 2 x 2 = 3 2 x 1 + 4 x 2 = 6 \left\{\begin{array}{c}x_1+2x_2=3\\2x_1+4x_2=6\\ \end{array}\right. { x1+2x2=32x1+4x2=6
解: 特解
X ∗ = ( 1 1 ) X^*=\begin{pmatrix}1\\1\\ \end{pmatrix} X∗=(11)
零解
N ( A ) = { c ( − 2 1 ) ∣ c ∈ R } N(A)=\lbrace c\begin{pmatrix}-2\\1\\ \end{pmatrix} |c\in R\rbrace N(A)={ c(−21)∣c∈R}
故原方程组解集为
S ( A , b ) = { ( 1 1 ) + c ( − 2 1 ) ∣ c ∈ R } S(A,b)=\lbrace \begin{pmatrix}1\\1\\\end{pmatrix}+c\begin{pmatrix}-2\\1\\\end{pmatrix}|c \in R \rbrace S(A,b)={
(11)+c(−21)∣c∈R}
可以看出任意解都可以被分解成特解和零解。
那么对于线性方程组 x 1 a 1 + ⋯ + x n a n = β x_1a_1+\cdots+x_na_n=\beta x1a1+⋯+xnan=β有解到底意味着什么呢?结合本人第二篇博文,我们对于方程式
x 1 a 1 + ⋯ + x n a n = β x_1a_1+\cdots+x_na_n=\beta x1a1+⋯+xnan=β
有解可以获得以下结论:
- β ∈ ( a 1 , a 2 , … , a n ) \beta\in(a_1,a_2,\dots,a_n) β∈(a1,a2,…,an)
- ( a 1 , a 2 , … , a n , β ) ⊆ ( a 1 , a 2 , … , a n ) (a_1,a_2,\ldots,a_n,\beta) \subseteq (a_1,a_2,\ldots,a_n) (a1,a2,…,an,β)⊆(a1,a2,…,an)
- ( a 1 , a 2 , … , a n , β ) = ( a 1 , a 2 , … , a n ) (a_1,a_2,\ldots,a_n,\beta)=(a_1,a_2,\ldots,a_n) (a1,a2,…,an,β)=(a1,a2,…,an)
- d i m ( a 1 , a 2 , … , a n , β ) = d i m ( a 1 , a 2 , … , a n ) dim(a_1,a_2,\ldots,a_n,\beta)=dim(a_1,a_2,\ldots,a_n) dim(a1,a2,…,an,β)=dim(a1,a2,…,an)
- r a n k ( a 1 , a 2 , … , a n , β ) = r a n k ( a 1 , a 2 , … , a n ) rank(a_1,a_2,\ldots,a_n,\beta)=rank(a_1,a_2,\ldots,a_n) rank(a1,a2,…,an,β)=rank(a1,a2,…,an)
(以上几条结论可互相推导。)
对于增广矩阵,有以下结构图:
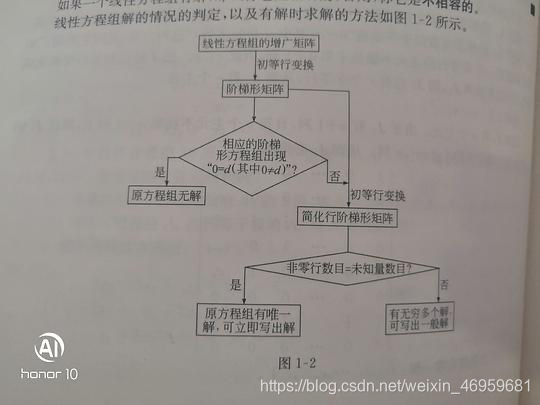
(高等代数学习指导书(第二版上册)第14页)
|从QR分解的角度重构增广矩阵
首先我们来看一下什么是QR分解。
定理 如果 m × n \mathsf{m \times n} m×n 矩阵 A \mathsf{A} A 的列线性无关,那么A可以分解为 A = Q R A=QR A=QR,其中 Q Q Q是一个 m × n m \times n m×n矩阵,其列形成 C o l A Col A ColA的一个标准正交基,R是一个 n × n n \times n n×n上三角矩阵且在对角线上的元素为正数。若Q是一个方阵,则 Q − 1 = Q T Q^{-1}=Q^T Q−1=QT,Q为正交阵。令 Q = ( q 1 , … , q n ) Q=(q_1,\ldots,q_n) Q=(q1,…,qn),故
