双线性池化(Bilinear Pooling)
双线性池化,Bilinear Pooling出自于论文《Bilinear CNN Models for Fine-grained Visual Recognition》。双线性的意思是包含两个特征提取器,其输出经过外积相乘、池化然后得到结果。其主要用于特征融合,对于从同一个样本提取出来的特征x和特征y,通过bilinear pooling得到两个特征融合后的向量,进而用来分类。
丢个原文链接:https://arxiv.org/pdf/1504.07889.pdf
如果特征x和特征y来自两个特征提取器,被称为多模双线性池化(MBP, Multimodal Bilinear Pooling);如果特征x=特征y,则被称为同源双线性池化(HBP, Homogeneous Bilinear Pooling)或者二阶池化(Second-order Pooling)
对于图像![]() 在位置
在位置![]() 的两个特征
的两个特征![]() 和
和![]() ,进行如下操作:
,进行如下操作:
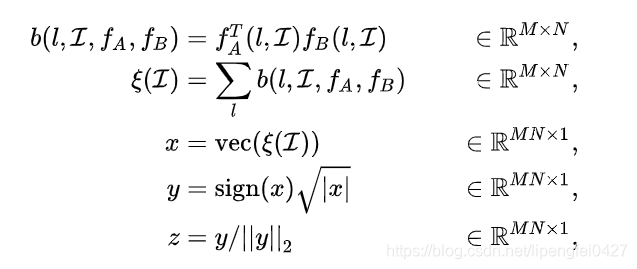
直观上理解,所谓bilinear pooling,就是先把在同一位置上的两个特征双线性融合(相乘)后,得到矩阵b,对所有位置的b进行sum pooling(也可以是max pooling,但一般采用sum pooling以方便进行矩阵运算)得到矩阵![]() ,最后把矩阵
,最后把矩阵![]() 张成一个向量,记为双线性向量 x 。对x进行矩归一化操作和L2归一化操作后,就得到融合后的特征 z。之后,就可以把特征z用于fine-grained分类了,如下图所示:
张成一个向量,记为双线性向量 x 。对x进行矩归一化操作和L2归一化操作后,就得到融合后的特征 z。之后,就可以把特征z用于fine-grained分类了,如下图所示:
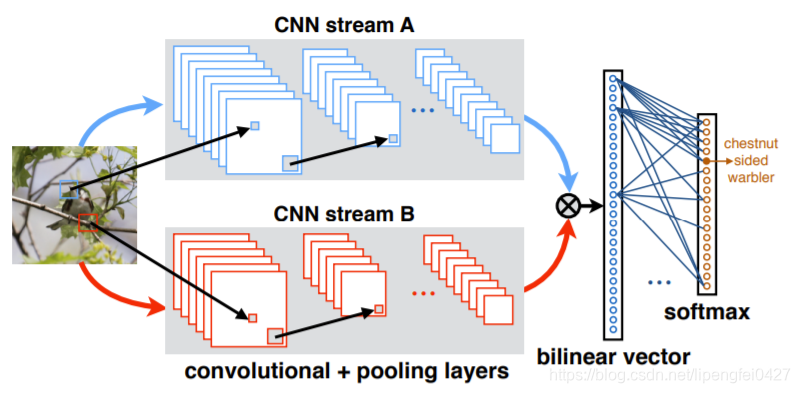
bilinear pooling形式比较简单,利于梯度反向传播,从而实现端到端的训练。
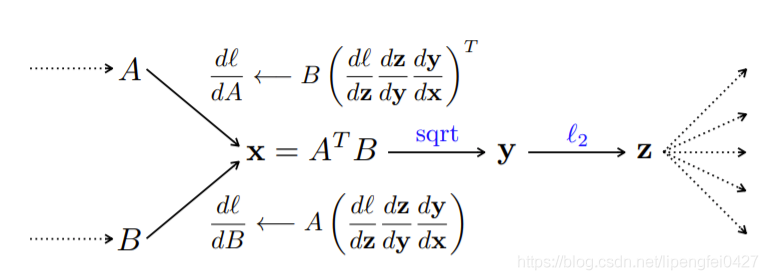
二阶池化(Second-order pooling)

Second-order Pooling最早出自ECCV2012的文章《Semantic segmentation with second-order pooling》,原文对Second-order Pooling的定义如下

![]() 和
和![]() 其实就是平均池化和最大池化,
其实就是平均池化和最大池化,![]() ·
·![]() 最终得到矩阵
最终得到矩阵 ![]() 。对比bilinear pooling的定义,不难发现,当
。对比bilinear pooling的定义,不难发现,当![]() 的时候,二者是等价的。也就是说,二阶池化(Second-order Pooling=同源双线性池化(HBP,Homogeneous Bilinear Pooling)。
的时候,二者是等价的。也就是说,二阶池化(Second-order Pooling=同源双线性池化(HBP,Homogeneous Bilinear Pooling)。
![]()
由于Second-order Pooling用到了特征![]() 的二阶信息,所以在一些任务下能比一阶信息表现更为优秀。
的二阶信息,所以在一些任务下能比一阶信息表现更为优秀。
附一下双线性池化的代码:
def bilinear_pooling(x,y):
x_size = x.size()
y_size = y.size()
assert(x_size[:-1] == y_size[:-1])
out_size = list(x_size)
out_size[-1] = x_size[-1]*y_size[-1] # 特征x和特征y维数之积
x = x.view([-1,x_size[-1]]) # [N*C,F]
y = y.view([-1,y_size[-1]])
out_stack = []
for i in range(x.size()[0]):
out_stack.append(torch.ger(x[i],y[i])) #torch.ger()向量的外积操作
out = torch.stack(out_stack) # 将list堆叠成tensor
return out.view(out_size) #[N,C,F*F]
原始的Bilinear Pooling存在融合后的特征维数过高的问题,融合后的特征维数=特征x和特征y的维数之积。为了改进这一点,后来基于降低bilinear pooling特征维数的思想,提出CBP,这就是后话了。
参考链接: