章要点:
谷歌分别研究了编码 - 解码模型中的每个模型设计因素,以隔离它们的影响。
编码 - 解码网络设计因素,诸如向量表示、编码器和解码器的深度,以及注意力机制等,及推荐设置和实验结果。
一组基本模型的设计思路,可以用作你自己的 sequence-to-sequence 项目的起点。
神经机器翻译的编码 - 解码模型
递归神经网络的编码 - 解码结构取代了传统的基于短语的统计机器翻译系统,取得了目前最好的结果。
谷歌目前在谷歌翻译服务中使用的核心技术便是来自于他们 2016 年的论文《Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation(谷歌神经机器翻译系统:缩小人类与机器翻译的差距)》。
论文链接:https://arxiv.org/abs/1609.08144
这种结构的一个问题是模型很大,需要非常大的数据集来训练。这就意味着模型训练往往需要数天或数周的时间,并且会消耗大量的计算资源。因此,很少有人研究不同设计因素对模型以及对模型的性能会带来怎样的影响。
Denny Britz 在 2017 年的论文《Massive Exploration of Neural Machine Translation Architectures(关于神经机器翻译架构的大规模探索)》中强调了这一问题。他们设计了一个标准的英语 - 德语翻译任务的基线模型,列举了一组不同的模型设计选择,并描述了它们对模型表现的影响。他们称完整的实验消耗了超过 250000 小时的 GPU 计算,可以说是令人印象深刻的。
论文链接:https://arxiv.org/abs/1703.03906
“我们报告了来自几百次实验运行的结果与变异数,这几百次实验即 GPU 上运行超过 250000 小时的标准 WMT 数据集英语到德语的翻译任务。我们的实验为构建和扩展 NMT 结构带来了新的见解和实用建议。”
在这篇文章中,我们也会介绍上述论文中的一些发现,我们可以借鉴他们的结果来调整我们自己的神经机器翻译模型,以及一般的 sequence-to-sequence 模型。
想了解编码 - 解码结构和注意力机制的更多背景,请阅读下列文章:
Encoder-Decoder Long Short-Term Memory Networks(编码 - 解码长短时记忆网络)
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
Attention in Long Short-Term Memory Recurrent Neural Networks(长短时记忆循环神经网络的注意力机制)
https://machinelearningmastery.com/attention-long-short-term-memory-recurrent-neural-networks/
基线模型
我们首先介绍所有实验中所用的基线模型。模型的基准配置如下,使其能较好地执行翻译任务。
向量表示(Embedding):512 维
RNN 单元:门控循环单元(Gated Recurrent Unit,GRU)
编码器:双向
编码器深度:2 层(每个方向各一层)
解码器深度:2 层
注意力机制:Bahdanau 提出的注意力机制
优化器:Adam
丢弃:输入的 20%
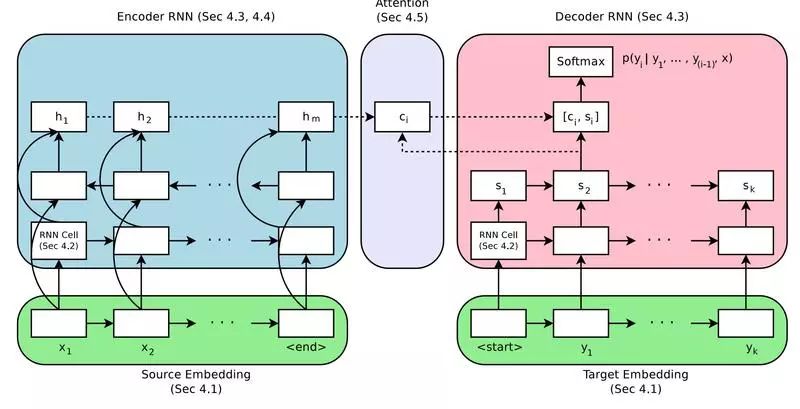
NMT 编码 - 解码模型
每个实验都由基线模型开始,每次改动一个因素以隔离其他设计因素对模型性能的影响,以 BLEU 得分作为评价标准。
向量表示的维度
向量表示(word-embedding),顾名思义,每一个输入编码器的单词都有一个对应的向量(往往是低维的)表示。
这是一个分布式表示,每个单词被映射到一个固定大小的连续值向量。这种方法的好处是,具有相似含义的不同词语会有相似的表示。
这种分布式表示通常是在模型拟合数据的过程中学习得到的。向量表示的维度指用来表示单词的向量的长度。一般认为,向量的维度越大,其表现力越强,从而也能使模型有更好的性能。
有趣的是,结果表明,向量维度最大的实验确实取得了最好的结果,但是增加维度所带来的模型提升较小。
“【结果表明】2048 维的向量表示能产生最好的结果,它们只得到了很小的提升。即使小到 128 维的向量表示也能取得惊人的结果,而且收敛速度是高维向量的两倍。”
推荐设置:实验开始用小向量,例如 128 维,随后可以考虑增加向量表示维度来略微提升模型性能。
RNN 单元类型
有三种常用的 RNN 单元:
简单 RNN
长短时记忆(LSTM)
门控循环单元(GRU)
简单 RNN 会出现梯度消失问题,从而限制了网络较深的 RNN 的训练,LSTM 是针对该问题而设计的。GRU 的出现是为了简化 LSTM。
实验结果表明,GRU 和 LSTM 的表现明显优于简单的 RNN,但通常 LSTM 表现最佳。
“实验中,LSTM 单元的性能始终优于 GRU 单元。”
