概述。
什么是网络刮削,它是如何与Python一起工作的?有趣的是,网络刮削这个词是指使用计算机或算法从互联网上提取和处理大量数据的做法。从网络上刮取数据是一项有用的技能,无论你是数据科学家、工程师,还是任何分析大量数据的人。让我们开始吧!!
内容表。
简介
使用python实现网络刮削
为什么要用python来进行网络刮削?
从网站上抓取数据的分步骤过程
如何进行网络抓取?
-
-
- 刮痧
- 美丽的汤
- selenium
-
刮取电子商务网站
使用beautiful soup和selenium进行网络抓取
使用scrapy进行网络刮擦/抓取
创建一个Scrapy Spider类
刮取许多页面
关于我自己
总结
网络抓取简介
考虑以下情况:你需要以最快的速度从网站上提取大量的数据。如果你不去每个网站手动收集数据,你会怎么做?嗯,答案是 "网络刮削"。刮网使这一过程变得更加容易和快速。

图片1
网络刮削是一种从网站中提取大量数据的技术。但为什么要从网站上获得如此大量的数据呢?看看下面的网络刮削应用,了解更多。
-
- 价格比较和竞争监测--网络刮削工具可以随时监测这家公司的餐饮产品数据。
-
- 机器学习项目的训练和测试数据--网络刮削有助于为机器学习模型的测试和训练收集数据。
-
- 学术研究。
-
- 从TripAdvisor等网站收集酒店/餐馆的评论和评级。
-
- 使用Booking.com和Hotels.com等网站来搜刮酒店房间的价格和信息。
-
- 从Twitter上搜刮与特定账户或标签相关的推文。
-
我们可以从黄页网站或谷歌地图的业务列表中搜刮业务联系信息,如电话号码和电子邮件地址,以产生营销线索。
使用Python实现网络刮削
网络刮削是一种从网站自动提取大量数据的方式。有时,网页上的信息是没有结构的。在这种情况下,网络刮削有助于收集非结构化的数据并随后以结构化的格式存储。我们可以用各种方法做刮削网站,包括使用互联网服务、API,或在本文中建立你的程序。我们将看看如何使用Python来实现网络搜刮。
为什么Python被用于网络刮削?
-
Python包括许多库,如Numpy、Matplotlib、Pandas等,它们为各种用途提供方法和函数。因此,它适合于网络抓取和其他数据处理。
-
Python是一种容易编程的语言。任何地方都不需要分号";"或大括号"{}"。所以它更容易使用,而且噪音更小。
-
动态类型化。你不必为Python中的变量定义数据类型;你可以在需要的地方直接使用它们。这为你节省了时间,加快了你的工作。
-
代码小,过程长。网络刮削是一种节省时间的技术。但如果你浪费更多的时间来写代码,那又有什么用呢?不过,你不必这样做。我们可以用Python写小代码来完成大任务。结果是,即使在写代码的时候,你也能节省时间。
-
Python的语法简单易学,因为与阅读英文语句相比,阅读Python代码是相当容易理解的。Python的缩进帮助用户区分代码中不同的范围/区块,使其富有表现力并易于理解。
从网站上刮取数据的逐步过程**。**
网络刮削是使用HTML解析从网页上获取数据。有些数据在一些网站上以CSV或JSON格式提供,但这并不总是如此,这就造成了网络刮削的使用。
当你运行网络刮削代码时,它会向你指定的URL发送一个请求。服务器在响应你的请求时提供数据,让你看到HTML或XML页面。然后代码解析HTML或XML页面,定位并提取数据。
如何使用Python进行网络抓取?
