《一文吃透——BloomFilter》
关键词:BloomFilter HBase Redis Guava BigData
文章目录
前言
本文为数篇BloomFilter文章笔记整合,非简单拼凑,本着“只有亲身实践过并整理成体系才属于自己真正掌握的知识” 的理念写出一篇“一通百通”的文章,不要用您再多查太多资料,浪费宝贵时间,简单暴力吃透原理。后续每天更新,持续关注,欢迎留言讨论~。
提示:以下是本篇文章正文内容,下面案例可供参考
一、背景知识
麻辣隔壁面试官老王八:如何判断一个元素在亿级数据中是否存在?
没懂???那我们细化下,也就是一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要用尽量高效的办法告诉我它是否存在其中。
懵懵懂懂的小王:常规实现
先不考虑这个条件,我们脑海中出现的第一种方案是什么?
我想大多数想到的都是用 HashMap 来存放数据,因为它的写入查询的效率都比较高。
写入和判断元素是否存在都有对应的 API,所以实现起来也比较简单。
为此我写了一个单测,利用 HashSet 来存数据(底层也是 HashMap );同时为了后面的对比将堆内存写死:-Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError
为了方便调试加入了 GC 日志的打印,以及内存溢出后 Dump 内存。
@Test
public void hashMapTest(){
long star = System.currentTimeMillis();
Set<Integer> hashset = new HashSet<>(100) ;
for (int i = 0; i < 100; i++) {
hashset.add(i) ;
}
Assert.assertTrue(hashset.contains(1));
Assert.assertTrue(hashset.contains(2));
Assert.assertTrue(hashset.contains(3));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
当然,写入 100 条数据时自然是没有问题的。还是在这个基础上,写入 1000W 数据试试???
执行立马OOM。
可见在内存有限的情况下我们不能使用这种方式。
实际情况也是如此;既然要判断一个数据是否存在于集合中,考虑的算法的效率以及准确性肯定是要把数据全部 load 到内存中的。
这个时候Bloom Filter老兄粉末登场了,他就是专门解决如何将庞大的数据 load 到内存中。
而实际上只需要判断数据是否存在,也不是需要把数据查询出来,所以完全没有必要将真正的数据存放进去。
1.布隆过滤器介绍
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。用于解决判断一个元素是否在一个集合中,但它的优势是只需要占用很小的内存空间以及有着高效的查询效率。听起来是很稀松平常的需求,为什么要使用BF这种数据结构呢?
2.产生的契机
回想一下,我们平常在检测集合中是否存在某元素时,都会采用比较的方法。考虑以下情况:
- 如果集合用线性表(数组、链表)存储,查找的时间复杂度为O(n)。
- 如果用平衡BST(如AVL树、Map红黑树)存储,时间复杂度为O(logn)。
- 如果用哈希表存储,并用链地址法与平衡BST解决哈希冲突(参考JDK8的HashMap实现方法),时间复杂度也要有O[log(n/m)],m为哈希分桶数。
上面这几种数据结构配合一些搜索算法是可以解决数据量不大的问题的,如果当集合里面的数据量非常大的时候,就会有问题。不仅查找会变得很慢,而且占用的空间也会大到无法想象。BF就是解决这个矛盾的利器。
比如:
有500万条记录甚至1亿条记录?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。哈希表查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存,普通计算机是无法提供如此大的内存。这个时候,布隆过滤器(Bloom Filter)就应运而生。
3.应用场景
综上,BF在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适,本文第一句话提到的用途即属于此类。另外,由于它不存在假阴性问题,所以用作“不存在”逻辑的处理时有奇效,比如可以用来作为缓存系统(如Redis)的缓冲,防止缓存穿透。
在正式介绍Bloom Filter算法之前,先来看看什么时候需要用到Bloom Filter算法。
1. 数据库防止穿库
Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。
2. 缓存宕机、缓存击穿场景.
一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回。
3. WEB拦截器
如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。
4. 业务场景中判断用户是否阅读过某视频或文章
比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。还有之前自己遇到的一个比赛类的社交场景中,需要判断用户是否在比赛中,如果在则需要更新比赛内容,也可以使用布隆过滤器,可以减少不在的用户查询db或缓存的次数。
5. HTTP缓存服务器、Web爬虫等
在网络爬虫里,一个网址是否被访问过。主要工作是判断一条URL是否在现有的URL集合之中(可以认为这里的数据量级上亿)。
对于HTTP缓存服务器,当本地局域网中的PC发起一条HTTP请求时,缓存服务器会先查看一下这个URL是否已经存在于缓存之中,如果存在的话就没有必要去原始的服务器拉取数据了(为了简单起见,我们假设数据没有发生变化),这样既能节省流量,还能加快访问速度,以提高用户体验。
对于Web爬虫,要判断当前正在处理的网页是否已经处理过了,同样需要当前URL是否存在于已经处理过的URL列表之中。
6. 垃圾邮件过滤
yahoo, gmail等邮箱垃圾邮件过滤功能。假设邮件服务器通过发送方的邮件域或者IP地址对垃圾邮件进行过滤,那么就需要判断当前的邮件域或者IP地址是否处于黑名单之中。如果邮件服务器的通信邮件数量非常大(也可以认为数据量级上亿),那么也可以使用Bloom Filter算法。
其他
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
二、Bloom Filter 原理
杰森·戴维斯(Jason Davies)这篇文章动态展示了布隆过滤器的可视化全过程

每个人都总是热衷于布隆过滤器。但是它们到底是什么?它们有什么用?官方的说法是:它是一个保存了很长的二级制向量,同时结合 Hash 函数实现的。核心实现是一个超大的位数组和几个哈希函数。
介绍布隆过滤器的原理时,先讲解下关于哈希函数的预备知识。
哈希函数
将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。下面是一幅示意图:

可以明显的看到,原始数据经过哈希函数的映射后称为了一个个的哈希编码,数据得到压缩。哈希函数是实现哈希表和布隆过滤器的基础。
1.设计思想
BF是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
当要插入一个元素时,将其数据分别输入k个哈希函数,产生k个哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
当要查询(即判断是否存在)一个元素时,同样将其数据输入哈希函数,然后检查对应的k个比特。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有较大的可能性在集合中。为什么不是一定在集合中呢?因为一个比特被置为1有可能会受到其他元素的影响,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
下图示出一个m=18, k=3的BF示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,因为有一个比特为0,因此w不在该集合中。

假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
2.优缺点
BF的优点是显而易见的:
(1)占用空间少,能够保密数据
不需要存储数据本身,只用比特表示,因此空间占用相对于传统方式有巨大的优势,并且能够保密数据;
(2)时间效率也较高,插入和查询的时间复杂度均为O(k)
哈希函数之间相互独立,可以在硬件指令层面并行计算。
但是,它的缺点也同样明显:
(3)存在假阳性的概率,不适用于任何要求100%准确率的情境
只能插入和查询元素,不能删除元素,这与产生假阳性的原因是相同的。我们可以简单地想到通过计数(即将一个比特扩展为计数值)来记录元素数,但仍然无法保证删除的元素一定在集合中。
