颓废多日,终于重新回归博客,记录每天的学习or复习,每一天都要加油鸭~
今天算是复习了一下正则化吧,主要也是这个在实习面试中也经常会被问到(一直想系统的记录下找实习的面试的坎坷历程,也记录下被问到的问题,方便后面再面试复习,但一直懒,这周我会完成吧?)
言归正传,废话不多说,接下来复习正则化吧!说到正则化,在面试中经常会问到的就是什么是正则化?L1和L2正则化的区别?
1.为什么要正则化?
当模型过于复杂时,容易造成过拟合,因此为了减小过拟合,要将一部分参数置为0,最直观的方法就是限制参数的个数,但这是一个NP难题,因此可以通过正则化来解决,即减小模型参数大小或参数数量,缓解过拟合
2.什么是正则化?
通式:
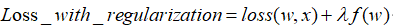
- 正则化项 又称惩罚项,惩罚的是模型的参数,其值恒为非负
- λ是正则化系数,是一个超参数,调节惩罚的力度,越大则惩罚力度越大。
3.L1和L2正则化
正则化的本质就是给参数引入一个先验分布,L1假设拉普拉斯分布,L2假设高斯分布(高斯分布听上去很高大上,其实就是正态分布)
L1:对参数进行一次约束,会形成稀疏解
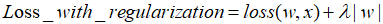
L2正则化:对参数进行二次约束,参数w变小,但不为零,不会形成稀疏解 。
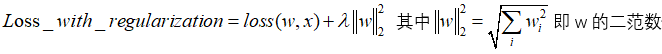
- L1、L2正则化本质都是使其参数w等于或趋向于0,那么我们也可以设计一种方法使其趋向于一个非零值(但一般不这么做): 其中A就是均值。
4.什么是稀疏解,为什么L1正则化更易产生稀疏解?
简单来说,稀疏解就是当有很多维度的特征,其中很多特征的参数都为0,只有一小部分特征的参数为0,即这些特征的参数向量为(0,0,0,0,0,1,0,0,0,1,0,0,0,0,0……)
为什么L1正则化比L2正则化更易产生稀疏解?

图中蓝色一圈一圈的线是Loss中前半部分待优化项 的等高线,就是说在同一条线上其取值相同,且越靠近中心其值越小。左图中黄色圆形区域是L2正则项限制,右图中黄色菱形区域是L1正则项限制。带有正则化的loss函数的最优解要在 和 之间折中,也就是说最优解出现在图中优化项等高线与正则化区域相交处。从图中可以看出,当待优化项 的等高线逐渐向正则项限制区域扩散时,L1正则化的交点大多在坐标轴上,则很多特征维度上其参数w为0,因此会产生稀疏解;而L2正则化的交点大多在非坐标轴上。