Hive连接器存储缓存
对于Trino,使用Hive连接器查询对象存储是一个非常常见的用例。它通常涉及大量数据的传输。这些对象是由多个工作程序从HDFS或任何其他受支持的对象存储中检索的,并在这些工作程序上进行处理。具有不同参数的重复查询,或者甚至来自不同用户的不同查询,经常访问并因此传输相同的对象。
好处
启用缓存可以带来很多好处:
-
减少对象存储的负载
-
每个检索和缓存的对象都避免在后续查询中从存储重复检索。结果,对象存储系统不必一次又一次地提供对象。
例如,如果您的查询从存储访问100MB的对象,则查询第一次运行100MB将被下载并缓存。以下任何查询都使用这些对象。如果您的用户运行另外100个查询来访问相同的对象,则您的存储系统不必做任何重要的工作。如果不进行缓存,则必须一次又一次地提供相同的对象,从而需要提供10GB的总存储空间。
对象存储上的这种减小的负载还可以影响对象存储系统的大小并因此影响其成本。
提高查询性能
通过避免重复的网络传输并取而代之的是从本地缓存访问对象的副本,缓存可以提供显着的性能优势。如果直接访问对象存储的性能比访问缓存低,则性能提升将更为显着。
例如,如果您访问其他网络中的对象存储,则不同的数据中心甚至不同的云提供商区域查询性能会很慢。使用快速的本地存储添加缓存会产生重大影响,并使您的查询更快。
另一方面,如果对象存储已经以很高的性能运行以进行I / O和网络访问,并且本地缓存存储以相似的速度甚至更低的速度运行,则性能收益可能会最小化。
降低查询成本
前面提到的减少对象存储负载的结果是大大减少了网络流量。但是,网络流量是设置中相当大的成本因素,尤其是在托管于公共云提供商系统中时。
架构
缓存可以在两种模式下运行。默认的异步模式直接提供查询的数据,之后异步缓存所有对象。以下所有请求缓存对象的查询都直接从缓存中提供。

另一种模式是通读缓存。在通过任何查询首先从存储中检索到对象之后,对象将被缓存在辅助服务器上的本地缓存存储中。
在这两种模式下,对象都缓存在每个工作程序的本地存储上,并由BookKeeper组件进行管理。工作程序可以从其他工作程序请求缓存的对象,以避免来自对象存储的请求。
缓存块的大小为1MB,非常适合ORC或Parquet文件格式。
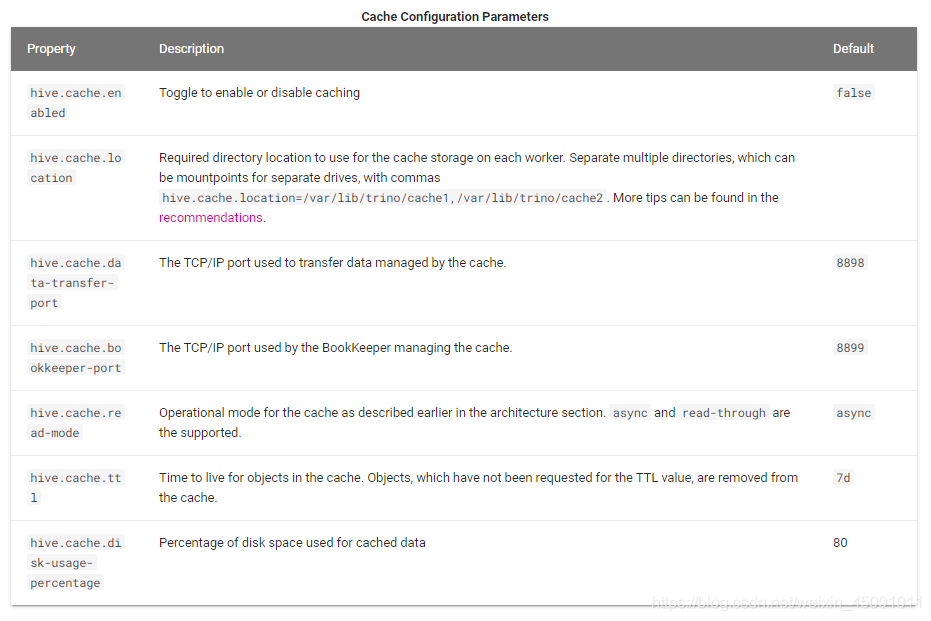
配置
缓存功能是Hive连接器的一部分,可以在目录属性文件中激活:
connector.name=hive-hadoop2
hive.cache.enabled=true
hive.cache.location=/opt/hive-cache
缓存在协调器上运行,所有工作人员都访问对象存储。默认情况下,需要使用用于管理BookKeeper和数据传输的联网端口8898和8899。
要在多个目录上使用缓存,您需要配置不同的缓存目录以及不同的BookKeeper和数据传输端口。
建议
本地缓存存储的速度对于缓存的性能至关重要。最常见且最具成本效益的方法是连接高性能SSD磁盘或等效磁盘。使用RAM磁盘作为内存也可以实现快速的缓存性能。
在所有情况下,都应避免使用节点的根分区和磁盘,而应在多个专用存储设备上附加每个节点上的缓存。高速缓存最多使用磁盘可配置的百分比。存储应该在每个协调器和工作节点上都是本地的。 Trino启动之前,该目录必须存在。我们建议使用多个设备来提高缓存的性能。
连接的存储设备的容量应比查询的对象存储工作负载的大小大20-30%。例如,您当前的查询工作负载通常访问HDFS存储中的分区,这些分区封装了过去3个月的数据。这些分区的总大小目前为1TB。因此,您的缓存驱动器的总容量必须为1.2 TB或更大。
Trino的部署方法决定了如何创建用于缓存的目录。通常,您需要连接快速存储系统(例如SSD驱动器),并确保将其安装在配置的路径上。 Kubernetes,CFT和其他系统允许通过卷进行此操作。
对象存储系统
测试了以下对象存储系统:
-
HDFS
-
与Amazon S3和S3兼容的系统
-
Azure存储系统
-
谷歌云存储
指标
为了验证缓存在系统上的工作方式,您可以采用多种方法:
-
检查所有节点上的缓存存储驱动器上的磁盘使用情况
-
查询JMX公开的缓存系统的指标
缓存的实现通过JMX公开了许多指标。您可以直接在Trino中使用JMX连接器或外部工具检查这些指标和其他指标。
jmx.current。“ rubix:catalog = <catalog_name>,name = stats”表中提供了目录的基本缓存统计信息。表jmx.current。“ rubix:catalog = <目录名称>,type = detailed,name = stats包含更详细的统计信息。
以下示例查询返回配置单元目录的平均高速缓存命中率:
SELECT avg(cache_hit)
FROM jmx.current."rubix:catalog=hive,name=stats"
WHERE NOT is_nan(cache_hit);
局限
缓存不支持用户模拟,并且不能与由Kerberos保护的HDFS一起使用。它不考虑对对象存储的任何特定于用户的访问权限。缓存的对象只是对缓存系统透明的二进制blob,并且可以完全访问所有内容。