Q T Q = ( q 1 T ⋮ q n T ) ( q 1 … q n ) = ( 1 0 ⋯ 0 0 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 ) n × n = I n Q^TQ= \begin{pmatrix} q_1^T\\ \vdots\\ q_n^T\\ \end{pmatrix} \begin{pmatrix} q_1&\ldots&q_n\\ \end{pmatrix}=\begin{pmatrix} {1}&{0}&{\cdots}&0\\ {0}&{1}&{\cdots}&0\\ {\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {0}&{0}&{\cdots}&{1}\\ \end{pmatrix}_{n \times n}=I_n QTQ=⎝⎜⎛q1T⋮qnT⎠⎟⎞(q1…qn)=⎝⎜⎜⎜⎛10⋮001⋮0⋯⋯⋱⋯00⋮1⎠⎟⎟⎟⎞n×n=In
应用方面:
- 设 A 为 m × n m \times n m×n 阶矩阵,A 的列向量线性无关, A = Q R A=QR A=QR。 A x = b ⇔ A T A x ^ = A T b ⇔ R T Q T Q R x ^ = R T Q T b ⇔ R T R x ^ = R T Q T b ⇔ R x ^ = Q T b ⇔ x ^ = R − 1 Q T b Ax=b \Leftrightarrow A^TA\hat{x}=A^Tb \Leftrightarrow R^TQ^TQR\hat{x}=R^TQ^Tb \Leftrightarrow R^TR\hat{x}=R^TQ^Tb \Leftrightarrow R\hat{x}=Q^Tb \Leftrightarrow \hat{x}=R^{-1}Q^Tb Ax=b⇔ATAx^=ATb⇔RTQTQRx^=RTQTb⇔RTRx^=RTQTb⇔Rx^=QTb⇔x^=R−1QTb。其中,若 A A A的列相互正交, A = ( a 1 , … , a n ) A=(a_1,\ldots,a_n) A=(a1,…,an),则 R = d i a g ( ∥ a 1 ∥ , … , ∥ a n ∥ ) → x ^ = R − 1 A T b R=diag(\parallel a_1 \parallel , \ldots , \parallel a_n \parallel )\rightarrow\hat{x}=R^ {-1}A^Tb R=diag(∥a1∥,…,∥an∥)→x^=R−1ATb。设 A x = b Ax=b Ax=b无解,则 b b b在 C ( A ) C(A) C(A)上的投影为
P = ∑ i = 1 n ( a i T b a i T a i ) a i \mathsf{\color{red}P=\displaystyle\sum_{i=1}^n(\frac{a_i^Tb}{a_i^Ta_i})a_i} P=i=1∑n(aiTaiaiTb)ai
- A A A是可逆矩阵,则QR分解唯一。
- 设 A m × n A_{m \times n} Am×n列满秩,有 A = Q R , b ∉ C ( A ) A=QR,b \notin C(A) A=QR,b∈/C(A),设其投影在 C ( A ) C(A) C(A)为 P , e = b − p P,e=b-p P,e=b−p,则 ( A , b ) (A,b) (A,b)为列满秩,其QR分解为 ( A , b ) = ( Q , e ∥ e ∥ ) ( R α 0 ∥ e ∥ ) , α = Q T b \mathsf{\color{red}(A,b)=(Q,\frac{e}{\parallel e \parallel})\begin{pmatrix} R &\alpha \\ 0& \parallel e \parallel\\ \end{pmatrix},\alpha=Q^Tb} (A,b)=(Q,∥e∥e)(R0α∥e∥),α=QTb, A = ( a 1 , … , a n ) ∼ Q = ( q 1 , … , q n ) \mathsf{A=(a_1,\ldots,a_n) \sim Q=(q_1,\dots,q_n)} A=(a1,…,an)∼Q=(q1,…,qn)
