
不断修订中。。。
文章目录
前言
日常炼丹时,nvidia-smi 可以看到如下界面

watch nvidia-smi 可以看到动态的,页面中显存占用和 GPU 利用率有直接的联系吗?本博客就此展开讨论
扩展版 浅谈深度学习:如何计算模型以及中间变量的显存占用大小
结论:显存占用和 GPU 利用率的关系可以类似看成内存和 CPU 的关系
1 显存占用
显存可以看成是空间,类似于内存。
显存用于存放模型,数据
显存越大,所能运行的网络也就越大
1.1 参数的显存占用
参数占用显存 = 参数数目 ×n

eg: Float 32 时,n = 4
在 PyTorch 中,当你执行完 model=MyGreatModel().cuda() 之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
1.2 梯度与动量的显存占用

SGD + momentum(把上一次的梯度更新当成惯性) 的讲解可以参考 随机梯度下降与动量详解
1.3 输入输出的显存占用
计算出每一层输出的 Tensor 的形状,然后就能计算出相应的显存占用。
模型输出的显存占用,总结如下:
- 需要计算每一层的 feature map 的形状(多维数组的形状),模型输出的显存占用与 batch size 成正比
- 需要保存输出对应的梯度用以反向传播(链式法则的中间结果),模型输出不需要存储相应的动量信息(因为不需要执行优化)
举个例子,下面是一个计算图,输入 x,经过中间结果 z,然后得到最终变量 L
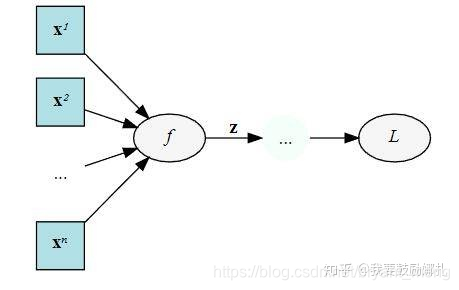
我们在 backward 的时候要求 L 对 x 的梯度,这个时候就需要在计算链 L 和 x 中间的 z:
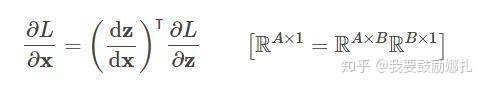
dz / dx 这个中间值当然要保留下来以用于计算
另外需要注意
- 输入(数据,图片)一般不需要计算梯度
- 神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如 ReLU,在 PyTorch 中,使用 nn.ReLU(inplace = True) 能将激活函数 ReLU 的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy(); dx[y<=0]=0)
1.4 总结
总结一下,我们在总体的训练中,占用显存大概分以下几类:
- 模型中的参数(卷积层或其他有参数的层,参数指的是 trainable 的参数)
- 模型在计算时产生的中间参数(也就是输入图像在计算时每一层产生的输入和输出)
- backward 的时候产生的额外的中间参数(链式传播)
- 优化器在优化时产生的额外的模型参数
但其实,我们占用的显存空间为什么比我们理论计算的还要大,原因大概是因为深度学习框架一些额外的开销吧,不过如果通过上面公式,理论计算出来的显存和实际不会差太多的。
1.5 优化
优化除了算法层的优化,最基本的优化无非也就一下几点:
- 减少输入图像的尺寸
- 减少 batch,减少每次的输入图像数量
- 多使用下采样,池化层
- 一些神经网络层可以进行小优化,利用 relu 层中设置 inplace
- 购买显存更大的显卡
- 从深度学习框架上面进行优化
- 对于不需要 bp 的 forward,如 validation 请使用 torch.no_grad , 注意model.eval() 不等于 torch.no_grad() 请看如下讨论(Pytorch有什么节省显存的小技巧? - 郑哲东的回答 - 知乎)。
来自 ‘model.eval()’ vs ‘with torch.no_grad()’


测试时
with torch.no_grad():
测试代码
...
...
2 GPU 利用率
GPU 计算单元类似于 CPU 中的核,用来进行数值计算。
衡量计算量的单位是 flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个 flop。计算能力越强大,速度越快。衡量计算能力的单位是 flops: 每秒能执行的 flop 数量