我们可以使用三种不同的框架用Python进行网络抓取。
Scrapy
Scrapy是一个高水平的网络爬行和搜刮框架,用于爬行网站并从其页面中提取结构化数据。从数据挖掘到监控和自动测试,我们可以用它来完成各种任务。Scraping hub和其他一众贡献者建立并维护着它。
Scrapy是其中的佼佼者,因为它要求我们把主要精力放在解析网页的HTML结构上,而不是发送查询和从响应中提取HTML内容;在Scrapy中,我们只需要指定网站的URL。
刮削中心也可以托管Scrapy项目,我们可以安排刮削器的运行时间。
美丽的汤
Beautiful Soup是一个用于解析HTML和XML文件并提取数据的Python包。它与你喜欢的解析器集成,提供流畅的导航、搜索和对解析树的修改。对于程序员来说,节省几个小时甚至几天的努力是正常的。
要用Beautiful Soup刮取一个网站,我们还必须使用request库向网站发送请求并接收响应,以及从这些响应中提取HTML内容并将其交付给Beautiful Soup对象进行解析。
Selenium
Selenium Python结点为编写Selenium WebDriver功能/验收测试提供了一个简单的API。你可以使用Selenium Python API来简单访问Selenium WebDriver的所有功能。
Selenium框架用于刮取动态加载内容的网站,如Facebook和Twitter,或者如果我们需要使用点击或滚动页面动作登录或注册,以进入要刮取的页面。
在网站加载了动态创建的材料后,我们可以使用Selenium来获得该网站的HTML,并将其送入Scrapy或Beautiful Soup来执行同样的活动。
潘达
Pandas是一个数据处理和分析库。它被用来提取数据并以你想要的格式保存。
刮取电子商务网站
前提是。
- Python 2. x或Python 3. x,安装Beautiful Soup、pandas、Selenium库。
- Ubuntu操作系统。
- Google-chrome浏览器。
现在让我们从网站上提取数据。
使用beautiful soup和selenium进行网络刮削。
第1步:找到你想搜刮的URL。