推荐设置:在模型中使用 LSTM 单元。
解码 - 编码网络深度
一般来说,较深的网络比浅层网络性能更好。
关键是要在网络深度、模型性能和训练时长之间找到一个平衡点。这是当性能表现的提升成为次要因素时,网络通常已经达到足够的深度,而我们通常没有这样的资源来训练非常深的网络。
对于编码器来说,研究人员发现网络深度对于性能并没有很大的影响,更令人惊讶的是,1 层双向模型的表现比 4 层双向模型还要稍好一些。两层双向编码器比其他配置的测试稍微好一些。
“我们没有发现明确的证据表明编码器的深度有必要超过 2 层。”
推荐设置:使用 1 层双向编码器,如果想要性能稍有提升,可以扩展至 2 层双向编码器。
解码器也符合类似的规律。1、2、4 层解码器之间的性能只是略有不同,4 层解码器略微好些。在测试条件下,8 层解码器出现了不收敛的情况。
“在解码器方面,更深的模型以较小的优势胜过较浅的网络。”
推荐设置:用 1 层解码器作为出发点,并利用 4 层解码器获得更好的结果。
编码器输入序列顺序
源文本序列的顺序可以通过多种方式提供给编码器:
前向(普通)
反向
同时前向和反向
作者探讨了不同输入序列顺序的情况下,单向和双向配置对模型性能的影响。
他们证实了先前的研究,即倒序输入比正序输入更好,而且双向编码器比单向倒序输入稍微好一些。
“双向编码器一般优于单向编码器,但幅度不是很大。输入文本倒序的编码器始终优于正序的编码器。”
推荐设置:使用倒序输入,或者用双边编码器来提升模型性能。
注意力机制
注意力机制是对模型的一种改进,使得解码器在输出每个单词时,对输入序列的不同词语“赋予不同的注意力”。
作者研究了简单注意力机制的一些变体。结果表明,加入注意力机制的模型比不加注意力机制的模型性能有惊人的提升。
“虽然我们确实期望基于注意力的模型能显著优于那些没有注意力机制的模型,但那些没有注意力模型的糟糕程度令人感到惊讶。”
Bahdanau 等人在其 2015 年的论文《Neural machine translation by jointly learning to align and translate(联合学习标定和翻译的神经机器翻译)》中所描述的简单的加权平均注意力机制是目前实验结果最好的。
推荐设置:使用注意力机制,并且最好是用 Bahdanau 提出的加权平均法。
推断
在神经机器翻译系统中,常用束搜索(beam-search)来采样模型输出单词的概率。束宽度越宽,搜索就越彻底,大家普遍认为结果也越好。实验结果表明,束宽度为 3-5 的性能最好,通过长度惩罚只能得到很小的提升。作者建议根据每个具体问题调整束宽度。
“我们发现,一个好的束搜索是取得好结果的关键,而且它带来的 BLEU 分数提升不止一个点。”
推荐设置:从贪婪搜索开始(beam= 1),并根据问题进行微调。
最终模型
作者将他们的发现结合起来,形成一个“最佳模型”,并将该模型的结果与其他性能良好的模型和最先进的结果进行比较。
下表中总结了该模型的具体设置。当你为 NLP 应用程序开发自己的编码 - 解码模型时,可以将这些参数作为一个很好甚至是最好的起点。
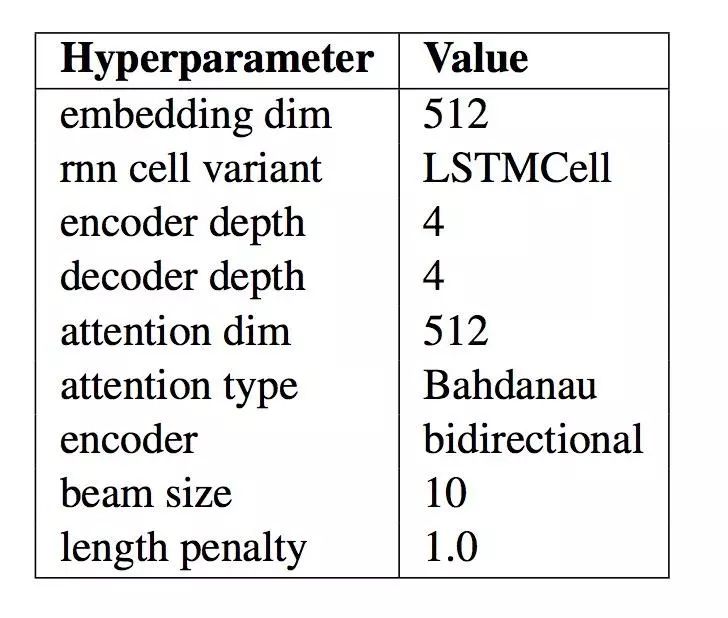
最终 NMT 模型参数设置
该系统的实验结果令人印象深刻,作者用更简单的模型取得了接近目前最先进的结果,而这本来不是论文的目标。
“我们证明,通过细致地超参数调整和良好地初始化,可以在 WMT 基准数据集上达到最先进的性能表现”
重要的是,作者提供了他们所有的代码作为开源项目——tf-seq2seq。因为两位作者是谷歌大脑实习项目的成员,谷歌研究院的博客上发布了他们的工作:Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow,2017。
深度阅读
如果您想深入了解该话题,推荐阅读下列文章:
Massive Exploration of Neural Machine Translation Architectures,2017
Denny Britz 主页
WildML 博客
Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in
TensorFlow, 2017
tf-seq2seq: A general-purpose encoder-decoder framework for Tensorflow
tf-seq2seq Project Documentation
tf-seq2seq Tutorial: Neural Machine Translation Background
Neural machine translation by jointly learning to align and translate, 2015.
总结
在这篇文章中,我们介绍了如何配置编码 - 解码递归神经网络的参数,使其在神经机器翻译和其他自然语言处理任务中取得更好的性能。