3 显存释放
参考 深度学习训练已经停止了,可GPU内存还在占用着,怎么办?
watch nvidia-smi 能看到 PID 号那就比较好说了,直接 kill -9 PID 就行
watch nvidia-smi看不到,重启,哈哈哈,当然可以
不过下面这条指令可以查看到
fuser -v /dev/nvidia*
然后 kill 掉对应的 PID,可能不止一个
A 附录 Use GPU to speed up training
测试下矩阵运算GPU与CPU的差别
A.1 导入tensorflow模块
import tensorflow as tf
import time
A.2 建立和执行计算图
默认用GPU跑
tf.reduce_sum 计算矩阵的和
#建立计算图
size=500
W = tf.random_normal([size, size],name='W') # 500,500
X = tf.random_normal([size, size],name='X') # 500,500
mul = tf.matmul(W, X,name='mul')
sum_result = tf.reduce_sum(mul,name='sum')# 矩阵内的值加总
# 执行计算图
with tf.Session() as sess:
result = sess.run(sum_result)
print('result=',result)
output
result= -10656.27
A.3 测试GPU与CPU性能的差别
def performanceTest(device_name,size):
with tf.device(device_name):
W = tf.random_normal([size, size],name='W')
X = tf.random_normal([size, size],name='X')
mul = tf.matmul(W, X,name='mul')
sum_result = tf.reduce_sum(mul,name='sum')
startTime = time.time()
# 使用 tf.ConfigProto 建立 session 的配置设置 tfconfig,传入参数 log_device_placement设置为True
tfconfig=tf.ConfigProto(log_device_placement=True)
with tf.Session(config=tfconfig) as sess:
result = sess.run(sum_result)
takeTimes=time.time() - startTime
print(device_name," size=",size,"Time:",takeTimes )
return takeTimes
调用
gpu_set=[];cpu_set=[];i_set=[]
for i in range(0,5001,500):
g=performanceTest("/gpu:0",i) # 0号GPU
c=performanceTest("/cpu:0",i)
gpu_set.append(g);cpu_set.append(c);i_set.append(i)
print("--")
output
/gpu:0 size= 0 Time: 0.14670062065124512
/cpu:0 size= 0 Time: 0.16228890419006348
--
/gpu:0 size= 500 Time: 0.16929364204406738
/cpu:0 size= 500 Time: 0.18462872505187988
--
/gpu:0 size= 1000 Time: 0.13805508613586426
/cpu:0 size= 1000 Time: 0.13151001930236816
--
/gpu:0 size= 1500 Time: 0.1536424160003662
/cpu:0 size= 1500 Time: 0.2314302921295166
--
/gpu:0 size= 2000 Time: 0.21573805809020996
/cpu:0 size= 2000 Time: 0.4350099563598633
--
/gpu:0 size= 2500 Time: 0.37288379669189453
/cpu:0 size= 2500 Time: 0.6350183486938477
--
/gpu:0 size= 3000 Time: 0.5283641815185547
/cpu:0 size= 3000 Time: 0.9774112701416016
--
/gpu:0 size= 3500 Time: 0.7861192226409912
/cpu:0 size= 3500 Time: 1.4520719051361084
--
/gpu:0 size= 4000 Time: 1.1301662921905518
/cpu:0 size= 4000 Time: 2.030012845993042
--
/gpu:0 size= 4500 Time: 1.5385856628417969
/cpu:0 size= 4500 Time: 2.7173430919647217
--
/gpu:0 size= 5000 Time: 2.0486159324645996
/cpu:0 size= 5000 Time: 3.6564781665802
--
GPU的RAM不够就把size设置小一些,可视化一下结果
%matplotlib inline
import matplotlib.pyplot as plt
fig = plt.gcf()
fig.set_size_inches(6,4)
plt.plot(i_set, gpu_set, label = 'gpu')
plt.plot(i_set, cpu_set, label = 'cpu')
plt.legend()
output
