文章目录
前言
需要开通vip的题目暂时跳过
笔记导航
点击链接可跳转到所有刷题笔记的导航链接
682. 棒球比赛
你现在是一场采用特殊赛制棒球比赛的记录员。这场比赛由若干回合组成,过去几回合的得分可能会影响以后几回合的得分。
比赛开始时,记录是空白的。你会得到一个记录操作的字符串列表 ops,其中 ops[i] 是你需要记录的第 i 项操作,ops 遵循下述规则:
- 整数 x - 表示本回合新获得分数 x
- “+” - 表示本回合新获得的得分是前两次得分的总和。题目数据保证记录此操作时前面总是存在两个有效的分数。
- “D” - 表示本回合新获得的得分是前一次得分的两倍。题目数据保证记录此操作时前面总是存在一个有效的分数。
- “C” - 表示前一次得分无效,将其从记录中移除。题目数据保证记录此操作时前面总是存在一个有效的分数。
请你返回记录中所有得分的总和。

-
解答
public int calPoints(String[] ops) { Stack<Integer> stack = new Stack<>(); int res = 0; for(int i = 0;i < ops.length;i++){ if(ops[i].equals("C")){ res -= stack.pop(); } else if(ops[i].equals("D")){ Integer peek = stack.peek(); res += peek * 2; stack.push(peek * 2); } else if(ops[i].equals("+")){ Integer pop = stack.pop(); Integer pop2 = stack.pop(); res += pop + pop2; stack.push(pop2); stack.push(pop); stack.push(pop + pop2); } else { int score = Integer.valueOf(ops[i]); res += score; stack.push(score); } } return res; } -
分析
- 栈来模拟得分的顺序
-
提交结果

684. 冗余连接
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。

-
解答
public int[] findRedundantConnection(int[][] edges) { int nodesCount = edges.length; int[] parent = new int[nodesCount + 1]; int[] sz = new int[nodesCount + 1]; for (int i = 1; i <= nodesCount; i++) { parent[i] = i; sz[i] = i; } for (int i = 0; i < nodesCount; i++) { int[] edge = edges[i]; int node1 = edge[0], node2 = edge[1]; if (find(parent, node1) != find(parent, node2)) { union(parent,sz, node1, node2); } else { return edge; } } return new int[0]; } public void union(int[] parent,int[] sz, int index1, int index2) { int p = find(parent,index1); int q = find(parent,index2); if(sz[p] > sz[q]){ sz[p] += sz[q]; parent[q] = p; }else{ sz[q] += sz[p]; parent[p] = q; } } public int find(int[] parent, int index) { if (parent[index] != index) { parent[index] = find(parent, parent[index]); } return parent[index]; } -
分析
- 并查集
- 遍历边集合,维护并查集,当两个点的父亲相同,说明他们已经在树中出现了,则直接返回这条边
-
提交结果

686. 重复叠加字符串匹配
给定两个字符串 a 和 b,寻找重复叠加字符串 a 的最小次数,使得字符串 b 成为叠加后的字符串 a 的子串,如果不存在则返回 -1。
注意:字符串 “abc” 重复叠加 0 次是 “”,重复叠加 1 次是 “abc”,重复叠加 2 次是 “abcabc”。

-
解答
public int repeatedStringMatch(String a, String b) { if(a.contains(b)){ return 1; } int min = b.length()/a.length(); StringBuilder sb = new StringBuilder(); for(int i = 1; i <= min+2; i++){ sb.append(a); if(i>=min && sb.toString().contains(b)){ return i; } } return -1; } -
分析
-
思路:假设a为abc,b的为cabcabca,这时候b/a=2,就是最少要放两个a,可能a能包含b【此例子不成立,加上后面的条件才能得出答案,这一步只做粗筛选】
- 如果刚好取的是完整的a字符串,那么,直接取b/a这个长度就可以了,例子:abc abcabc,此时取2;
- 如果前面取的是不完整的a字符串,如abc cabcabc,这时候除完要加一个;同理,abc abcabca也要加一个,取3;
- 如果前后都是不完整的a字符串,如abc cabcabca,则前后都加一个才能拿到b,此时取4;
综上,只有b/a,b/a+1,b/a+2这三个数可能是正确答案,如果三个数都找不到,那就没有答案了。
-
-
提交结果

687. 最长同值路径
给定一个二叉树,找到最长的路径,这个路径中的每个节点具有相同值。 这条路径可以经过也可以不经过根节点。
注意:两个节点之间的路径长度由它们之间的边数表示。

-
解答
int res = 0; public int longestUnivaluePath(TreeNode root) { dfs(root); return res; } Map<Integer,Integer> map = new HashMap<>(); public int dfs(TreeNode root) { if(root == null)return 0; int left = 0,right = 0; if(root.left != null){ if(root.val == root.left.val){ left += 1 + dfs(root.left); }else{ dfs(root.left); } } if(root.right != null){ if(root.val == root.right.val){ right += 1 + dfs(root.right); }else{ dfs(root.right); } } res = Math.max(res,left + right); return Math.max(left,right); } -
分析
- dfs实现
- 递归判断同值路径的长度
- 若左孩子不为空,并且左孩子的值等于当前结点的值,那么左边路径 + 1 并递归的判断左子树
- 若右孩子不为空,并且右孩子的值等于当前结点的值,那么右边路径 + 1 并递归的判断右子树
- 当前结点的同值路径,就是左路径+右路径
- 返回给上一层结点的路径是左路径和右路径长度的较大者
-
提交结果

688. “马”在棋盘上的概率
已知一个 NxN 的国际象棋棋盘,棋盘的行号和列号都是从 0 开始。即最左上角的格子记为 (0, 0),最右下角的记为 (N-1, N-1)。
现有一个 “马”(也译作 “骑士”)位于 (r, c) ,并打算进行 K 次移动。
如下图所示,国际象棋的 “马” 每一步先沿水平或垂直方向移动 2 个格子,然后向与之相垂直的方向再移动 1 个格子,共有 8 个可选的位置。
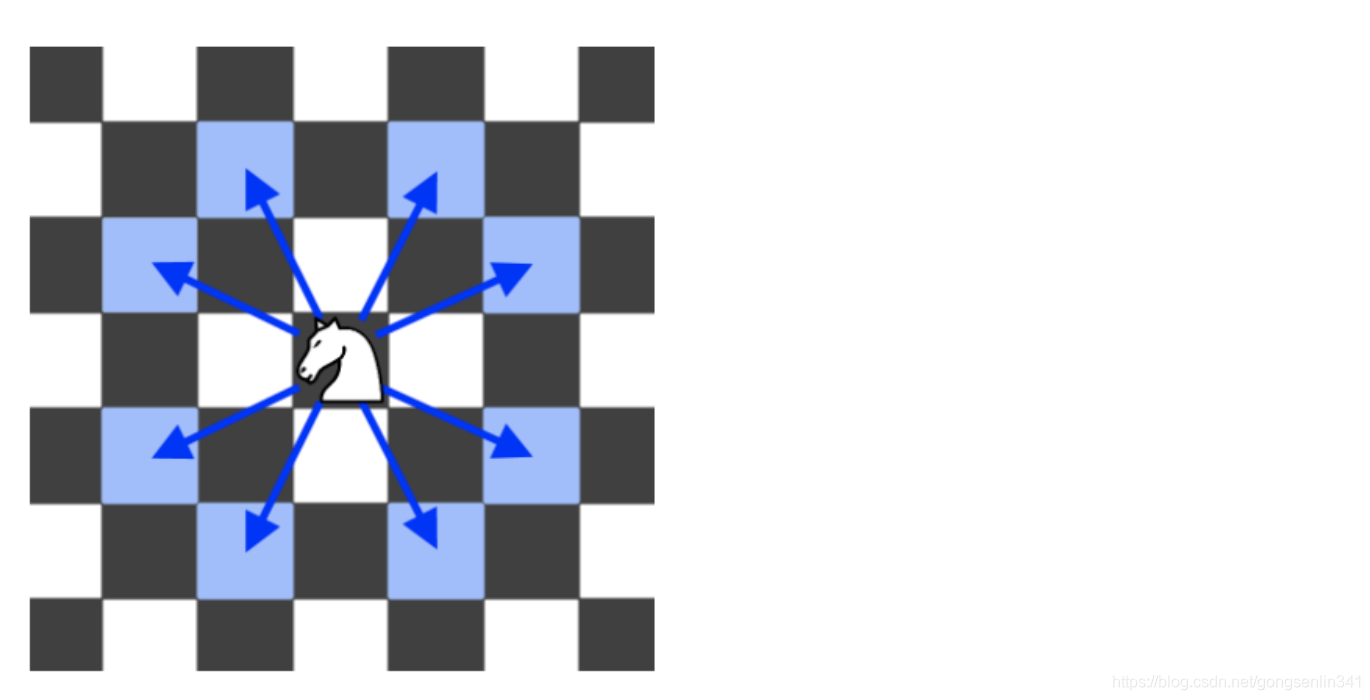
现在 “马” 每一步都从可选的位置(包括棋盘外部的)中独立随机地选择一个进行移动,直到移动了 K 次或跳到了棋盘外面。
求移动结束后,“马” 仍留在棋盘上的概率。

-
解答
//方法1 public double knightProbability(int N, int K, int rIndex, int cIndex) { int[][] f = new int[][]{ { -2,1},{ -1,2},{ 1,2},{ 2,1},{ 2,-1},{ 1,-2},{ -1,-2},{ -2,-1}};//8个方向 double[][][] memo = new double[N][N][K + 1]; return dfs(N,K,rIndex,cIndex,memo,f); } public double dfs(int N,int K,int rIndex,int cIndex,double[][][] memo,int[][] f){ if(rIndex < 0 || rIndex >= N || cIndex < 0 || cIndex >= N) return 0; if(K==0) return 1; if(memo[rIndex][cIndex][K] != 0)return memo[rIndex][cIndex][K]; double res = 0; for(int i = 0;i < 8;i++){ res += dfs(N,K-1,rIndex + f[i][0],cIndex + f[i][1],memo,f); } memo[rIndex][cIndex][K] = res / 8; return res / 8; } //方法2 public double knightProbability(int N, int K, int rIndex, int cIndex) { int[][] f = new int[][]{ { -2,1},{ -1,2},{ 1,2},{ 2,1},{ 2,-1},{ 1,-2},{ -1,-2},{ -2,-1}};//8个方向 double[][][] dp = new double[N][N][K+1]; for (int r = 0; r < N; r++) { for (int c = 0; c < N; c++) { dp[r][c][0] = 1; } } for(int k = 1; k<= K;k++){ for(int r = 0;r < N;r++){ for(int c = 0;c < N;c++){ for(int i = 0;i < 8;i++){ dp[r][c][k] += (r + f[i][0] >= 0 && r + f[i][0] < N && c + f[i][1] >= 0 && c + f[i][1] < N) ? dp[r + f[i][0]][c + f[i][1]][k - 1]: 0; } dp[r][c][k] /= 8; } } } return dp[rIndex][cIndex][K]; } -
分析
- 方法1 记忆化递归
- 递归出口,越界 返回0,K == 0 返回1,存在记忆 返回记忆
- dfs求8个方向存活的概率
- 记忆集记录 8个方向存活的概率之和 / 8
- 返回res/8
- 方法2 动态规划
- dp[i] [j] [k]表示 在位置i,j 走k步存活的概率
- 初始化 dp[i] [j] [0] = 1
- 然后遍历步数k等1 开始 到k
- 枚举所有的位置
- 动态转移方程为 dp[i] [j] [k] = 其他8个方向的k-1步的概率之和 除以8
- 最后返回dp[rIndex] [cIndex] [K]即可
-
提交结果
方法1

方法2

689. 三个无重叠子数组的最大和
给定数组 nums 由正整数组成,找到三个互不重叠的子数组的最大和。
每个子数组的长度为k,我们要使这3*k个项的和最大化。
返回每个区间起始索引的列表(索引从 0 开始)。如果有多个结果,返回字典序最小的一个。

-
解答
public int[] maxSumOfThreeSubarrays(int[] nums, int k) { int L = nums.length; int[] sum = new int[nums.length+1]; for(int i = 0; i < L; i++) { sum[i+1] = sum[i]+nums[i]; } // value up to j-th element and with i sub-arrays int[][] dp = new int[4][L+1];//dp[i][j]表示 在j为止 有i组k大小的子数组和的最大值 for(int i = 1; i < 4; i++) { for(int j = k; j <= L; j++) { dp[i][j] = Math.max(dp[i][j-1], dp[i-1][j-k] + sum[j]-sum[j-k]); } } int[] ret = new int[3]; int max = Arrays.stream(dp[3]).max().getAsInt();//3组子数组和的最大值 for(int i = 3; i >= 1; i--) { //遍历子数组的个数 从3->1 for(int j = 1; j <= L; j++) { //从前往后找,第一次出现的最大值 if(dp[i][j] == max){ ret[i-1] = j-k;//记录下最大值数组的起始位置 max -= sum[j]-sum[j-k];// 更新最大值,找下一个子数组和的最大值,例如刚才是找3组 现在是找2组的 break; } } } return ret; } -
分析
- 动态规划+前缀和
- dp[i] [j]表示第j个元素结尾的数组中,有i组k大小的子数组 和的最大值
- 首先计算前缀和 保存在sum数组当中
- 然后动态转移,更新dp[i] [j]
- dp[i] [j] 有2种方式可以转移过来
- dp[i] [j-1] 已经有i组k大小的子数组的最大值
- dp[i-1] [j-k] + sum[j] - sum[j-k] 表示在j位置往前以k个元素结尾的地方,存在i-1组k大小的子数组和的最大值,那么 j-k ~ j的位置就是第i组子数组。
- 取上面两者中的较大值
- 根据dp数组 得到3组k大小子数组的最大值
- 从前往后遍历,找到3组k大小子数组和的最大值最先出现的位置,此时遍历到的位置是j,那么这个子数组的起始的位置就是j-k。所以记录下j-k
- 然后就是要找2组k大小数组和的最大值,所以需要更新这个最大值,根据7中得到的第三组的位置,可以得到第三组的区间和,将最大值减去第三组的区间和。得到前两组子数组和的最大值。
- 接着从前往后遍历,找到2组k大小子数组和的最大值最先出现的位置,同上面的过程,记录下起始位置并更新最大值,再找第一组k大小子数组和的最大值,记录下起始位置,得到结果。
-
提交结果

690. 员工的重要性
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。

-
解答
Map<Integer,Employee> map = new HashMap<>(); public int getImportance(List<Employee> employees, int id) { int res = 0; for(Employee employee : employees){ map.put(employee.id,employee); } for(Employee employee : employees){ if(employee.id == id){ return dfs(employee); } } return 0; } public int dfs(Employee employee){ int res =employee.importance; for(Integer i:employee.subordinates){ res += dfs(map.get(i)); } return res; } -
分析
- 先将所有的员工存入hashMap当中,id作为key,Employee作为value
- 遍历员工表,找到目标id员工
- 递归的遍历他底下的员工的信息,将importance累计
-
提交结果

691. 贴纸拼词
我们给出了 N 种不同类型的贴纸。每个贴纸上都有一个小写的英文单词。
你希望从自己的贴纸集合中裁剪单个字母并重新排列它们,从而拼写出给定的目标字符串 target。
如果你愿意的话,你可以不止一次地使用每一张贴纸,而且每一张贴纸的数量都是无限的。
拼出目标 target 所需的最小贴纸数量是多少?如果任务不可能,则返回 -1。

-
解答
public static int minStickers(String[] stickers, String target) { // 过滤判断:如果target中存在贴纸集中没有的字母,直接返回-1 if (existLetterNotInStickers(stickers, target)) return -1; int[][] stickerMap = new int[stickers.length][26]; // stickerMap[i]:表示第i号贴纸stickers[i] // 将贴纸集转换成字母频率表示,放入stickerMap for (int i = 0; i < stickers.length; i++) { for (char c : stickers[i].toCharArray()) { stickerMap[i][c-'a']++; } } // 记忆化搜索 target -> 最少贴纸数 HashMap<String, Integer> memo = new HashMap<>(); return minStickers(stickerMap, target, memo); } // stickerMap:贴纸集 // target:rest target,要搞定的剩余目标 // 返回搞定target所需要的最少贴纸数 private static int minStickers(int[][] stickerMap, String target, HashMap<String, Integer> memo) { if (memo.containsKey(target)) return memo.get(target); if (target.length() == 0) { memo.put("", 0); return 0; } char[] targetLetters = target.toCharArray(); // target int[] targetWord = new int[26]; // 以字母频率方式表示target for (char c : targetLetters) { targetWord[c-'a']++; } int minCount = Integer.MAX_VALUE; // 枚举第1张使用哪种贴纸 for (int i = 0; i < stickerMap.length; i++) { int[] sticker = stickerMap[i]; // 决定使用i号贴纸 // 能否使用这种贴纸? // 如果这种贴纸是"aaabbb",而target是"xyz",使用这种贴纸啥也搞定不了,递归下去就是死循环 // 如果使用这种贴纸,target中至少得有一种字母在这种贴纸中,如果target中的字母在sticker中都不存在,搞定个锤子 if (notContainAnyLetter(sticker, targetLetters)) continue; // 计算使用这张贴纸后,新的target是啥 // 26种字母依次处理,得到每种字母处理后的字母频率表targetWord StringBuilder sb = new StringBuilder(); for (int j = 0; j < 26; j++) { // 如果目标中包含这种字母,使用1张贴纸后,计算这种字母还剩多少个 int restCount = targetWord[j]; if (targetWord[j] != 0) { restCount = targetWord[j] > sticker[j] ? targetWord[j] - sticker[j] : 0; } // 将字母频率转成String:将这种字母添加到StringBuilder for (int k = 0; k < restCount; k++) { sb.append((char)(j+'a')); } } String restTarget = sb.toString(); // 使用完第1张贴纸后,剩余目标 int next = minStickers(stickerMap, restTarget, memo); // 【递归】后续需要的贴纸数量 if (next != -1) minCount = Math.min(minCount, next + 1); // 后续过程有效,当前这种方案(使用i号贴纸作为第1张),是一种有效方案 } int ans = minCount == Integer.MAX_VALUE ? -1 : minCount; memo.put(target, ans); return ans; } // 【贪心优化】 // 如果target中的字母在sticker中都不存在,返回true // 如果target中至少存在一种字母在sticker中,返回false private static boolean notContainAnyLetter(int[] sticker, char[] target) { char toCheckLetter = target[0]; return sticker[toCheckLetter-'a'] == 0; } // 判断target中是否含有贴纸集stickers中没有的字母,如果存在,返回true private static boolean existLetterNotInStickers(String[] stickers, String target) { int[] stickersLetters = new int[26]; for (String sticker : stickers) { for (char letter : sticker.toCharArray()) { stickersLetters[letter-'a']++; } } for (char letter : target.toCharArray()) { if (stickersLetters[letter-'a'] == 0) return true; } return false; } -
分析
- 记忆化递归
- 首先判断target当中是否存在某个字母 在stickers当中没有出现过,如果存在的话,直接返回-1
- 将stickers转换成字母数量统计表示
- 开始记忆化递归,记忆集用HashMap,字符串作为key,需要的贴纸的数量为value
- 用字母数量统计方式表示target
- 枚举贴纸,使用了这张贴纸后,得到剩余的目标,递归的计算,得到的结果放入记忆集。
-
提交结果

692. 前K个高频单词
给一非空的单词列表,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。

-
解答
class Solution { public List<String> topKFrequent(String[] words, int k) { List<String> res = new ArrayList<>(); Map<String,Integer> map = new HashMap<>(); for(int i = 0;i < words.length;i++){ map.put(words[i],map.getOrDefault(words[i],0)+1); } PriorityQueue<Letter> queue = new PriorityQueue<>(new Comparator<Letter>(){ public int compare(Letter l1,Letter l2){ if(l1.number != l2.number){ //频率不同,从大到小排 return l2.number - l1.number; } int minL = Math.min(l1.letter.length(),l2.letter.length()); for(int i = 0;i < minL;i++){ //遍历 if(l1.letter.charAt(i) == l2.letter.charAt(i))continue; return l1.letter.charAt(i) - l2.letter.charAt(i);//若字母不同,按字母顺序排序 } return l1.letter.length() - l2.letter.length();//上面两个都相同的情况下,比较两个单词的长度。短的排前面 } }); for(String key:map.keySet()){ queue.add(new Letter(key,map.get(key))); } while(k > 0){ res.add(queue.poll().letter); k--; } return res; } } class Letter{ String letter; int number; public Letter(String letter,int number){ this.letter = letter; this.number = number; } } -
分析
- 利用堆来维护出现频率的高低以及字符顺序的排序。
- 首先用map,统计单词出现的频率
- 然后用优先级队列,模拟堆,来维护要求的排序。
- 最后取堆中前k个即可
-
提交结果

693. 交替位二进制数
给定一个正整数,检查它的二进制表示是否总是 0、1 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。

-
解答
public boolean hasAlternatingBits(int n) { int last = n & 1; while(n >= 1){ n = n >> 1; int cur = n & 1; if(cur == last)return false; last = cur; } return true; } -
分析
- 每次右移一位,然后与1 做与运算,就可以得到当前最后一位是1 还是0.然后和上一次的进行比较。
- 如果相同返回false;
-
提交结果

695. 岛屿的最大面积
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)

-
解答
int[] f = { 1,0,-1,0,1}; public int maxAreaOfIsland(int[][] grid) { int res = 0; for(int i = 0;i < grid.length;i++){ for(int j = 0;j < grid[0].length;j++){ if(grid[i][j] != 0) res = Math.max(res,dfs(grid,i,j)); } } return res; } public int dfs(int[][] grid,int r,int c){ if(r < 0 || r >= grid.length || c < 0 || c >= grid[0].length || grid[r][c] == 0)return 0; int res =1 grid[r][c] = 0;//清空,避免重复计算 for(int i = 0;i < 4;i++){ //4个方向 res += dfs(grid,r + f[i],c + f[i+1]); } return res; } -
分析
- dfs 找连通的面积
- 枚举所有不为0的点,根据dfs 找到这个点连通的岛屿的面积,保留最大值
- 遍历过的点,设置为0,这样可以减少dfs的次数,避免重复的计算。
-
提交结果

696. 计数二进制子串
给定一个字符串 s,计算具有相同数量 0 和 1 的非空(连续)子字符串的数量,并且这些子字符串中的所有 0 和所有 1 都是连续的。
重复出现的子串要计算它们出现的次数。

-
解答
public int countBinarySubstrings(String s) { int zeroIndex = -1,zeroNumber = 0,oneIndex = -1,oneNumber = 0; char[] chars = s.toCharArray(); int index = 0,res = 0; while(index < chars.length){ if((chars[index] == '0' && oneIndex > zeroIndex) || (chars[index] == '1' && zeroIndex > oneIndex)){ res += Math.min(zeroNumber,oneNumber); } if(chars[index] == '0'){ if(zeroIndex == -1){ zeroIndex = index; zeroNumber = 1; }else{ if(zeroIndex > oneIndex){ zeroIndex++; zeroNumber++; }else{ zeroIndex = index; zeroNumber = 1; } } }else{ if(oneIndex == -1){ oneIndex = index; oneNumber = 1; }else{ if(oneIndex > zeroIndex){ oneIndex++; oneNumber++; }else{ oneIndex = index; oneNumber = 1; } } } index++; } res += Math.min(oneNumber,zeroNumber); return res; } -
分析
- 一次遍历,统计连续的1和连续的0的个数,当出现不连续的时候,则根据前面统计的1和0的数量取较小者,累计求和就是要找的目标数的个数。
- 例如 110001。遍历到第5个数字的时候,则根据前面统计的1和0的数量取较小者。11000 由2个1,3个0 所以 满足条件的数字是Math.min(2,3) = 2
- 遍历第五个数字,重新开始计算1的个数。
- 重复以上的过程。就可以得到结果。
-
提交结果

697. 数组的度
给定一个非空且只包含非负数的整数数组 nums, 数组的度的定义是指数组里任一元素出现频数的最大值。
你的任务是找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。

-
解答
public int findShortestSubArray(int[] nums) { if(nums.length < 2)return nums.length; int[] counts = new int[50000]; int[] first = new int[50000]; int[] dis = new int[50000]; int max = 0; Arrays.fill(first,-1); int maxNumber = 0; for(int i = 0;i < nums.length;i++){ maxNumber = Math.max(maxNumber,nums[i]); counts[nums[i]]++; max = Math.max(max,counts[nums[i]]); if(first[nums[i]] == -1){ first[nums[i]] = i; }else{ dis[nums[i]] = i - first[nums[i]] + 1; } } int res = Integer.MAX_VALUE; for(int i = 0;i <= maxNumber;i++){ if(counts[i] == max){ res = Math.min(res,dis[i]); } } return res == 0 ? 1 : res; } -
分析
- 准备3个数组
- counts用于统计数字出现的次数,first用于记录数字第一次出现的位置,dis用于记录某数字全部出现的最短子数组的长度。
- 一次遍历,维护上面三个数组,并记录下最大的数字
- 第二次遍历,0~最大数字
- 判断数字的个数满足max的最短的子数组的长度。
-
提交结果

699. 掉落的方块
在无限长的数轴(即 x 轴)上,我们根据给定的顺序放置对应的正方形方块。
第 i 个掉落的方块(positions[i] = (left, side_length))是正方形,其中 left 表示该方块最左边的点位置(positions[i][0]),side_length 表示该方块的边长(positions[i][1])。
每个方块的底部边缘平行于数轴(即 x 轴),并且从一个比目前所有的落地方块更高的高度掉落而下。在上一个方块结束掉落,并保持静止后,才开始掉落新方块。
方块的底边具有非常大的粘性,并将保持固定在它们所接触的任何长度表面上(无论是数轴还是其他方块)。邻接掉落的边不会过早地粘合在一起,因为只有底边才具有粘性。
返回一个堆叠高度列表 ans 。每一个堆叠高度 ans[i] 表示在通过 positions[0], positions[1], …, positions[i] 表示的方块掉落结束后,目前所有已经落稳的方块堆叠的最高高度。

-
解答
public List<Integer> fallingSquares(int[][] positions) { List<Integer> hList = new ArrayList<>();//存放当前方块的高度 List<Integer> list = new ArrayList<>();//存放当前最大高度 if(positions == null || positions.length == 0){ return list; } int maxH = positions[0][1]; int high = positions[0][1]; hList.add(high); list.add(maxH); P:for(int i = 1; i < positions.length; i++){ high = positions[i][1]; //判断当前方块能否放在之前的方块上方,并取得最高值 for(int j = i-1; j>=0; j--){ //遍历已经放的块 if(!(positions[j][0] >= positions[i][0] + positions[i][1] || positions[j][0] +positions[j][1]<= positions[i][0])){ //若可以放在上面 int temp = hList.get(j) + positions[i][1];//高度叠加 if(temp > high){ high = temp;//更新高度 } } } hList.add(high);//当前块的最终高度 if(high > maxH){ maxH = high; } list.add(maxH);//存放当前的最大高度 } return list; } -
分析
- 2个集合 一个hList用于存放每一块方块的最终真实高度,另一个list用于存放当前最大高度
- 一开始将第一块放入两个集合当中。
- 然后从第二块开始遍历
- 内层循环,遍历已经放置的方块。如果当前方块在已经放置的方块上面,那么就计算新的高度,取最大值。
- 内层循环结束可以得到方块的最终高度。
- 将当前块的最终高度 放入 hList集合当中,并更新当前所有块的最大高度。
-
提交结果
700. 二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。

-
解答
public TreeNode searchBST(TreeNode root, int val) { if(root == null)return null; if(root.val == val)return root; if(root.val > val){ return searchBST(root.left,val); }else return searchBST(root.right,val); } -
分析
- 略
-
提交结果