YOLO系列原理与改进
- 仅做部分归纳总结,详细内容见参考文章
1. YOLO v0 雏形思想
传统检测所采用的方法基本是滑动窗口法,想要检测的精度越高,那么就需要遍历的越精确,同时检测所需要的时间开销就会越大。除此之外还存在另一个问题,背景图片很多,前景图片很少:二分类样本不均衡。在一张图片中对应背景和前景的框差距极大。可以把传统检测法的问题总结成两点:
- 高精度消耗大量时间
- 操作复杂,需要手动生成大量的样本
YOLO的作者首先将传统方法中的one-hot vector换成(x, y, w, h, c),x, y 表示窗口左上角顶点坐标,w, h 表示窗口的宽和高,c则表示置信度,将问题转化成了回归问题,直接回归出窗口的位置。对于样本数据只需要把label设置为( 1 , x ∗ , y ∗ , w ∗ , h ∗ 1, x^*,y^*,w^*,h^* 1,x∗,y∗,w∗,h∗) 。这里 * 代表真值。
2. YOLO v1
在雏形思想中只能输出一个目标,因此对于多目标的问题需要做出改进,但是我们并不知道一张图片中有多少个目标,为了保证所有的目标都被检测到,需要输出尽量多的目标。在YOLO v1中所采用的办法是用一个(c,x,y,w,h)去负责image某个区域的目标。如下图所示:
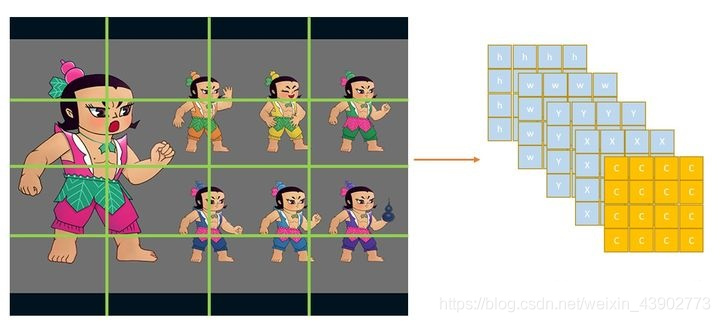
又由于一个目标可能横跨多个区域,只让目标中心所在区域c=1其余的c=0,如下图所示:

这其中存在一个问题,图片中总共有7个目标,但是只有6个真值,是因为第三行第三列的区域中存在两个目标。对于YOLO v1来说,这个问题无法解决,在一个区域中只能检测出一个目标。只能创建更多区域,例如将4 x 4变成40 x 40,使区域更加密集,但无法从根本上解决问题。
当我们检测得到16个框之后,采用NMS,将多余的框抑制掉,从而得到我们最终的结果。
完成多目标检测之后需要解决多分类问题,在YOLO v1中将(c,x,y,w,h)修改为(c,x,y,w,h,one-hot)从而解决了多分类问题
