来源: ACL 2017
关键词:NLG,Pointer-Generator Networks
1.背景及问题描述
seq2seq模型的出现给生成式摘要(abstractive text summarization)的实现提供了更好的方案,但是seq2seq常常出现的两点弊端:1. 它容易生成不准确的细节 2. 容易重复 3.不能处理OOV问题。作者提出了两个方法来提升seq2seq模型的表现,一个是将PointerNetwork与seq2seq中的encoder结合起来,使得生成的结果中既有seq2seq从全部词典中生成的,也有从源文本中copy的,这样即可以帮助生成准确的词语,同时也可以处理OOV的问题。第二点是使用coverage机制来追踪摘要的部分,一次来避免重复(repetition)。
2.已有的解决方案
seq2seq+attention是处理此类问题的baseline:
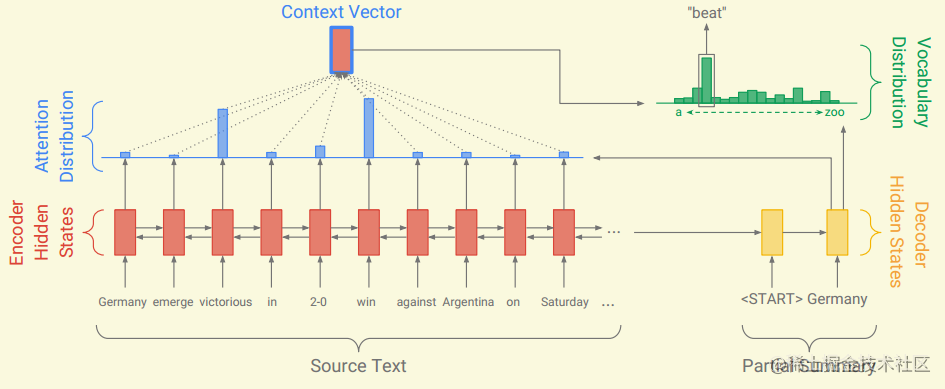
seq2seq模型分为encoder和decoder。在encoder端,需要将文章
wi中的单词一个一个的fed到encoder中(LSTM或者Transformer),经过encoder得到文章
i的编码状态
hi (encoder hidden states),在decoder端,在每一个时刻
t,decoder接收前一个时刻单词的词向量,求得解码状态
st(decoder hidden state ),然后计算得到注意力权重
at:
eit=vTtanh(Whhi+Wsst+batn)at=softmax(et)
公式中
v,
Wh,
Ws以及
battn都是可学习的参数。 这里得到的注意力权重
at可以看作是关于source中所有词语的关注度概率,用来告诉decoder应该关注那一个word来生成下一个词语。
然后使用注意力权重
at和编码状态
hi计算得到加权的编码状态,看作是上下文向量
ht∗:
ht∗=i∑aithi
将上面得到的上下文向量
ht∗送入到两层线性层,计算softmax得到单词表概率分布
Pvocab,概率值表示词典中所有vocab被选中的概率。
P(w)=Pvocab=softmax(V′(V[st,ht∗]+b)+b′)
最后使用交叉熵计算loss,完整的loss就是序列每个位置loss的平均值:
losst=−logP(wt∗)loss=T1t=0∑Tlosst
3.解决方案概述
本篇论文是在seq2seq基础上提出了Pointer-Generator Networks,也就是seq2seq+PointerNetwork:
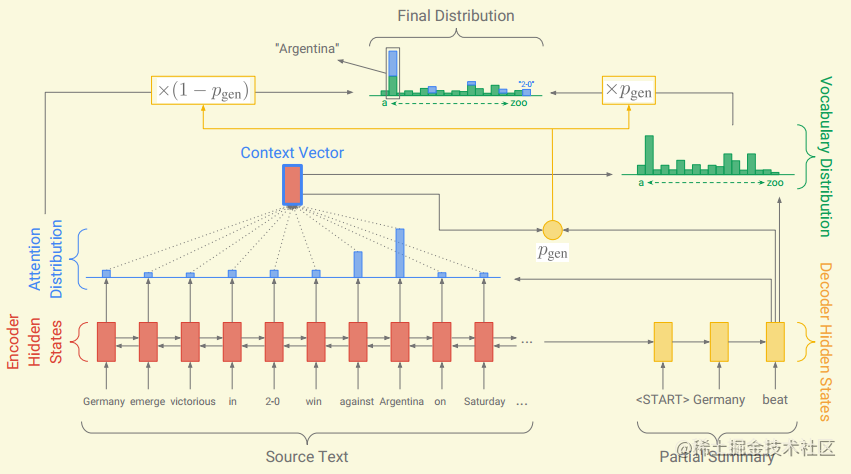
- Pointer-Generator Networks
在解码阶段,如何确定是从source中copy还是生成,作者引入一个权重
pgen∈[0,1]来决定。具体的计算,在
t时刻:
pgen=sigmoid(Wh∗Tht∗+wsTst+wxTxt+bptr) 其中,
Wh∗,
ws,
sx以及
bptr是可学习参数,解码状态
st,上下文向量
ht∗,decoder的输入
xt 。 在解码阶段需要维护一个扩展的词典,即原本词典加上source中出现的所有词语,我们在这个扩展的词典上计算所有token的概率:
P(w)=pgenPvocab(w)+(1−pgen)∑i:wi=wait
在这里,如果
w是OOV,则
Pvocab为0,相同的,如果
w没有出现在source中,则后面一项也为0.