在这个例子中,我们将刮取亚马逊网站以获得手机的价格、名称和评价。这个页面的地址是。
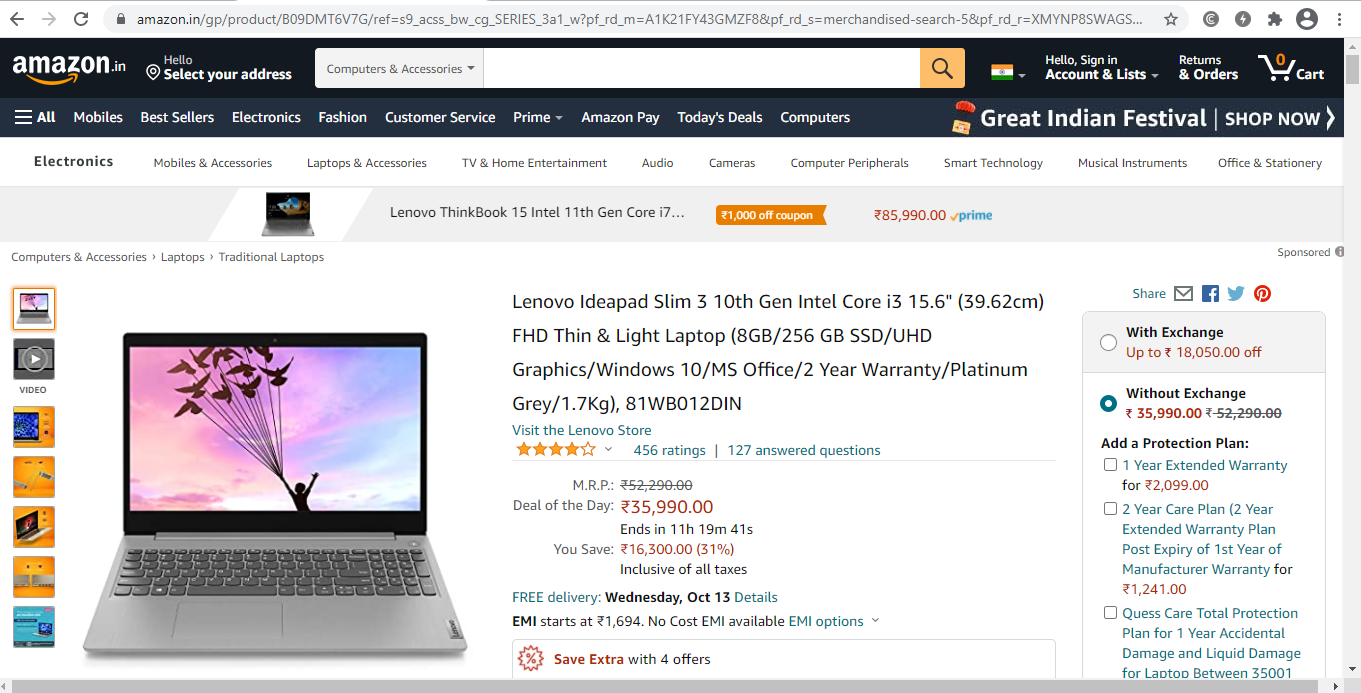
第二步:检查页面并查看页面源。
他们通常将数据嵌套在标签上。所以我们检查网站,发现我们要搜刮的数据嵌套在哪个标签下面。只需在一个元素上点击右键,从下拉菜单中选择 "检查"。
右键单击页面上的任何地方,并选择 "检查"/"查看页面源 "来检查它。要查看网页上的某个特定元素,如文本或图像,右键单击它并选择 "检查"/"查看页面源"。
当我们在 "检查 "标签上导航时,"浏览器检查框 "将在同一标签上打开。
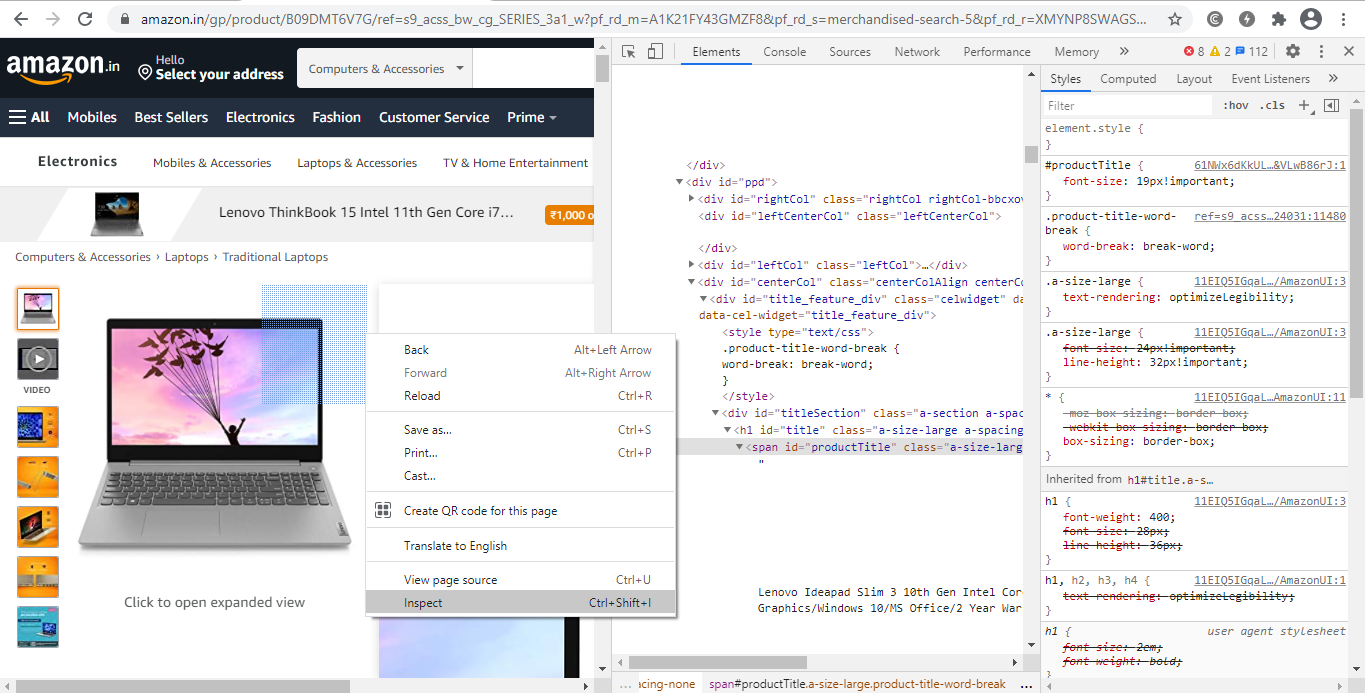
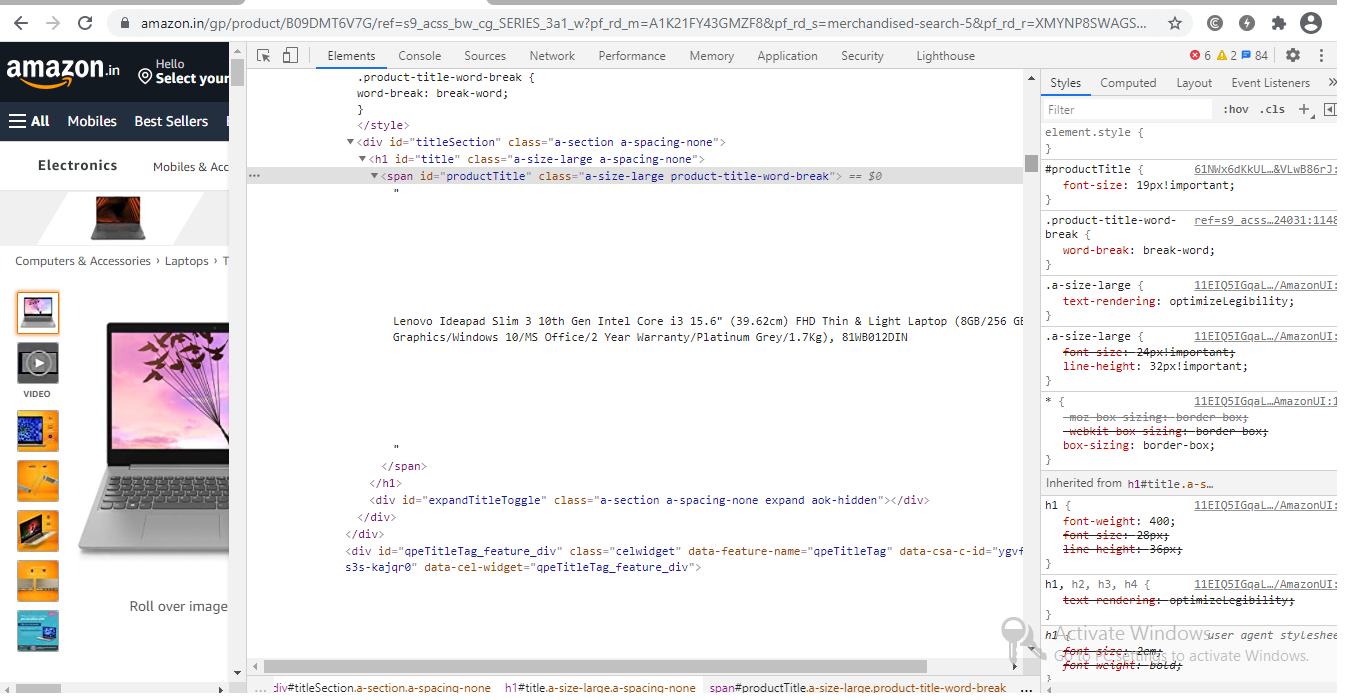
第3步:找到你希望检索的信息。
让我们从 "div "标签中提取价格、名称和评级,这些都在 "div "标签中。
第4步:构建代码。
让我们从制作一个Python文件开始。要做到这一点,打开Ubuntu的终端,输入gedit你的文件名>,扩展名为.py。
gedit web-scrap.py
首先,让我们导入所有的库。
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
确保你的机器上安装了Python**(版本3以上**)和BeautifulSoup,然后再进行搜刮。如果你没有BeautifulSoup,在你的终端/命令提示符中输入以下命令。
pip 安装 beautifulsoup4
因为我们的目标是提取文章的全部内容,所以关键是要注意到
元素,它包含了文章的全部文本。让我们更深入地看一下这个页面,看看我们是否能找到
标签。
我们必须设置chrome驱动的路径,以配置网络驱动使用Chrome浏览器。
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
接下来,我们必须编写代码来打开URL,并将提取的细节存储在一个列表中。