由于需要检测的不同类目标大小可能有较大差距,所以对于每一个区域采用了两个框,一个负责大目标,一个负责小目标。
论文中最终的输出是7 x 7 x 30,即7 x 7的区域,
30 = 5 ∗ 2 ( c b i g , x b i g , y b i g , w b i g , h b i g , c s m a l l , x s m a l l , y s m a l l , w s m a l l , h s m a l l ) + 20 c l a s s e s 30 = 5 * 2(c_{big},x_{big},y_{big},w_{big},h_{big},c_{small},x_{small},y_{small},w_{small},h_{small})+20classes 30=5∗2(cbig,xbig,ybig,wbig,hbig,csmall,xsmall,ysmall,wsmall,hsmall)+20classes
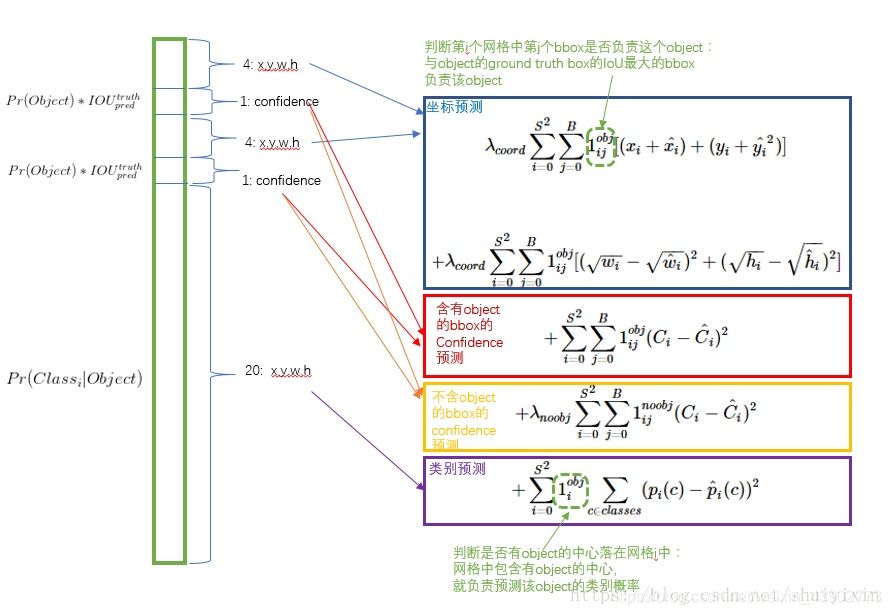
损失函数分析:
3. YOLO v2
v2版本解决了v1中存在的两个问题:
- 框的预测准确度不足
- recall不足
相较于v1版本中直接预测x,y,w,h的不同,v2版本采用预测偏移量的做法。基于Anchor框的宽和高和grid的先验位置的偏移量,得到最终目标的位置。原因是直接预测位置会导致神经网络在一开始训练时不稳定,使用偏移量会使得训练过程更加稳定,性能指标提升了5%左右。这样就解决了框的预测准确度不够的问题。
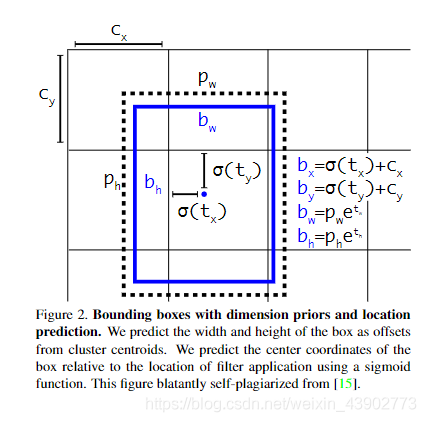
对于问题二YOLO v2首先把 7 x 7 个区域改为13 x 13个区域,每个区域有5个anchor,且每个anchor对应着1个类别,那么,输出的尺寸就应该为:[N,13,13,125]。