loss的定义与seq2seq中相同。
2.Coverage mechanism
重复是seq2seq模型经常出现的问题,本文引入 Coverage model来解决这个问题,这也是本文的主要亮点。具体实现上,就是将之前所有step的注意力权重相加到一个覆盖向量(coverage vector)
ct 上。就是用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。具体计算如下:
ct=∑t′=0t−1at′ 然后将覆盖向量添加到注意力权重的计算过程中:
eit=vTtanh(Whhi+Wsst+wccit+batn) 这就可以使得在计算注意力权重时,当前的决定是受到历史决定影响的,这样就可以让注意力机制避免重复关注某个位置,也就可以避免生成重复词语。
作者发现引入 coverage loss 是很有必要的,coverage loss的计算方式如下:
covlosst=∑imin(aitcit)
值得注意的是这个loss只会对重复的attention产生惩罚(min),并不会强制要求模型关注原文中的每一个词.
模型最终的loss为,其中
λ是超参数:
losst=−logP(wt∗)+λ∑imin(aitcit)
coverage loss的量化解释
为什么加入coverage loss就能起到惩罚重复关注的位置呢?比如,对于一个4个单词的序列,在
t步计算得到的coverage向量为:
cit=(0.03,2.88,0.03,0.03),显然第二个token被关注的太多了,应该对它适当的惩罚。 如果decoder在
t时刻attention继续关注的还是第二个token,比如:
ait=(0.01,0.96,0.01,0.01)covlosst=∑imin(aitcit)=∑ait=1 这正情况得到的loss就比较大。 如果decoder在
t时刻不是关注的第二个token呢?比如:
ait=(0.96,0.01,0.01,0.01)covlosst=∑imin(aitcit)=∑(0.03,0.01,0.01,0.01)=0.06 这种情况计算得到的loss就比较小了。
4.结果分析
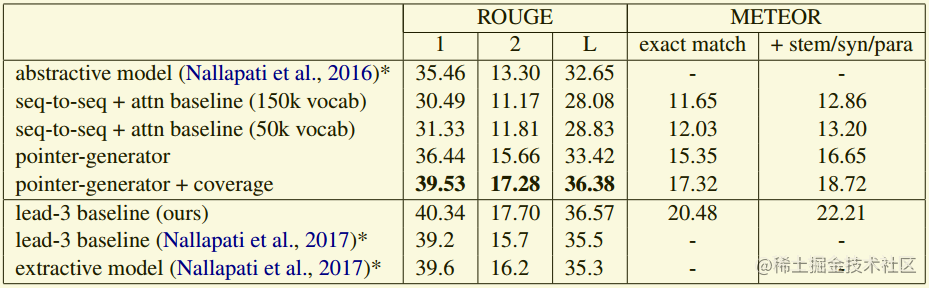
在abstractive摘要的评测中,本文提出的方法在ROUGE这个指标上提升比较明显。 此外,作者发现,lead-3的实验设置,也就是只取文章的前3句话进行抽取生成,ROUGE得分明显更高,这是因为新闻的关键信息一般出现在文章开头。实际上,作者实验发现,只使用前400个token效果更好。
此外作者还分析了,本文模型与seq2seq+attentoin模型生成很少见n-gram的比例: 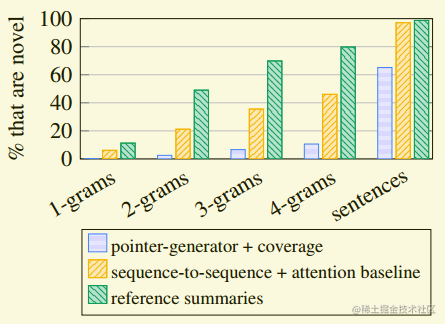 少见n-gram的定义是没有出现在原本的n-gram。从上图可以发现,本文模型生成比较少的少见n-gram,seq2seq+attentoin模型生成的比较多,并且大多数都是错误的。
少见n-gram的定义是没有出现在原本的n-gram。从上图可以发现,本文模型生成比较少的少见n-gram,seq2seq+attentoin模型生成的比较多,并且大多数都是错误的。
5.创新点或贡献
- 文本提出了一种引入覆盖机制的混合指针模型,可以有效缓解生成模型不准确和重复的问题。
- 在长文抽取任务中,本模型结果大大超出当时的SOTA。
- 本文是在seq2seq模型基础上加入的PointerNetwork和Coverage model,效果提升很多,但是模型参数没有增加很多。详细的,baseline模型参数共有21,499,600参数,pointer-generator增加1153参数,coverage增加512参数
6.个人思考
经典的文章,经典的思路,值得深入学习!
[参考] paper code-pytorch