products=[] #store name of the product prices=[] #store price of the product ratings=[] #store rating of the product driver.get("www.amazon.in/gp/product/…")
现在是时候从网站上提取数据了,因为我们已经编写了打开URL的代码。我们希望提取的数据是嵌套在
标签中,如前所述。因此,我将寻找带有这些类名的div标签,提取数据,并将其保存在一个变量中。请看下面的代码。
content = driver.page_source soup = BeautifulSoup(content) for a in soup.findAll('a',hreforeTrue, attrs={'class':'_31qSD5'}): name=a.find('div', attrs={'class':'_3wU53n'}) price=a。find('div', attrs={'class':'_1vC4OE _2rQ-NK'}) rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'}) products.append(name.text) prices.append(price.text) ratings.append( rating.text
第5步:运行代码并提取数据。
通过使用下面的命令来运行该代码。
python web-scrap.py
第6步:以适当的格式保存信息。
在你提取了数据后,将其保存为一种格式。根据你的需要,这个格式可能有所不同。在这个例子中,我们将把提取的数据保存为CSV(逗号分隔值)格式。为了达到这个目的,我将在我的代码中加入以下几行。
df = pd.DataFrame({'Product Name':products, 'Price':prices, 'Rating':Rights}) df.to_csv('products.csv', index=False, encoding='utf-8')
现在再次运行整个程序。
一个名为 "products.csv "的文件被创建,其中包含提取的数据。
输出将是。