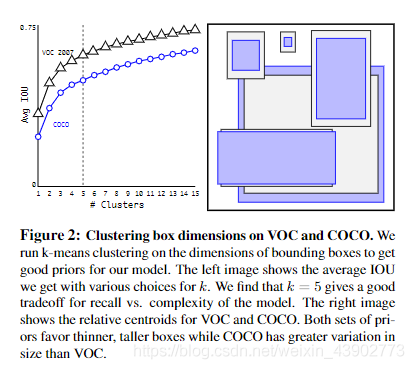
采用5个anchor的原因是,在YOLO v2中,作者观察了很多图片的所有Ground Truth,发现:比如车,GT都是矮胖的长方形,再比如行人,GT都是瘦高的长方形,且宽高比具有相似性。于是作者准备从数据集中预先准备几个几率比较大的bounding box,再以它们为基准进行预测。作者在对VOC和COCO两个数据集上对训练集的GT bounding box进行聚类发现,5类的recall vs. complexity比较好,9类的mAP最好,预测的最全面,但是在复杂度上升很多的同时对模型的准确度提升不大,所以采用了一个比较折中的办法选取了5个聚类簇,即使用5个先验框。从而解决了第二个问题,但对于小目标的检测仍然不佳。
- anchor的选择则是从数据集中统计得到的
4. YOLO v3
YOLO v3的检测头进一步改进,分成了三部分
- 13 * 13 * 3 * (4+1+80)
- 26 * 26 * 3 * (4+1+80)
- 52 * 52 * 3 * (4+1+80)
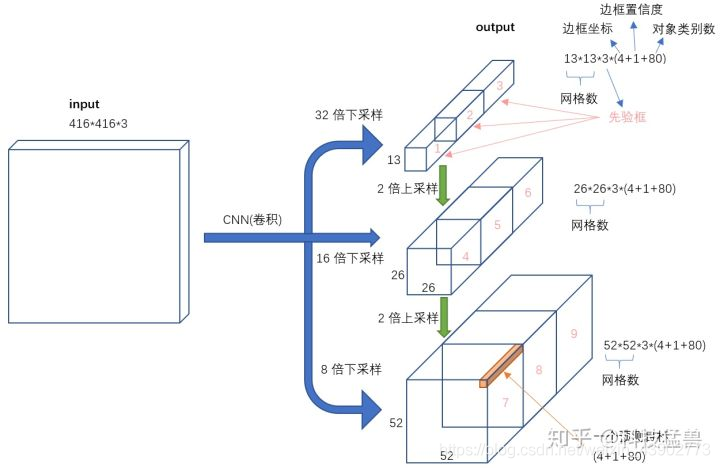
即每个grid设置9个先验框,3个大的,3个中的,3个小的。因为32倍下采样每个点感受野更大,所以去预测大目标,8倍下采样每个点感受野最小,所以去预测小目标。每个分支预测3个框,每个框预测5元组+80个one-hot vector类别,所以一共size是:3*(4+1+80) 总共可以预测 ( 13 ∗ 13 + 26 ∗ 26 + 52 ∗ 52 ) ∗ 3 = 10467 > > ( 13 ∗ 13 ∗ 5 ) = 845 (13 * 13 + 26 * 26 + 52 * 52) * 3 = 10467 >> (13 * 13 * 5) = 845 (13∗13+26∗26+52∗52)∗3=10467>>(13∗13∗5)=845所以相较于v2,v3模型能力有所提升。
