动图很长

代码
import numpy as np
import matplotlib.pyplot as pyp
OUTPUT = 'output'
SUM = 'sum'
INPUT = 'input'
EXPECT = 'exp'
WEIGHT = 'weight'
LOST = 'lost'
START = 'start'
END = 'end'
B = 1.0
def af(v):
"""激励函数。
Args:
v (matrix): 自变量
Returns:
matrix: 函数值。
"""
return 1/(1+np.exp(-v))
def af_d(v):
"""激励函数的导数。
Args:
v (matrix): 自变量
Returns:
matrix: 函数值。
"""
d = af(v)
return np.multiply(d, 1.0-d)
def loss(y_hat, y):
"""交叉熵损失函数。
Args:
y_hat (matrix): 观测结果即神经网络输出层返回值
y (matrix): 模型输出
Returns:
float: 计算模型输出和观测结果间的差异。
"""
ret = []
row_count, col_count = y_hat.shape
for row_index in range(row_count):
y_hat_row_t = y_hat[row_index, ].T
left = np.dot(-y, np.log(y_hat_row_t))
right = np.dot((np.array([[1]]) - y), np.log(1 - y_hat_row_t))
res = np.sum(left-right)
ret.append(res)
pass
return ret
def init_weights(*widths):
"""初始化权值。
Returns:
list: 初始权值。
"""
weights = []
depth = len(widths)
for i in range(1, depth):
miu = np.sqrt(1/widths[i])
w = miu * np.random.randn(widths[i], widths[i-1]+1)
weights.append(np.mat(w))
pass
return weights
def fp_layer(input, weights):
"""单层前向传播。
Args:
input (matrix): 本层输入值,每一行表示对前一层一个神经元的输出
weights (matrix): 本层权值
Returns:
dict: 包含本层输入值(包含额外输入),本层加权求和和非线性变换结果。
"""
iab = np.insert(np.mat([[B]]), [1], input, axis=0)
sums = np.dot(weights, iab)
res = af(sums)
return {
INPUT: iab, SUM: sums, OUTPUT: res}
def bp_layer(exp, weights, sum, inputs):
"""单层BP
Args:
exp (matrix)): 本层模型输出,每一行表示本层一个神经元的模型输出
weights (matrix): 本层权值
sum (matrix): 前层加权求和结果
inputs (matrix): 本层输入值(包含额外输入)
Returns:
dict: 前层模型输出和权值变化量。
"""
delta_weights = np.dot(exp, inputs.T)
grad = af_d(sum)
propagate = np.dot(weights.T[1:], exp)
propagate = np.multiply(grad, propagate)
return{
EXPECT: propagate, WEIGHT: delta_weights}
def fit(data, weights):
"""对单个数据拟合。
Args:
data (dict): 包含输入和模型输出
weights (list): 神经网络权值
Returns:
dict: 包含观测结果和权值变化量。
"""
depth = len(weights)
fp_results = []
input = data[INPUT]
for i in range(depth):
fp_res = fp_layer(input, weights[i])
fp_results.append(fp_res)
input = fp_res[OUTPUT]
pass
delta_weights = []
exp = input - data[EXPECT]
for i in reversed(range(depth)):
net = fp_results[i-1][SUM]
bp_res = bp_layer(exp, weights[i], net, fp_results[i][INPUT])
exp = bp_res[EXPECT]
delta_weights.append(bp_res[WEIGHT])
pass
delta_weights.reverse()
return{
OUTPUT: input, WEIGHT: delta_weights}
times = 3000
eta = 0.25
data_inputs = [[1, 0], [1, 1], [0, 1], [0, 0]]
data_outputs = [[1], [0], [1], [0]]
data_size = len(data_inputs)
weights = init_weights(2, 3, 1)
depth = len(weights)
result = {
LOST: [], START: None, END: []}
for t in range(times):
delta_weights = []
res = []
for data_index in range(data_size):
data = {
INPUT: np.mat([data_inputs[data_index]]).T,
EXPECT: np.mat([data_outputs[data_index]]).T}
fit_res = fit(data, weights)
delta_weights.append(fit_res[WEIGHT])
res.append(fit_res[OUTPUT].T.tolist()[0])
pass
if result[START] is None:
result[START] = res
result[END] = res
lost = loss(np.mat(res).T, np.mat(data_outputs).T)
result[LOST].append(np.dot(1/data_size, lost))
for delta_weight in delta_weights:
for layerIndex in range(depth):
layer = delta_weight[layerIndex]
weights[layerIndex] -= np.dot(eta, layer)
pass
pass
pass
print('\033[31m', '训练前输出:', np.mat(result[START]).T, '\033[0m')
print('\033[35m', '训练后输出:', np.mat(result[END]).T, '\033[0m')
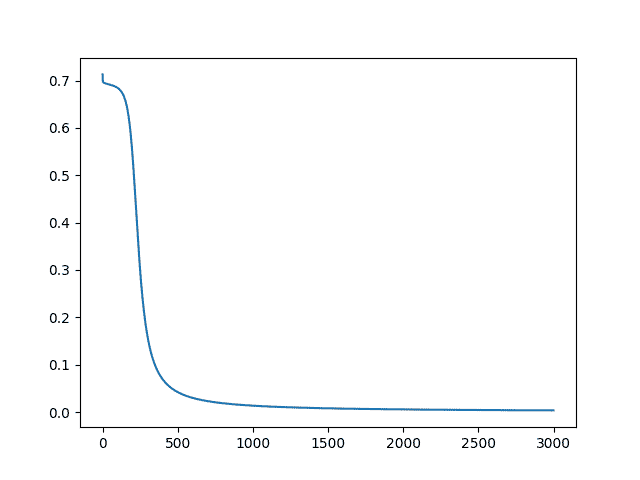
pyp.plot(result[LOST])
pyp.show()
输出
训练前输出: [[0.57172222 0.55289663 0.61069527 0.63006013]]
训练后输出: [[0.99686652 0.00336393 0.9959174 0.00293138]]
用tensorflow实现代码更短:戳我跳转