新一代的MPP数据库
极速SQL查询
-
全新的向量化执行引擎,亚秒级查询延时,单节点每秒可处理多达100亿行数据。
-
强大的MPP执行框架,支持星型模型和雪花模型,极致的Join性能。
-
综合查询速度比其他产品快10-100倍

实时数据分析
-
新型列式存储引擎,支持大规模数据实时写入,秒级实时性保证。
-
支持业务指标实时聚合,加速实时多维数据分析。
-
新型读写并发管理模式,可同时高效处理数据读取和写入。

高并发查询
-
灵活的资源分配策略,每秒可支持高达1万以上的并发查询。
-
可高效支持数千用户同时进行数据分析。
轻松管理大数据
-
支持在大数据规模下进行在线弹性扩展,扩容不影响线上业务。集群可扩展至数百节点,PB量级数据。
-
集群运行高度自治化,故障自恢复,运维成本低。
国产核心软件
-
完全自主创新,全球领先。
-
更完善的本地化专家服务体系。
1.1 DorisDB是什么
1.2 DorisDB特性
1.2.1 架构简单
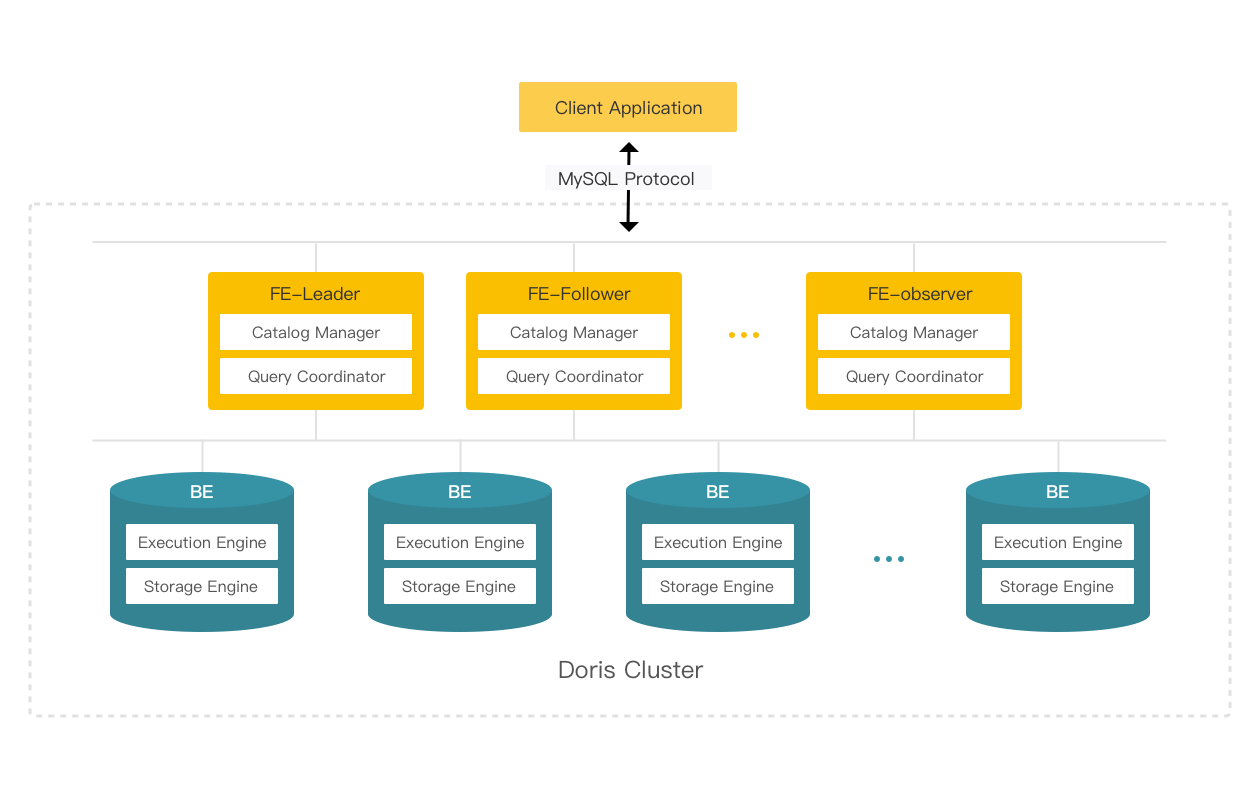
1.2.2 分布式架构
1.2.3 自治系统,管理简单
1.2.4 高效的列式存储引擎
1.2.5 标准SQL
1.2.6 MPP(Massively Parallel Processing)执行框架
1.2.7 流批导入
1.2.8 智能物化视图
1.2.9 高可用
1.2.10 数据分区
1.2.11 Index加速查询
1.2.12 近似去重、精确去重功能
1.3 DorisDB适合什么场景
1.1 DorisDB是什么
- DorisDB是一款经过业界检验、现代化,面向多种数据分析场景的、 兼容MySQL协议的, 高性能的, 分布式关系型列式数据库。
- DorisDB脱胎于百度广告业务的实时分析场景, 于2018贡献于Apache开源社区, 之后在美团, 小米, 字节跳动, 京东等互联网企业被适用于核心业务实时数据分析, 得到了工业界的检验。
- DorisDB充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果, 并在业界实践的基础上, 进一步改进, 优化, 架构升级和加入新功能, 形成企业级产品。
- DorisDB致力于满足企业用户的多种数据分析场景. 支持多种数据模型(明细表, 聚合表), 多种导入方式(批量, 可整合和接入多种现有系统(Spark, Flink, Hive, ElasticSearch)。
- DorisDB兼容MySQL协议, 可使用MySQL客户端和常用BI工具对接DorisDB来进行数据分析。
- DorisDB采用分布式架构, 对table进行水平划分并以多副本存储. 集群规模可以灵活伸缩, 能够支持10PB级别的数据分析; 支持MPP, 并行加速计算; 支持多副本, 具有弹性容错能力。
- DorisDB采用关系模型, 使用严格的数据类型, 使用列式存储引擎, 通过编码和压缩技术, 降低读写放大. 使用向量化执行方式, 充分挖掘多核CPU的并行计算能力, 从而显著提升查询性能。
1.2 DorisDB特性
DorisDB的架构设计融合了MPP数据库,以及分布式系统的设计思想,具有以下特性:
1.2.1 架构简单
DorisDB集群的正常运行不需要依赖任何其他系统, 易部署, 易维护. 极简的架构设计, 降低了DorisDB系统的复杂度和维护成本, 同时也提升了系统的可靠性和扩展性。管理员只需要专注于DorisDB系统,无需学习和管理任何其他外部系统。
1.2.2 分布式架构
DorisDB采用分布式架构,存储容量和计算能力可近似线性水平扩展。DorisDB集群的规模可扩展到数百节点,支持的数据规模可达到10PB级别。元数据和数据管理采用热备保证高可用, 能够自愈, 服务和数据安全可靠。
1.2.3 自治系统,管理简单
DorisDB是一个自治的系统。节点的上下线,集群扩缩容都可通过一条简单的SQL命令来完成; 在此操作期间, DorisDB后台自动完成数据rebalance; 用户的查询和数据导入操作可同时正常运行。
另外DorisDB表模式热变更,可通过一条简单SQL命令动态地修改表的定义, 例如增加列、减少列、新建物化视图等。同时,处于模式变更中的表也可也正常导入和查询数据。
1.2.4 高效的列式存储引擎
DorisDB中的数据按列存储, 在查询时, 只需访问所需的目标列, 而不必像采用行式存储的传统数据仓库那样读取整行, 因此会有极大的性能提升。另外,由于数据按列组织,DorisDB可以使用压缩效率更高的编码技术对数据进行压缩,提升数据读取效率。并且可以针对某列创建包含范围信息,bitmap索引和bloomfilter的过滤条件,快速过滤不满足查询条件的数据,从而提升整体查询性能。
1.2.5 标准SQL
DorisDB支持标准的SQL语法,包括聚合,JOIN,排序,窗口函数,自定义函数等功能,用户可以通过标准的SQL对数据进行灵活的分析运算。 此外,DorisDB还兼容MySQL协议语法,可使用现有的各种客户端工具、BI软件访问DorisDB, 对DorisDB中的数据进行拖拽式分析。
1.2.6 MPP(Massively Parallel Processing)执行框架
DorisDB内部通过MPP计算框架完成SQL的具体执行工作。MPP框架本身能够充分的利用多节点、多CPU, 多核的算力,充分地将整个查询并行执行, 从而实现很好的交互式分析体验. DorisDB能够支持亚秒级查询,并且查询QPS可达10000以上。
1.2.7 流批导入
DorisDB支持实时和批量两种数据导入方式, 支持的数据源有Kafka, HDFS, 本地文件. 支持的数据格式有ORC, Parquet和CSV等. DorisDB可以实时消费Kafka数据来完成数据导入,保证数据不丢不重(exactly once)。DorisDB也可以从本地或者远程(HDFS)批量导入数据。
1.2.8 智能物化视图
DorisDB支持智能的物化视图。用户可以通过创建物化视图,预先计算生成预聚合表用于加速聚合类查询请求。 DorisDB的物化视图能够在数据导入时自动完成汇聚,与原始表数据保持一致。并且在查询的时候,用户无需指定物化视图,DorisDB能够自动选择最优的物化视图来满足查询请求。
1.2.9 高可用
DorisDB的元数据和数据都是多副本存储,并且集群中服务有热备, 多实例部署,避免了单点故障。集群具有自愈能力, 可弹性恢复. 节点的宕机、下线、异常都不会影响DorisDB集群服务的整体稳定性。
1.2.10 数据分区
DorisDB支持两级分区和动态分区。首先, 第一级分区对数据做Range划分, 用户可以把分区作为管理目标, 动态增删分区. 其次, 为了解决分区内的数据倾斜问题, 对分区做第二级分桶, 对分区内的数据做Hash划分。 这种分区分桶的设计方法, 可以灵活管理用户数据, 比如可以设置分区的存储介质,副本数,分区的生存周期和分桶数量等等。 用户可以利用分区分桶的机制实现冷热数据分离等功能。
1.2.11 Index加速查询
DorisDB在存储引擎中支持使用Bitmap,Bloom Filter等索引方式。大部分场景中,DorisDB会在内部充分利用各种数据结构优化查询,用户无须主动创建索引加速。用户也可以根据具体的业务场景使用不同的索引技术来进行优化,例如在中高基数的字符串字段上创建Bitmap索引来提升equal/in 查询的效率等。
1.2.12 近似去重、精确去重功能
DorisDB内置HyperLogLog类型以及Bitmap类型。用户可以通过这两个类型完成数据快速的近似去重,或者精确去重。
1.3 DorisDB适合什么场景
DorisDB可以满足企业级用户的多种分析需求,包括OLAP多维分析,定制报表,实时数据分析,Ad-hoc数据分析等。具体的业务场景包括:
- 数据仓库建设
- OLAP/BI分析
- 用户行为分析
- 广告数据分析
- 系统监控分析
- 探针分析 APM(Application Performance Management)
部分资料内容来源于网络 , 如侵权请联系博主删除!