3.假阳性率的计算
False Negative,中文可以理解为“假阴性”,形象的一点说是“漏报”。医生告诉你XXX检测为阴性,实际上你是阳性,你是有病的(Sorry, it’s just a joke),那就是漏报了。同样杀毒软件也存在漏报的情况。假阳性是BF最大的痛点,因此有必要权衡,比如计算一下假阳性的概率。为了简单一点,就假设我们的哈希函数选择位数组中的比特时,都是等概率的。当然在设计哈希函数时,也应该尽量满足均匀分布。
在位数组长度m的BF中插入一个元素,它的其中一个哈希函数会将某个特定的比特置为1。因此,在插入元素后,该比特仍然为0的概率是:1-1/m
现有k个哈希函数,并插入n个元素,自然就可以得到该比特仍然为0的概率是:(1-1/m)^kn
反过来讲,它已经被置为1的概率就是:1-(1-1/m)^kn
也就是说,如果在插入n个元素后,我们用一个不在集合中的元素来检测,那么被误报为存在于集合中的概率(也就是所有哈希函数对应的比特都为1的概率)为:(1-(1-1/m)^kn)^k
当n比较大时,根据重要极限公式,可以近似得出假阳性率:(1-e^-kn)^k

所以,在哈希函数的个数k一定的情况下:
- 位数组长度m越大,假阳性率越低;
- 已插入元素的个数n越大,假阳性率越高。
事实上,即使哈希函数不是等概率选择比特的,最终也会得出相同的结果,可以借助吾妻-霍夫丁不等式(Azuma-Hoeffding inequality)证明。
有一些框架内已经内建了BF的实现,免去了自己实现的烦恼。下面以Guava为例,看看Google是怎么做的。
(简书:https://www.jianshu.com/p/bef2ec1c361f)
4.原理图

5.过程解析
(1)初始化
首先需要初始化一个二进制的数组,长度设为 L(图中为 8),同时初始值全为 0 。
(2)hash 函数运算
当写入一个 A1=1000 的数据时,需要进行 H 次 hash 函数的运算(这里为 2 次);与 HashMap 有点类似,通过算出的 HashCode 与 L 取模后定位到 0、2 处,将该处的值设为 1。
A2=2000 也是同理计算后将 4、7 位置设为 1。
(3)hash 函数运算
当有一个 B1=1000 需要判断是否存在时,也是做两次 Hash 运算,定位到 0、2 处,此时他们的值都为 1 ,所以认为 B1=1000 存在于集合中。
(4)hash 函数运算
当有一个 B2=3000 时,也是同理。第一次 Hash 定位到 index=4 时,数组中的值为 1,所以再进行第二次 Hash 运算,结果定位到 index=5 的值为 0,所以认为 B2=3000 不存在于集合中。
整个的写入、查询的流程就是这样,汇总起来就是:
对写入的数据做 H 次 hash 运算定位到数组中的位置,同时将数据改为 1 。
(5)数据查询
当有数据查询时也是同样的方式定位到数组中。 一旦其中的有一位为 0 则认为数据肯定不存在于集合,否则数据可能存在于集合中。
布隆过滤特点
(1)只要返回数据不存在,则肯定不存在。
(2)返回数据存在,但只能是大概率存在。
(3)同时不能清除其中的数据。
第一点应该都能理解,重点解释下 2、3 点。
为什么返回存在的数据却是可能存在呢,这其实也和 HashMap 类似。
在有限的数组长度中存放大量的数据,即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据最后定位到的位置是一模一样的。
这时拿 B 进行查询时那自然就是误报了。
删除数据也是同理,当我把 B 的数据删除时,其实也相当于是把 A 的数据删掉了,这样也会造成后续的误报。
基于以上的 Hash 冲突的前提,所以 Bloom Filter 有一定的误报率,这个误报率和 Hash 算法的次数 H,以及数组长度 L 都是有关的。
实现一个布隆过滤(1)
代码如下(示例):
public class BloomFilters {
/**
* 数组长度
*/
private int arraySize;
/**
* 数组
*/
private int[] array;
public BloomFilters(int arraySize) {
this.arraySize = arraySize;
array = new int[arraySize];
}
/**
* 写入数据
* @param key
*/
public void add(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
array[first % arraySize] = 1;
array[second % arraySize] = 1;
array[third % arraySize] = 1;
}
/**
* 判断数据是否存在
* @param key
* @return
*/
public boolean check(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
int firstIndex = array[first % arraySize];
if (firstIndex == 0) {
return false;
}
int secondIndex = array[second % arraySize];
if (secondIndex == 0) {
return false;
}
int thirdIndex = array[third % arraySize];
if (thirdIndex == 0) {
return false;
}
return true;
}
/**
* hash 算法1
* @param key
* @return
*/
private int hashcode_1(String key) {
int hash = 0;
int i;
for (i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return Math.abs(hash);
}
/**
* hash 算法2
* @param data
* @return
*/
private int hashcode_2(String data) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < data.length(); i++) {
hash = (hash ^ data.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash);
}
/**
* hash 算法3
* @param key
* @return
*/
private int hashcode_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash);
}
}
首先初始化了一个 int 数组。
写入数据的时候进行三次 hash 运算,同时把对应的位置置为 1。
查询时同样的三次 hash 运算,取到对应的值,一旦值为 0 ,则认为数据不存在。
实现逻辑其实就和上文描述的一样。
下面来测试一下,同样的参数:
-Xms64m -Xmx64m -XX:+PrintHeapAtGC
@Test
public void bloomFilterTest(){
long star = System.currentTimeMillis();
BloomFilters bloomFilters = new BloomFilters(10000000) ;
for (int i = 0; i < 10000000; i++) {
bloomFilters.add(i + "") ;
}
Assert.assertTrue(bloomFilters.check(1+""));
Assert.assertTrue(bloomFilters.check(2+""));
Assert.assertTrue(bloomFilters.check(3+""));
Assert.assertTrue(bloomFilters.check(999999+""));
Assert.assertFalse(bloomFilters.check(400230340+""));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
只花了 3 秒钟就写入了 1000W 的数据同时做出来准确的判断。
把数组长度缩小到了 100W 时就出现了一个误报,400230340 这个数明明没在集合里,却返回了存在。 这也体现了 Bloom Filter 的误报率。 我们提高数组长度以及 hash 计算次数可以降低误报率,但相应的 CPU、内存的消耗就会提高;这就需要根据业务需要自行权衡。
实现一个布隆过滤(2)
添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
import java.util.BitSet;
/**
* Created by haicheng.lhc on 18/05/2017.