Selenium经常被用来从包含大量Javascript的网站中提取数据。大规模地运行大量的Selenium/Headless Chrome实例是很困难的。
使用scrapy进行网络刮擦/抓取
我们可以通过pip命令安装scrapy。然而,Scrapy的文献强烈建议将其安装在专门的虚拟环境中,以尽量减少与系统程序的问题。
Virtualenv和Virtualenvwrapper是我正在使用的。
mkvirtualenv scrapy_env pip install Scrapy
通过这个命令,你现在可以创建一个新的Scrapy项目。
scrapy startproject web_scrap
所有项目的模板文件都会因为这个而被创建。
├── web_scrap
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── 中间件.py
│ ├── pipelines.py
│ ├──设置.py
│ └──蜘蛛
│ ├── __init__.py
│ └── __pycache__ 。
└── scrap.cfg
我试图解释下面所有的文件夹和文件。
items.py是一个已经提取的数据的模型。你可以创建你的模型(例如,一个产品),继承scrapy item类。
pipelines.py:我们使用scrapy中的管道来处理提取的数据,清理HTML,验证数据,并将其保存到数据库或导出为自定义格式。
**middlewares.py。**使用中间件改变了请求/响应的生命周期。例如,你可以构建一个中间件来轮换用户代理或使用API,而不是自己执行请求。
scrapy.cfg是一个配置文件,允许你调整一些设置。
我们可以在/spiders文件夹中找到spider类。蜘蛛是scrapy的类,它定义了如何搜刮一个网站,包括跟踪哪些链接以及如何从这些链接中收集数据。
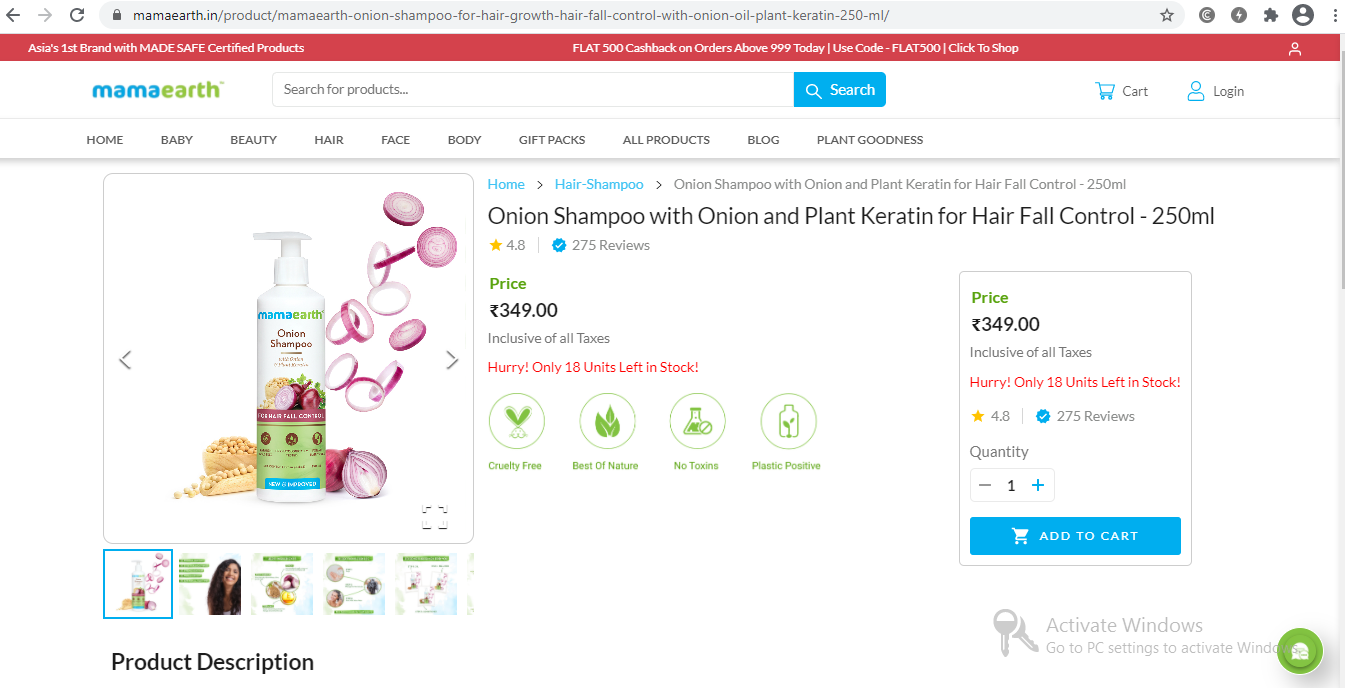
产品名称、图片、价格和描述将被提取出来。
图片2
Shell Scrapy
Scrapy包括一个内置的shell,可以实时调试搜刮代码。它可以快速测试你的XPath表达式和CSS选择器。它是编写网络搜刮程序的一个神奇的工具,我一直在使用它!