上述从基的角度细细的梳理了QR分解,请多看几遍并配合相关题目理解。
转置(Transpose)
定义 设A为 m × n \mathsf{m \times n} m×n阶矩阵,第 i i i行 j j j 列的元素是 a ( i , j ) \mathsf{a(i,j)} a(i,j),即: A = ( a i j ) m × n A=(a_{ij})_{m \times n} A=(aij)m×n,把 m × n m \times n m×n矩阵A的行换成同序数的列得到一个 n × m \mathsf{n \times m} n×m矩阵,此矩阵叫做A的转置矩阵,记做 A T = ( a j i ) n × m \mathsf{A^T=(a_{ji})_{n \times m}} AT=(aji)n×m。
代数式表达: A = ( a i j ) m × n < f : T > A T = ( a j i ) n × m \mathsf{A=(a_{ij})_{m\times n}<f:T>A^T=(a_{ji})_{n \times m}} A=(aij)m×n<f:T>AT=(aji)n×m
绝大多数人运算的时候也只是在计算稿上将矩阵沿主对角线进行翻转,如 A = ( 1 2 − 2 1 ) A=\begin{pmatrix}1&2\\-2&1\\\end{pmatrix} A=(1−221)转置有 A T = ( 1 − 2 2 1 ) A^T=\begin{pmatrix}1&-2\\2&1\\\end{pmatrix} AT=(12−21)。我们再从代数层面深入一点,来看下面两个运算。
e.g. A ∈ F m × n A \in F^{m \times n} A∈Fm×n, X ∈ F n × 1 X\in F^{n\times 1} X∈Fn×1, B ∈ F n × p B\in F^{n\times p} B∈Fn×p,则
( A x ) T = ( x 1 A 1 + ⋯ + x n A n ) T = x 1 A 1 T + ⋯ + x n A n T = ( x 1 x 2 ⋯ x n ) ( A 1 T A 2 T ⋮ A n T ) = x T A T (Ax)^T=(x_1A_1+\cdots+x_nA_n)^T=x_1A_1^T+\cdots+x_nA_n^T=\begin{pmatrix}x_1&x_2&\cdots&x_n\\\end{pmatrix}\begin{pmatrix}A_1^T\\A_2^T\\\vdots\\A_n^T\\\end{pmatrix}=x^TA^T (Ax)T=(x1A1+⋯+xnAn)T=x1A1T+⋯+xnAnT=(x1x2⋯xn)⎝⎜⎜⎜⎛A1TA2T⋮AnT⎠⎟⎟⎟⎞=xTAT (数 x x x转置仍然为 x x x。)
e.g. ( A B ) T = ( A B 1 , A B 2 , ⋯ , A B P ) T = ( ( A B 1 ) T ⋮ ( A B p ) T ) = ( B 1 A T ⋮ B p T A T ) = ( B 1 T ⋮ B p T ) A T = B T A T (AB)^T=(AB_1,AB_2,\cdots,AB_P)^T=\begin{pmatrix}(AB_1)^T\\\vdots\\(AB_p)^T\\\end{pmatrix}=\begin{pmatrix}B_1A^T\\\vdots\\B_p^TA^T\\\end{pmatrix}=\begin{pmatrix}B_1^T\\\vdots\\B_p^T\\\end{pmatrix}A^T=B^TA^T (AB)T=(AB1,AB2,⋯,ABP)T=⎝⎜⎛(AB1)T⋮(ABp)T⎠⎟⎞=⎝⎜⎛B1AT⋮BpTAT⎠⎟⎞=⎝⎜⎛B1T⋮BpT⎠⎟⎞AT=BTAT
笔者在这里可以肯定,绝大多数人对转置的认知都停留在以上定义层面以及上述的代数运算层面。那转置在几何层面起什么作用呢?容笔者在这埋下一个伏笔,下面我们来快速的过一遍向量子空间。
向量子空间(subspace)

(笔者清华线性代数公开课笔记第一部分第27页)
四个基本子空间的基的代数表达:
- 列空间(Column space) C ( A ) = { y ∈ R m ∣ y = A x , ∃ X ∈ R N } C(A)=\lbrace y\in R^m | y=Ax,\exists X\in R^N\rbrace C(A)={ y∈Rm∣y=Ax,∃X∈RN}
- 左零空间(Left nullspace) N ( A T ) = { x ∈ R m ∣ x T A = 0 } N(A^T)=\lbrace x\in R^m | x^TA=0\rbrace N(AT)={ x∈Rm∣xTA=0}
- 零空间(Nullspace) N ( A ) = { x ∈ R n ∣ A x = 0 } N(A)=\lbrace x\in R^n | Ax=0\rbrace N(A)={ x∈Rn∣Ax=0}
- 行空间(Row space) C ( A T ) = { y ∈ R n ∣ y = A T x , ∃ X ∈ R m } C(A^T)=\lbrace y\in R^n | y=A^Tx, \exists X \in R^m\rbrace C(AT)={ y∈Rn∣y=ATx,∃X∈Rm}
小贴士:在学习的数学的过程你需要很多固定的元认知模块,以便在学习的过程中像搭积木一样随取随用。比如上面四个子空间的代数表达式,心里知道核心图仅是第一步,第二步更重要,将其用数学语言代数化表达出来,这对于任何一个科目的学习都是通用的。类似的还有数乘,加法,乘法等。(如果有个“仓库”随时进行查找,也没有问题。)
以MIT线性代数习题公开课第11题为串联脉络
在开始阅读之前,请确保你已经看完MIT线代习题公开课第11题,而且有了略微的理解。

在计算的过程中,我们已经的得到了四个子空间的基底,下一步我们来看它是如何经过转置产生联系的。(直接上图)
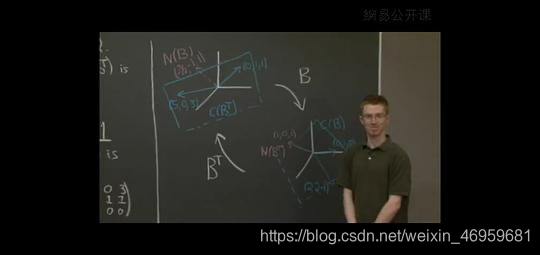
习题公开课视频的讲解非常清晰,行空间(基底 { ( 5 0 3 ) , ( 0 1 1 ) } \lbrace \begin{pmatrix}5\\0\\3\\\end{pmatrix},\begin{pmatrix}0\\1\\1\\\end{pmatrix}\rbrace {
⎝⎛503⎠⎞,⎝⎛011⎠⎞})和零空间(基底 { ( − 3 5 − 1 1 ) } \lbrace \begin{pmatrix}-\frac{3}{5}\\-1\\1\\\end{pmatrix}\rbrace {
⎝⎛−53−11⎠⎞})经过转置被投射到列空间(基底 { ( 1 − 2 1 ) , ( 0 1 0 ) } \lbrace \begin{pmatrix}1\\-2\\1\\\end{pmatrix},\begin{pmatrix}0\\1\\0\\\end{pmatrix}\rbrace {
⎝⎛1−21⎠⎞,⎝⎛010⎠⎞})和左零空间(基底 { ( 1 0 1 ) } \lbrace \begin{pmatrix}1\\0\\1\\\end{pmatrix} \rbrace {
⎝⎛101⎠⎞})。在这里可以清晰明了的看到矩阵的数值计算仅仅是流于表面的现象,向量空间与向量空间之间经由转置发生的变化才是真正的核心。
小贴士:引申一个问题,向量“ ↗ \nearrow ↗”究竟是什么?经过以上的讲解,再将其理解为有方向、有长度的箭头是否已经有点太“低端”了呢?你必须理解,初次学习线性代数,引入一个“有方向、有长度的箭头”作为向量仅仅是为了让你建立几何直观方便入门,在学习的过程中,你要逐渐摒弃这个概念,真正从空间变化的角度来理解线性变换。更多时候,你要把向量看作是空间变化的线性载体。(观点启蒙于课程「线性代数的本质」)
参考资料
- 北京航空航天大学线性代数公开课李尚志老师&个人笔记
- 线性代数的本质系列课程个人笔记第2页
- 清华大学线性代数公开课第一部分徐帆老师&马辉老师 个人笔记第7页、第32页
- MIT线性代数习题公开课个人笔记 第11页
- 高等代数学习指导书(第二版上册)邱维声著 第14页
文章更新记录
- 文章版面微微调整,修改了几个错别字以及数学符号样式调整。「2020.12.4 星期五 15:22」
- 文章调整。 「2021.4.2 18:58」