*
* @author haicheng.lhc
* @date 2017/05/18
*/
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] {
7, 11, 13, 31, 37, 61,};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = " [email protected] ";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}
应用实例实操
大数据去重统计之BloomFilter
尝试了使用Bloom filter对大量数据的去重计数,记录一下。
(1)初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0:
bloomfilter
(2)当来了一个元素 a,进行判断,使用两个哈希函数,计算出该元素对应的Hash值为1和5,然后到Bloom Filter中判断第1位和第5位的值,上面全部为0,因此a不在Bloom Filter内,将 a 添加进去:
bloomfilter
(3)添加a之后,BloomFilter的第1位和第5位的值为1,之后的元素,要判断是不是在Bloom Filter内,也是同a一样的方法,只有对元素哈希后对应位置上都是 1 才认为这个元素在集合内(虽然这样可能会误判):
bloomfilter
(4)随着元素的插入,Bloom filter 中修改的值变多,出现误判的几率也随之变大,当新来一个元素时,满足其在Bloom Filter内的条件,即所有对应位都是 1 ,这样就可能有两种情况,一是这个元素就在集合内,没有发生误判;还有一种情况就是发生误判,出现了哈希碰撞,这个元素本不在集合内。
bloomfilter
使用BloomFilter,有三个重要的值,错误率(false positive rate)、哈希函数个数以及BloomFilter位数组的大小,关于这三个值的最优配置算法,相关阅读中的文章有详细的说明。有一个原则,(BloomFilter位数组大小)/(实际的元素个数)越大,错误率越低,但消耗的空间会越多。
在网上搜了一个Java版本的Bloom Filter做了下测试
package com.lxw1234.bloomfilter;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Date;
public class TestBloomFilter {
public static void main(String[] args) {
File file = new File(args[0]);
//错误率
double falsePositiveProbability = 0.000001;
//预估的元素个数
int expectedNumberOfElements = 200000000;
long uv = 0l;
long pv = 0l;
Runtime rt = Runtime.getRuntime();
long start = System.currentTimeMillis();
System.out.println("start at [" + new Date() + "] ..");
MyBloomFilter bloomFilter = new MyBloomFilter(falsePositiveProbability, expectedNumberOfElements);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
while ((tempString = reader.readLine()) != null) {
if(!bloomFilter.contains(tempString)) {
bloomFilter.add(tempString);
uv++;
}
pv++;
if(pv % 100000 == 0) {
System.out.println("pv:[" + pv + "] uv:[" + uv + "] max:[" + rt.maxMemory() + "] free:[" + rt.freeMemory() + "] ..");
}
}
reader.close();
System.out.println("Total pv:[" + pv + "] Total uv:[" + uv + "] ..");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
long end = System.currentTimeMillis();
System.out.println("end at [" + new Date() + "] ..");
System.out.println("Total cost [" + (end - start) + "] ms ..");
System.out.println("count:[" + bloomFilter.count() + "] ..");
System.out.println("size:[" + bloomFilter.size() + "] ..");
}
}
第一次测试使用一个较小的数据集:
总记录数:11014003 去重记录数:2590210 总大小:约250M
运行结果如下:
上面使用Java版本的BloomFilter中,使用了BitSet,根据配置的错误率及元素个数,将BitSet初始化成最大位数(即Integer.MAX_VALUE)2147483647,那么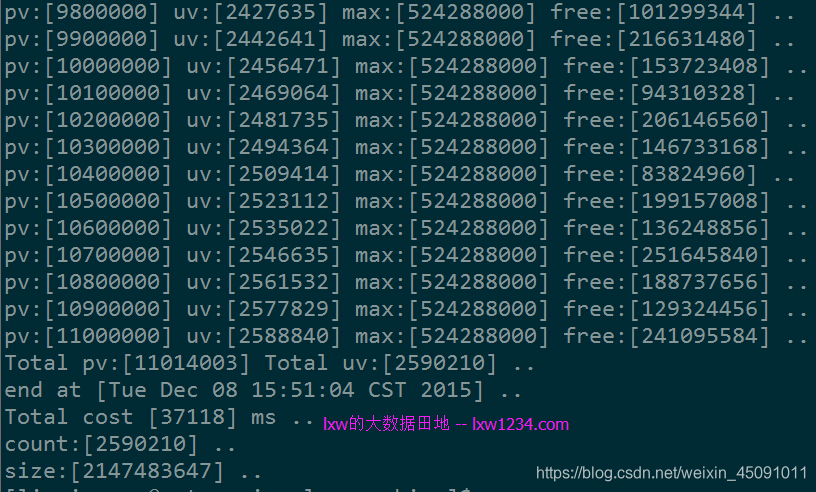
此时(BloomFilter位数组大小)/(实际的元素个数) = 2147483647/2590210 = 829,统计结果和实际去重记录完全一致,没有误判。
第二次测试使用一个较大的数据集:
总记录数:209310285 去重记录数:103274131 总大小:约4.5G
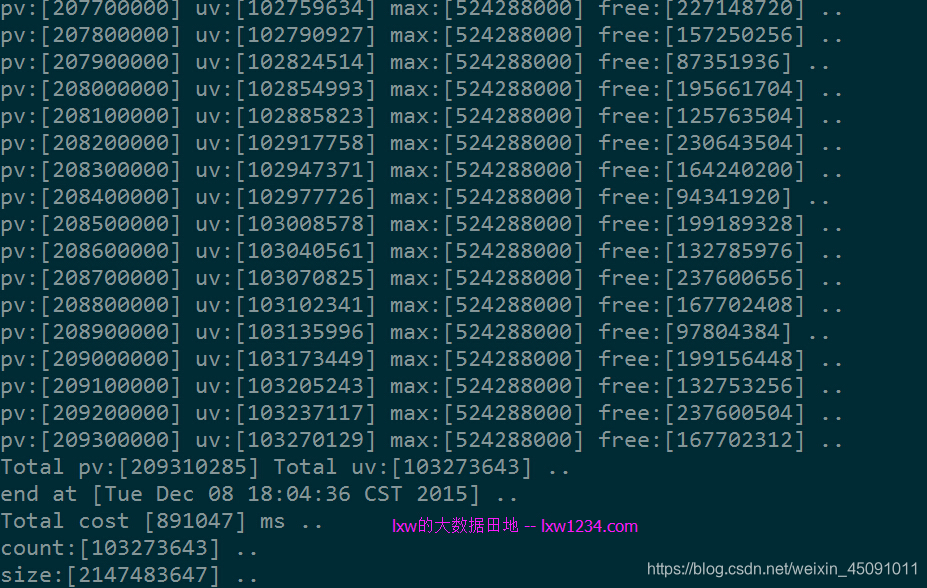
此时(BloomFilter位数组大小)/(实际的元素个数) = 2147483647/103274131 = 21,该比值大大降低,因此出现了误判。
另外,也使用streamlib跑了一下:

当然这个测试只是大概跑了一下,对于BloomFilter还有一些可优化的余地。
较之前使用的streamlib基数估计法对大数据量去重计数,这种方法准确率更高,但消耗的内存太大,而且受Hash函数个数影响,性能也差一些。
但这种方式在特定场景下特别有效,比如用来判断一个KEY是否存在,因而减少数据库或缓存的空查询次数等等。
Hbase
Hbase 布隆过滤器BloomFilter,主要功能:提高HBase随机读的性能
1.什么是布隆过滤器
- 布隆过滤器是一种多哈希函数映射的快速查找算法(存储结构),可以实现用很小的空间和运算代价,来实现海量数据的存在与否的记录(黑白名单判断)。
- 特点是高效的插入和查询,可以判断出一定不存在和可能存在;相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的可能存在结果是概率性的,而不是确切的。
- 布隆过滤器本质是一个bit向量或者bit数组

2.布隆过滤器操作及原理
(1)添加元素
添加一个值到布隆过滤器中,需要使用多个hash函数生成多个hash值,每个hash值对应位数组上的一个点,然后将位数组对应的位置标记为1。如下图,字符串’hello’就通过3种hash函数生成了哈希值1,3,9,字符串‘word’就生成了1,5,7
- 注:由于hello和word都返回了bit位1,所以前面的1会被覆盖


(2)查询元素
查询元素flink是否存在集合中的时候,同样的方法将flink通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。 如果3个点都为1,则该元素可能存在集合中。
- 注意:此处不能判断该元素是否一定存在,可能存在一定的误判率。
因为新增的元素越来越多,被置为 1 的 bit 位也会越来越多,这样“flink” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “flink” 这个值存在。比如flink三个hash值为1,3,7,就能说明flink一定存在吗?
(3)如何减少误差
-
加大布隆过滤器的长度,否则很容易就所有的bit位都为1了
-
哈希函数的个数要考虑,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误差会变高。
3.布隆过滤器在hbase中的应用
(1)布隆过滤器类型
布隆过滤器是hbase中的高级功能,它能够减少特定访问模式(get/scan)下的查询时间。不过由于这种模式增加了内存和存储的负担,所以被默认为关闭状态。
hbase支持如下类型的布隆过滤器:
-
NONE 不使用布隆过滤器
-
ROW 行键使用布隆过滤器
-
ROWCOL 列键使用布隆过滤器
至于选用什么模式,还是要看使用场景
(2)hbase数据存储及访问
hbase的实际存储结构是HFile,它是位于hdfs系统中的,也就是在磁盘中。而加载到内存中的数据存储在MemStore中,当MemStore中的数据达到一定数量时,它会将数据存入HFile中。
- HFIle是由一个个数据块与索引块组成,他们通常默认为64KB。
hbase是通过块索引来访问这些数据块的。而索引是由每个数据块的第一行数据的rowkey组成的。当hbase打开一个HFile时,块索引信息会优先加载到内存当中。然后hbase会通过这些块索引来查询数据。
(3)布隆过滤器在hbase中的应用
当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。
采用布隆过滤器后,它能够准确判断该HFile的所有数据块中是否含有我们查询的数据,从而大大减少不必要的块加载,增加吞吐,降低内存消耗,提高性能
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
4.hbase实操
你可以在列族上打开布隆过滤器,如下所示:
hbase(main):007:0> create 'mytable',
{
NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
BLOOMFILTER参数的默认值是NONE。一个行级布隆过滤器用ROW打开,列标识符级布隆过滤器用ROWCOL打开。
行级布隆过滤器在数据块里检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的开销高于ROW布隆过滤器。
5.HBase相关问题:
(1)布隆过滤器的存储在哪?
对于hbase而言,当我们选择采用布隆过滤器之后,HBase会在生成StoreFile(HFile)时包含一份布隆过滤器结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。但是在大多数情况下,这些负担相对于布隆过滤器带来的好处是可以接受的。
(2)采用布隆过滤器后,hbase如何get数据?
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
(3)采用ROW还是ROWCOL布隆过滤器?
这取决于用户的使用模式。如果用户只做行扫描,使用更加细粒度的行加列布隆过滤器不会有任何的帮助,这种场景就应该使用行级布隆过滤器。当用户不能批量更新特定的一行,并且最后的使用存储文件都含有改行的一部分时,行加列级的布隆过滤器更加有用。
例如:
ROW 使用场景
假设有2个Hfile文件hf1和hf2
hf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v) hf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤hf2,get(r3)就会过滤hf1 。
ROWCOL使用场景
假设有2个Hfile文件hf1和hf2
hf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v) hf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取hf1+hf2;
而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤hf2,get(r1,q2)就会过滤hf1。
- 注意:ROW和ROWCOL只是名字上有联系,但是ROWCOL并不是ROW的扩展,也不能取代ROW
(4)Bloomfilter在HBase中的作用?
HBase利用Bloomfilter来提高随机读(Get)的性能,对于顺序读(Scan)而言,设置Bloomfilter是没有作用的(0.92以后,如果设置了bloomfilter为ROWCOL,对于指定了qualifier的Scan有一定的优化,但不是那种直接过滤文件,排除在查找范围的形式)
(5)Bloomfilter在HBase中的开销?
Bloomfilter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloomfilter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
(6)Bloomfilter如何提高随机读(Get)的性能?
对于某个region的随机读,HBase会遍历读memstore及storefile(按照一定的顺序),将结果合并返回给客户端。如果你设置了bloomfilter,那么在遍历读storefile时,就可以利用bloomfilter,忽略某些storefile。
(7)HBase中的Bloomfilter的类型及使用?(控制粒度)
(同:(3)采用ROW还是ROWCOL布隆过滤器)
- a) ROW, 根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf2,get(r3)就会过滤sf1 - b) ROWCOL,根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
(8)ROWCOL一定比ROW效果好么?