我们可以将scrapy Shell配置为使用与通常的Python控制台不同的控制台,如IPython。你会收到自动补全和其他有用的功能,如彩色输出。
你必须在你的scrapy.cfg文件中添加以下一行,以便在你的scrapy Shell中使用它。
shell = ipython
一旦我们配置了ipython,我们就可以开始使用scrapy shell了。
$ scrapy shell --nolog
只需使用下面的命令就可以开始获取URL了。
fetch('mamaearth.in/product/mam…')
/robot.txt文件将首先被取走。
[scrapy.core.engine] DEBUG:抓取了(404) <GET mamaearth.in/product/rob… (referer: None)
因为在这种情况下没有robot.txt,所以我们得到一个404的HTTP代码。如果有robot.txt文件,Scrapy将默认遵循这一规则。
这种行为可以通过改变settings.py中的以下设置来禁用。
ROBOTSTXT_OBEY = True
数据提取。
Scrapy默认不运行Javascript,所以如果你要搜刮的网站有Angular或React.js这样的前端框架,你可能很难获得你需要的数据。
让我们使用一个XPath表达式来获取产品的标题和价格。
我们将使用一个XPath表达式来提取价格,我们将选择div后的第一个span,其类别为Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj。
response.xpath("//div[@class='Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj']/span/text()" ).get()

创建一个Scrapy蜘蛛类
蜘蛛是scrapy类,决定你的抓取(哪些链接/URL应该被抓取)和抓取行为。
下面是一个蜘蛛类用来抓取网站的几个过程。
start_urls和start requests()被用来作为调用这些URL的方法。如果你需要改变HTTP动词或在请求中添加任何参数,你可以重写这个方法。
对于每个URL,它将创建一个Request对象并将响应发送到回调函数parse()。然后,数据(在我们的例子中,产品价格、图片、描述和标题)将被**parse()**方法提取,它将返回一个字典、一个Item对象、一个Request或一个iterable。
你可以用Scrapy将搜刮到的数据作为基本的Python字典返回,但最好使用Scrapy的Item类。
项目类。它只是一个简单的容器,用来存放我们刮来的数据,Scrapy会将这个项目的字段用于各种用途,比如将数据导出为多种格式(JSON / CSV...),项目管道等等。
让我们为产品类编写python代码。
import scrapy class Product(scrapy.Item): price = scrapy.Field() product_url = scrapy.Field() title = scrapy.Field() img_url = scrapy.Field()
现在我们可以使用命令行帮助器创建一个蜘蛛。
scrapy genspider myspider mydomain.com
在Scrapy中,有几种Spider可以解决最常见的网络刮削问题。
我们将使用一个spider类。它接收一个起始URL的列表,并使用一个解析函数来搜刮每一个URL。
CrawlSpider跟踪由规则决定的链接。
网站地图中定义的URL是由网站地图蜘蛛提取的。
在EcomSpider类中有两个需要的属性。
名称,这是我们的蜘蛛的名称(你可以用scrapy runspider spider_name运行它
开始的URL是start_urls。
当使用一个可以追踪其他域上的链接的CrawlSpider时,允许的域参数是至关重要的。
import scrapy from product_scraper.items import Product class EcomSpider(scrapy.Spider): name = 'ecom_spider' allowed_domains = ['mamaearth.in'] start_urls = ['mamaearth.in/product/mam… def parse(self, response): item = Product() item['product_url'] = response.xpath("//div[@class='Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-13vrskg-1 jjWoWj')item['price'] = response.xpath("//div[@class='Flex-sc-1lsr9yp-0 fiXUrs PriceRevamp-sc-13vrskg-1 jjWoWj']/span/text()" ).get() item['title'] = response.xpath('//section[1]//h1/text()').get() item['img_url'] = response.xpath("//div[@class='product-slider']//img/@src").get(0) return item