不一定
- a)ROWCOL只对指定列(Qualifier)的随机读(Get)有效,如果应用中的随机读get,只含row,而没有指定读哪个qualifier,那么设置ROWCOL是没有效果的,这种场景就应该使用ROW
- b)如果随机读中指定的列(Qualifier)的数目大于等于2,在0.90版本中ROWCOL是无效的,而在0.92版本以后,HBASE-2794对这一情景作了优化,是有效的(通过KeyValueScanner#seekExactly)
- c)如果同一row多个列的数据在应用上是同一时间put的,那么ROW与ROWCOL的效果近似相同,而ROWCOL只对指定了列的随机读才会有效,所以设置为ROW更佳
(6)region下的storefile数目越多,bloomfilter的效果越好
(7)region下的storefile数目越少,HBase读性能越好
6.源码解析
(1)get操作会enable bloomfilter帮助剔除掉不会用到的Storefile
在scan初始化时(get会包装为scan)对于每个storefile会做shouldSeek的检查,如果返回false,则表明该storefile里没有要找的内容,直接跳过
if (memOnly == false
&& ((StoreFileScanner) kvs).shouldSeek(scan, columns)) {
scanners.add(kvs);
}
shouldSeek方法:如果是scan直接返回true表明不能跳过,然后根据bloomfilter类型检查。
if (!scan.isGetScan()) {
return true;
}
byte[] row = scan.getStartRow();
switch (this.bloomFilterType) {
case ROW:
return passesBloomFilter(row, 0, row.length, null, 0, 0);
case ROWCOL:
if (columns != null && columns.size() == 1) {
byte[] column = columns.first();
return passesBloomFilter(row, 0, row.length, column, 0, column.length);
}
// For multi-column queries the Bloom filter is checked from the
// seekExact operation.
return true;
default:
return true;
}
(2)指明qualified的scan在配了rowcol的情况下会剔除不会用掉的StoreFile。
对指明了qualify的scan或者get进行检查:seekExactly
// Seek all scanners to the start of the Row (or if the exact matching row
// key does not exist, then to the start of the next matching Row).
if (matcher.isExactColumnQuery()) {
for (KeyValueScanner scanner : scanners)
scanner.seekExactly(matcher.getStartKey(), false);
} else {
for (KeyValueScanner scanner : scanners)
scanner.seek(matcher.getStartKey());
}
如果bloomfilter没命中,则创建一个很大的假的keyvalue,表明该storefile不需要实际的scan
public boolean seekExactly(KeyValue kv, boolean forward)
throws IOException {
if (reader.getBloomFilterType() != StoreFile.BloomType.ROWCOL ||
kv.getRowLength() == 0 || kv.getQualifierLength() == 0) {
return forward ? reseek(kv) : seek(kv);
}
boolean isInBloom = reader.passesBloomFilter(kv.getBuffer(),
kv.getRowOffset(), kv.getRowLength(), kv.getBuffer(),
kv.getQualifierOffset(), kv.getQualifierLength());
if (isInBloom) {
// This row/column might be in this store file. Do a normal seek.
return forward ? reseek(kv) : seek(kv);
}
// Create a fake key/value, so that this scanner only bubbles up to the top
// of the KeyValueHeap in StoreScanner after we scanned this row/column in
// all other store files. The query matcher will then just skip this fake
// key/value and the store scanner will progress to the next column.
cur = kv.createLastOnRowCol();
return true;
}
这边为什么是rowcol才能剔除storefile???,很简单,scan是一个范围,如果是row的bloomfilter不命中只能说明该rowkey不在此storefile中,但next rowkey可能在。而rowcol的bloomfilter就不一样了,如果rowcol的bloomfilter没有命中表明该qualifiy不在这个storefile中,因此这次scan就不需要scan此storefile了!
7.结论如下:
(1)任何类型的get(基于rowkey和基于row+col)bloomfilter都能生效,关键是get的类型要匹配bloomfilter的类型
(2)基于row的scan是没办法优化的
scan是一个范围,如果是row的bloomfilter不命中只能说明该rowkey不在此storefile中,但next rowkey可能在。
(3)row+col+qualify的scan可以去掉不存在此qualify的storefile,也算是不错的优化了,而且指明qualify也能减少流量,因此scan尽量指明qualify。
而rowcol的bloomfilter就不一样了,如果rowcol的bloomfilter没有命中表明该qualifiy不在这个storefile中,因此这次scan就不需要scan此storefile了。
(4)常用场景
- 1、根据key随机读时,在StoreFile级别进行过滤
- 2、读数据时,会查询到大量不存在的key,也可用于高效判断key是否存在
Resdis
1. 原理
二进制向量和一系列随机映射函数实现, 可以用于检索一个元素是否在一个集合中。
下面来看看布隆过滤器是如何判断元素在一个集合中,如下图:
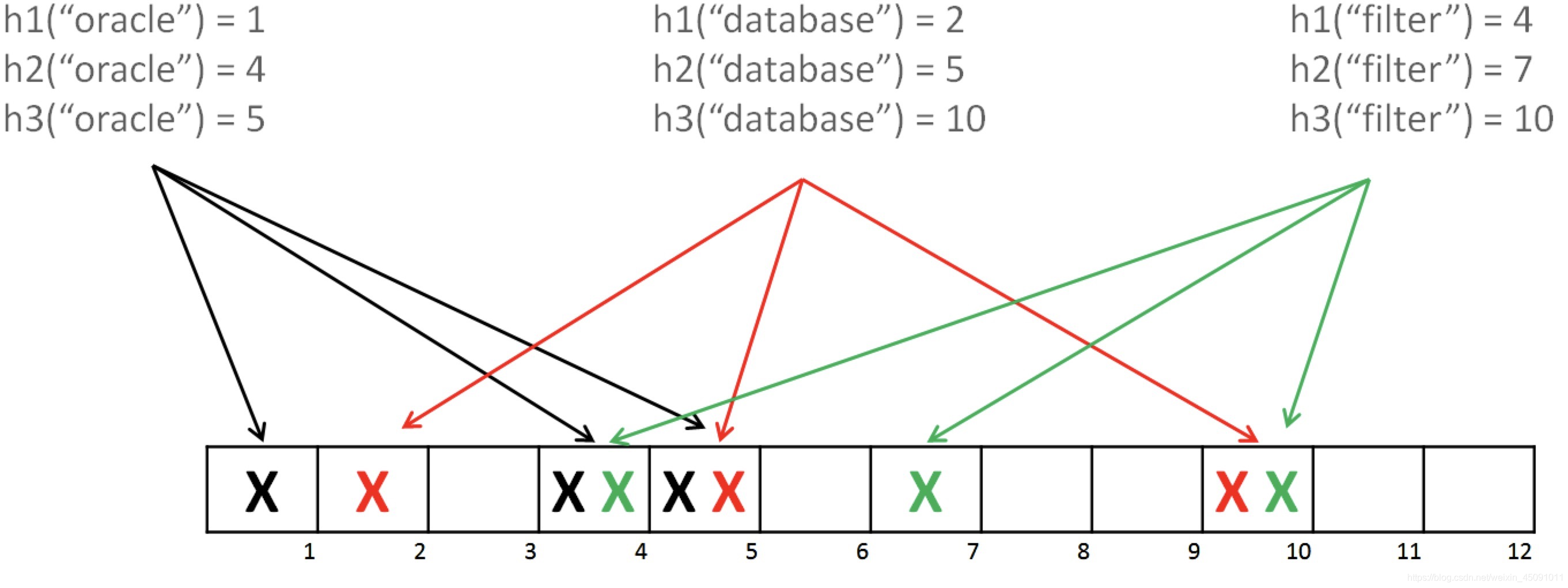
有三个hash函数和一个位数组,oracle经过三个hash函数,得到第1、4、5位为1,database同理得到2、5、10位1,这样如果我们需要判断oracle是否在此位数组中,则通过hash函数判断位数组的1、4、5位是否均为1,如果均为1,则判断oracle在此位数组中,database同理。这就是布隆过滤器判断元素是否在集合中的原理。
想必聪明的读者已经发现,如果bloom经过三个hash算法,需要判断 1、5、10位是否为1,恰好因为位数组中添加oracle和database导致1、5、10为1,则布隆过滤器会判断bloom会判断在集合中,这不是Bug吗,导致误判。但是可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会再集合中。
是的,这个是布隆过滤器的缺点,有一点的误识别率,但是布隆过滤器有2大优点,使得这个缺点在某些应用场景中是可以接受的,2大优点是空间效率和查询时间都远远高于一般的算法。常规的数据结构set,也是经过被用于判断一个元素是否在集合中,但如果有上百万甚至更高的数据,set结构所占的空间将是巨大的,布隆过滤器只需要上百万个位即可,10多Kb即可。
导致这个缺点是因为hash碰撞,但布隆过滤器通过多个hash函数来降低hash碰撞带来的误判率,如下图:
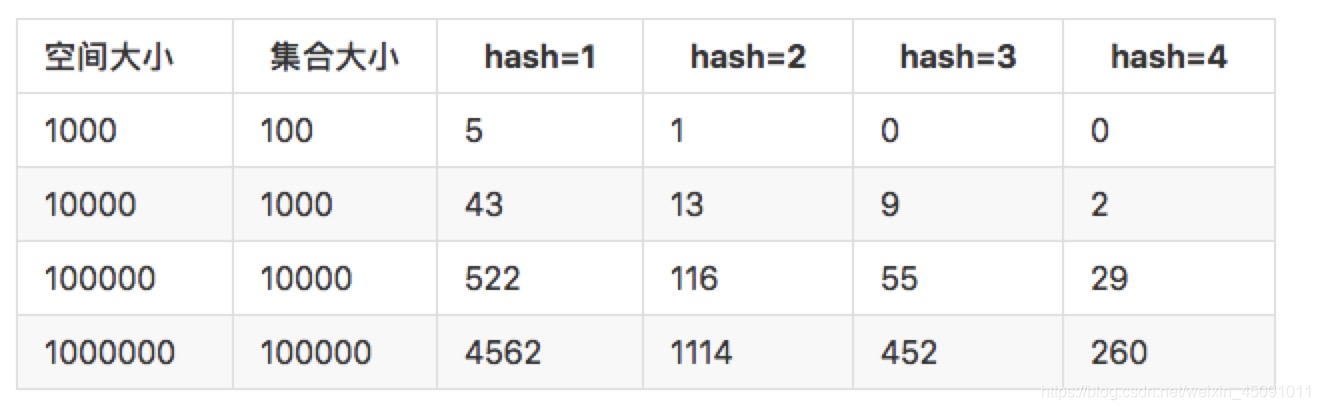
当只有1个hash函数的时候,误判率很高,但4个hash函数的时候已经缩小10多倍,可以动态根据业务需求所允许的识别率来调整hash函数的个数,当然hash函数越多,所带来的空间效率和查询效率也会有所降低。
第二个缺点相对set来说,不可以删除,因为布隆过滤器并没有存储key,而是通过key映射到位数组中。
2. 总结
- 布隆过滤器是用于判断一个元素是否在集合中。通过一个位数组和N个hash函数实现。
- 优点:空间效率高,所占空间小。查询时间短。
- 缺点:元素添加到集合中后,不能被删除。有一定的误判率
3.Redis-BloomFilter实操
Redis在4.0版本推出了 module 的形式,可以将 module 作为插件额外实现Redis的一些功能。官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module。
除了这个还有别的方式可以实现,下面一一列举一下:
- RedisBloom - Bloom Filter Module for Redis
- pyreBloom
- lua脚本来实现
- 原生语言,调用 Redis 的 bitmap 相关操作来实现
Redis 高级主题之布隆过滤器(BloomFilter)
布隆过滤器在Redis中如何应用,先来一张思维导图浏览全文。
Redis 之布隆过滤器(BloomFilter)
4. 原生语言 + redis 实现
Python 原生语言比较慢,如果是Go语言,没有找到合适的开源redis的BloomFilter,就可以自己用原生语言 + redis的 bitmap 相关操作实现。 Java 语言的话,RedisBloom项目里有实现 JReBloom,因非Java开发者,这块可以自行了解。
分布式缓存击穿
缓存是加速系统响应的一种途径,通常情况下只有系统的部分数据。当请求了缓存中没有的数据时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。
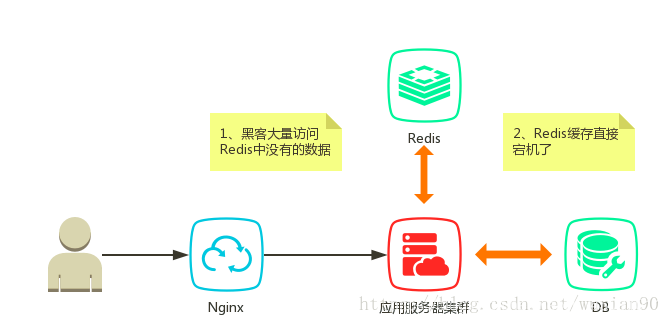
缓存中无值(未宕机)
互斥锁
我们最先想到的应该是加锁获取缓存。也就是当获取的value值为空时(这里的空表示缓存过期),先加锁,然后从数据库加载并放入缓存,最后释放锁。如果其他线程获取锁失败,则睡眠一段时间后重试。下面使用Redis的setnx来实现分布式锁,如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}
缓存永不过期
缓存永不过期的意思是:真正的缓存过期时间不有Redis控制,而是由程序代码控制。当获取数据时发现数据超时时,就需要发起一个异步请求去加载数据。这种策略的有点就是不会产生死锁等现象,但是有可能会造成缓存不一致的现象,但是笔者看来一般情况下都是可以适用的。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
缓存宕机
上面说到的场景是缓存依旧有效的,当Redis挂掉时,这个时候如何来应对大量的回源请求呢?先来说一种简单的方式:白名单。
白名单
白名单顾名思义就是:在缓存宕机之前的一段时间里,会将请求的数据在系统中的有无,记录在一个Map中。当缓存宕机后,首先在Map中判断是否含有数据,有则回源DB,没有的话就直接返回结果。
这种方式实现起来比较简单(Demo就不提供了),但是占用的内存空间比较庞大。如一个value是10字节,那么要存储大小为1亿的Map时,其所需的内存大小大约是:10 * 2 * 10e8 = 2G(假设Map的利用率为50%)。由此可见其对于一种类型的数据判断就需要一个 2G 的Map去操作,这种方式就不可行了。
布隆过滤器
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
代码实现
在实际应用当中,我们不需要自己去实现BloomFilter。可以使用Guava提供的相关类库即可。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:误判的数量:94
对于缓存宕机的场景,使用白名单或者布隆过滤器都有可能会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况应该也是可以忍受的。
Google Guava
1. 知识回顾
在第二节原理里面,手工实现了一个布隆过滤。
Guava 实现
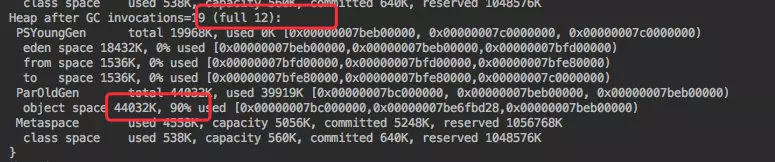
刚才的方式虽然实现了功能,也满足了大量数据。但其实观察 GC 日志非常频繁,同时老年代也使用了 90%,接近崩溃的边缘。
总的来说就是内存利用率做的不好。
2.Google Guava 库
其实 Google Guava 库中也实现了该算法,下面来看看业界权威的实现。
-Xms64m -Xmx64m -XX:+PrintHeapAtGC
@Test
public void guavaTest() {
long star = System.currentTimeMillis();
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
10000000,
0.01);
for (int i = 0; i < 10000000; i++) {
filter.put(i);
}
Assert.assertTrue(filter.mightContain(1));
Assert.assertTrue(filter.mightContain(2));
Assert.assertTrue(filter.mightContain(3));
Assert.assertFalse(filter.mightContain(10000000));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
也是同样写入了 1000W 的数据,执行没有问题。
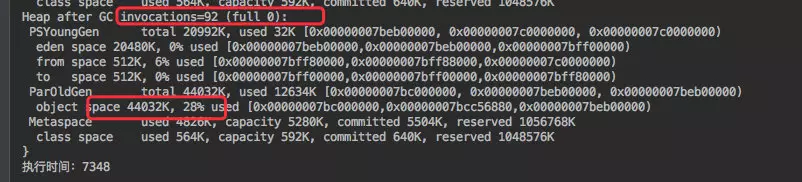
观察 GC 日志会发现没有一次 fullGC,同时老年代的使用率很低。和刚才的一对比这里明显的要好上很多,也可以写入更多的数据。
3.源码分析
那就来看看 Guava 它是如何实现的。采用Guava 27.0.1版本的源码,BF的具体逻辑位于com.google.common.hash.BloomFilter类中。开始读代码吧。
BloomFilter类的成员属性
不多,只有4个。
/** The bit set of the BloomFilter (not necessarily power of 2!) */
private final LockFreeBitArray bits;
/** Number of hashes per element */
private final int numHashFunctions;
/** The funnel to translate Ts to bytes */
private final Funnel<? super T> funnel;
/** The strategy we employ to map an element T to {@code numHashFunctions} bit indexes. */
private final Strategy strategy;
- bits即上文讲到的长度为m的位数组,采用LockFreeBitArray类型做了封装。
- numHashFunctions即哈希函数的个数k。
- funnel是Funnel接口实现类的实例,它用于将任意类型T的输入数据转化为Java基
-类型的数据(byte、int、char等等)。这里是会转化为byte。 - strategy是布隆过滤器的哈希策略,即数据如何映射到位数组,其具体方法在BloomFilterStrategies枚举中。
BloomFilter的构造
这个类的构造方法是私有的。要创建它的实例,应该通过公有的create()方法。它一共有5种重载方法,但最终都是调用了如下的逻辑。
@VisibleForTesting
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
checkNotNull(funnel);
checkArgument(
expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values, since the resulting size
* is proportional to -log(p), but there is not much of a point after all, e.g.
* optimalM(1000, 0.0000000000000001) = 76680 which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
该方法接受4个参数:funnel是插入数据的Funnel,expectedInsertions是期望插入的元素总个数n,fpp即期望假阳性率p,strategy即哈希策略。
由上可知,位数组的长度m和哈希函数的个数k分别通过optimalNumOfBits()方法和optimalNumOfHashFunctions()方法来估计。
构造方法中这两个比较重要的参数,一个是预计存放多少数据,一个是可以接受的误报率。 我这里的测试 demo 分别是 1000W 以及 0.01。

估计最优m值和k值
Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions 。
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
哈希策略
在BloomFilterStrategies枚举中定义了两种哈希策略,都基于著名的MurmurHash算法,分别是MURMUR128_MITZ_32和MURMUR128_MITZ_64。前者是一个简化版,所以我们来看看后者的实现方法。
MURMUR128_MITZ_64() {
@Override
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
@Override
public <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private /* static */ long lowerEight(byte[] bytes) {
return Longs.fromBytes(
bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private /* static */ long upperEight(byte[] bytes) {
return Longs.fromBytes(
bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
};
其中put()方法负责向布隆过滤器中插入元素,mightContain()方法负责判断元素是否存在。以put()方法为例讲解一下流程吧。
使用MurmurHash算法对funnel的输入数据进行散列,得到128bit(16B)的字节数组。
取低8字节作为第一个哈希值hash1,取高8字节作为第二个哈希值hash2。
进行k次循环,每次循环都用hash1与hash2的复合哈希做散列,然后对m取模,将位数组中的对应比特设为1。
-
在循环中实际上应用了双重哈希(double hashing)的思想,即可以用两个哈希函数来模拟k个,其中i为步长:

这种方法在开放定址的哈希表中,也经常用来减少冲突。 -
哈希值有可能为负数,而负数是不能在位数组中定位的。所以哈希值需要与Long.MAX_VALUE做bitwise AND,直接将其最高位(符号位)置为0,就变成正数了。
位数组具体实现
来看LockFreeBitArray类的部分代码。
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
this(new long[Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING))]);
}
// Used by serialization
LockFreeBitArray(long[] data) {
checkArgument(data.length > 0, "data length is zero!");
this.data = new AtomicLongArray(data);
this.bitCount = LongAddables.create();
long bitCount = 0;
for (long value : data) {
bitCount += Long.bitCount(value);
}
this.bitCount.add(bitCount);
}
/** Returns true if the bit changed value. */
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}
boolean get(long bitIndex) {
return (data.get((int) (bitIndex >>> 6)) & (1L << bitIndex)) != 0;
}
// ....
}
“LockFree”BitArray?因为它是采用原子类型AtomicLongArray作为位数组的存储的,确实不需要加锁。另外还有一个Guava中特有的LongAddable类型的计数器,用来统计置为1的比特数。
采用AtomicLongArray除了有并发上的优势之外,更主要的是它可以表示非常长的位数组。一个长整型数占用64bit,因此data[0]可以代表第063bit,data[1]代表64127bit,data[2]代表128~191bit……依次类推。这样设计的话,将下标i无符号右移6位就可以获得data数组中对应的位置,再在其基础上左移i位就可以取得对应的比特了。
最后多嘴一句,上面的代码中用到了Long.bitCount()方法计算long型二进制表示中1的数量,堪称Java语言中最强的骚操作之一:
public static int bitCount(long i) {
// HD, Figure 5-14
i = i - ((i >>> 1) & 0x5555555555555555L);
i = (i & 0x3333333333333333L) + ((i >>> 2) & 0x3333333333333333L);
i = (i + (i >>> 4)) & 0x0f0f0f0f0f0f0f0fL;
i = i + (i >>> 8);
i = i + (i >>> 16);
i = i + (i >>> 32);
return (int)i & 0x7f;
}
put 写入函数
真正存放数据的 put 函数如下:
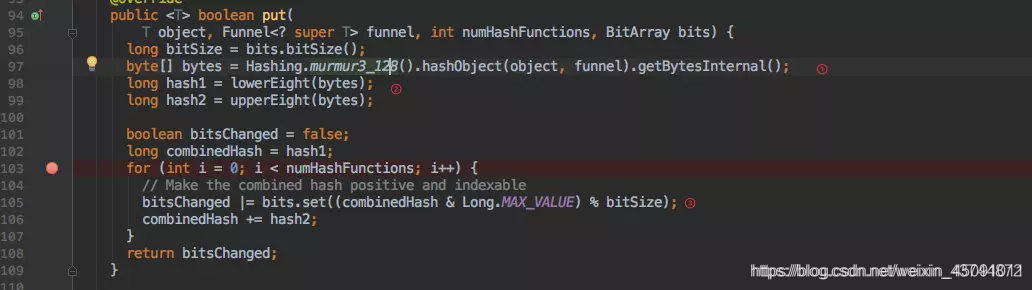
根据 murmur3_128 方法的到一个 128 位长度的 byte[]。
分别取高低 8 位的到两个 hash 值。
再根据初始化时的到的执行 hash 的次数进行 hash 运算。
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
其实也是 hash取模拿到 index 后去赋值 1.
重点是 bits.set() 方法。
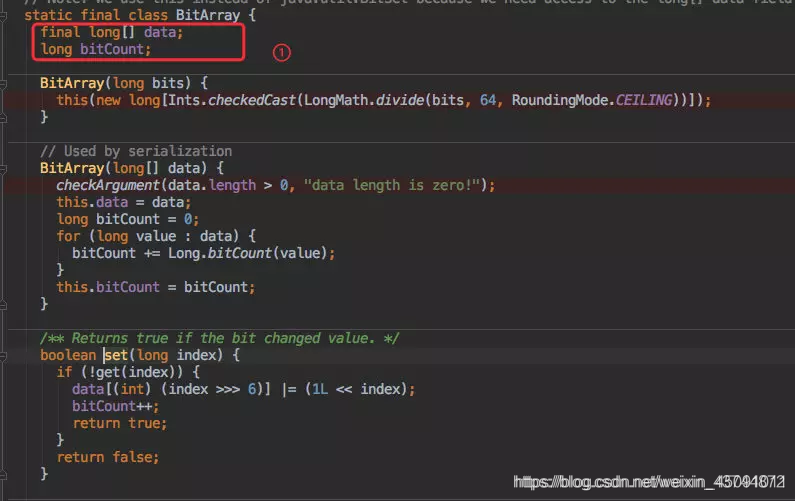
其实 set 方法是 BitArray 中的一个函数,BitArray 就是真正存放数据的底层数据结构。
利用了一个 long[] data 来存放数据。
所以 set() 时候也是对这个 data 做处理。
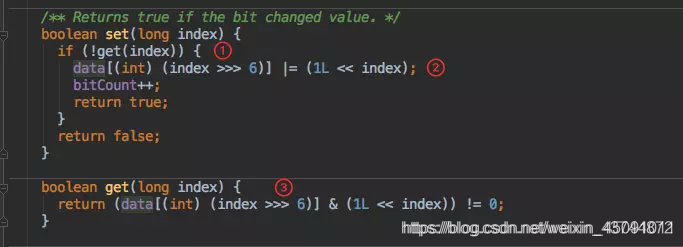
在 set 之前先通过 get() 判断这个数据是否存在于集合中,如果已经存在则直接返回告知客户端写入失败。
接下来就是通过位运算进行位或赋值。
get() 方法的计算逻辑和 set 类似,只要判断为 0 就直接返回存在该值。
mightContain 是否存在函数
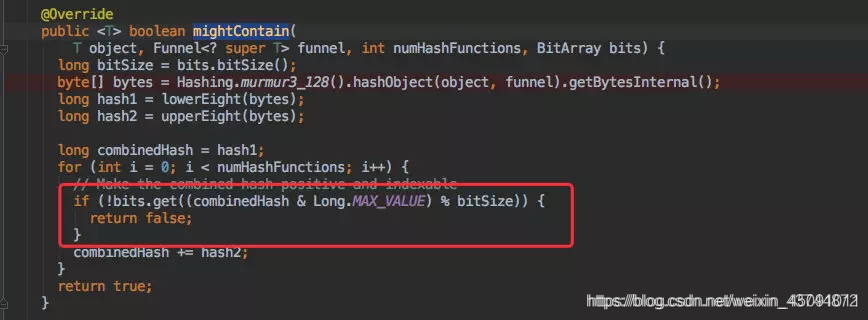
前面几步的逻辑都是类似的,只是调用了刚才的 get() 方法判断元素是否存在而已。
guava包的使用
Google的包中提供了一个Bloom过滤的实现,我们稍微用一下
maven
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
//java
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterTest {
public static void main(String[] args) {
//z字符串的编解码
Charset charset = Charset.forName("UTF8");
//你预计的元素的个数
long expectElementNum = 1000;
//你希望的出错率
double expectErrorRate = 0.1;
//这有很多类型比如,integerFunnel,doubleFunnel...
Funnel funnel = Funnels.stringFunnel(charset);
BloomFilter bloomFilter = BloomFilter.create(funnel, expectElementNum, expectErrorRate);
bloomFilter.put("aa");
bloomFilter.put("dd");
bloomFilter.put("bb");
bloomFilter.put("cc");
bloomFilter.put("ee");
bloomFilter.put("ff");
bloomFilter.put("gg");
bloomFilter.put("hh");
bloomFilter.put("kk");
bloomFilter.put("ii");
bloomFilter.put("jj");
//测试 : true
System.out.println(bloomFilter.test("bb"));
}
}
(布隆过滤器(Bloom Filter)原理及Guava中的具体实现)
总结
以上就是今天要讲的内容,本文讲解了布隆过滤器的产生、设计思路和应用场景,通过简单推导明确了其假阳性问题。另外,又通过阅读Guava中BloomFilter的相关源码,了解了设计布隆过滤器的技术要点。之后还会另外写文章讲述我们在生产环境中的具体应用。