要将输出结果导出为JSON,请按以下方式运行代码(你也可以导出为CSV文件
scrapy runspider ecom_spider.py -o product.json
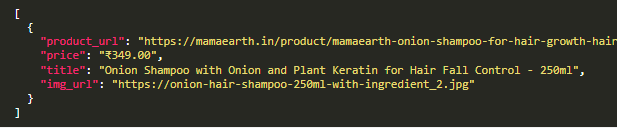
提取的JSON文件将看起来像下面这样。
刮取许多页面
现在是时候学习如何搜刮许多页面了,比如完整的产品目录,现在我们知道如何搜刮单个页面。正如我们之前看到的,蜘蛛有各种形状和大小。
如果你想搜刮一个完整的产品目录,网站地图应该是你首先要看的东西。我为此创建了特定的网站地图,向网络爬虫展示网站的组织方式。
一个网站地图.xml文件通常可以在baseURL/sitemap.xml找到。Scrapy会协助你解析网站地图,这可能是一个挑战。
mamaearth.in/product/ 2019-10-17t11:22:16+06:00 mamaearth.in/product/mam… 2019-10-17t11:22:16+06:00
幸运的是,我们可以限制URLs,只读取那些符合模式的URLs;这很简单;在这里,我们只希望URLs中含有/products/。
class SitemapSpider(SitemapSpider): name = "sitemap_spider" sitemap_urls = ['mamaearth.in/product/sit… sitemap_rules = [ ('/products/', 'parse_product') ] def parse_product(self, response) 。# ... 废除产品 ...
要搜刮所有的产品并将结果导出到CSV文件,请运行这个蜘蛛程序。
scrapy runspider sitemap_spider.py -o output.csv
如果网站上没有网站地图怎么办?Scrapy有一个解决方案!
从一个起始URLs列表开始,Crawl蜘蛛将抓取目标网站。然后,根据一组规则,它将提取每个URL的所有链接。在我们的例子中,这很简单,因为所有商品都有相同的/产品/产品名称的URL模式,因此我们要做的就是过滤这些URL。
import scrapy from scrapy.spiders import CrawlSpider, Rule from scrapy.linkextractors import LinkExtractor from product_scraper.productloader import ProductLoader from product_scraper.items import Product class MySpider(CrawlSpider): name = 'crawl_spider' allowed_domains = ['mamaearth.in'] start_urls = ['mamaearth.in/product/'\] rules = ( Rule(LinkExtractor(allow=('products', ) ), callback='parse_product'), ) def parse_product(self, response):# ...解析产品
正如你所看到的,这些内置的蜘蛛,操作起来很简单。如果从头开始建立它,那就困难得多了。
Scrapy为你处理了爬行逻辑,比如将新的URL添加到队列中,跟踪已经解析的URL,多线程等等。
关于我自己
你好,我叫Lavanya,来自Chennai。我是一个充满激情的作家和热情的内容制作者。最难解决的问题总是让我感到兴奋。我目前正在攻读化学工程学士学位,对数据工程、机器学习、数据科学和人工智能等领域有着浓厚的兴趣,我一直在寻找将这些领域与科学和化学等其他学科相结合的方法,以推进我的研究目标。
Linkedin URL: www.linkedin.com/in/lavanya-…
结语
我希望你觉得这篇博文很有趣你现在应该熟悉了Python中的Selenium API和beautiful soup,以及用scrapy进行网络抓取和刮取。在这篇文章中,我们研究了如何用Scrapy来抓取网络,以及它如何帮助你解决一些最典型的网络抓取问题。
结束语
-
如果你必须执行重复性的操作,如在一个没有API的网站上填写表格或审查登录表格后面的信息,Selenium可能是一个愉快的选择。
-
如果你一直用BeautifulSoup/Requests等工具进行网络搜刮,很容易看出Scrapy如何帮助你节省时间和构建更好的可维护搜刮器。
-
如果你想补充关于用Python刮取网页的任何意见,请在评论区添加。要了解更多关于网络刮削的信息,请阅读即将发表的文章。谢谢你。
图片来源。
本文所展示的媒体不属于Analytics Vidhya所有,由作者自行决定使用。