YOLO v3 网络结构图
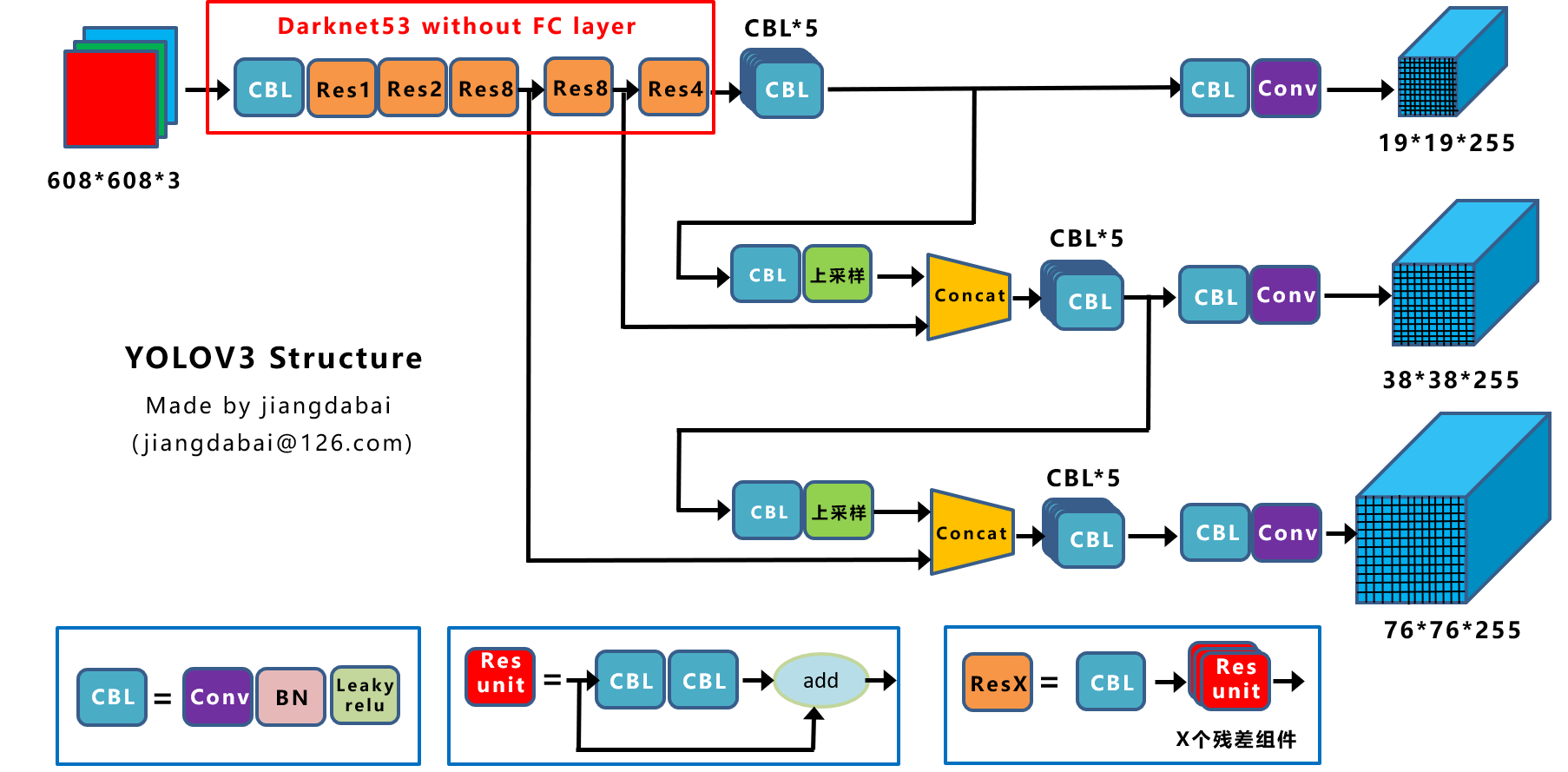
5. YOLO v4
之前的YOLO v3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。方法是:对于 G T j GT_j GTj来说,只要 I o U ( a n c h o r i , G T j ) > t h r e s h o l d IoU(anchor_i,GT_j)>threshold IoU(anchori,GTj)>threshold,就让 a n c h o r i anchor_i anchori去负责 G T j GT_j GTj。目的是框的数量没变,但是选择正样本的比例增加了,缓解了最开始正负样本不均匀的问题。
6. YOLO v5
在检测头部分并未做出改动,但是采用了自适应anchor,之前anchor是固定的,自适应anchor利用网络的学习功能,让 ( x A , y A , w A , h A ) (x_A,y_A,w_A,h_A) (xA,yA,wA,hA)也是可以学习的。
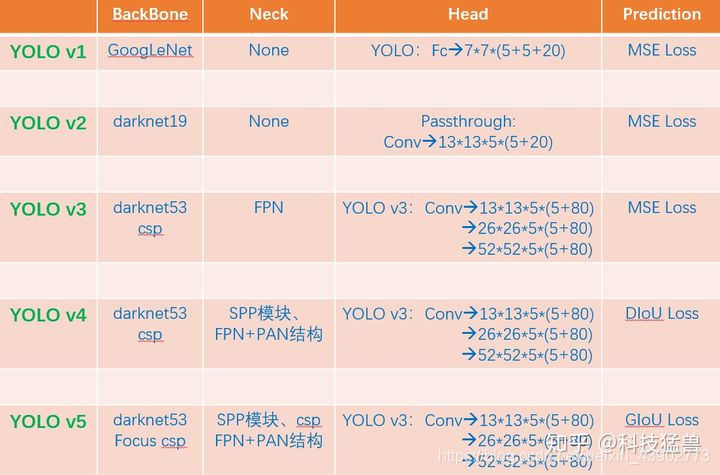
7. YOLO v1 v2 v3 v4 v5 对比图
参考文章
- 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上)
- 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (中)
- 你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (下)
- 深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
- You Only Look Once:Unified, Real-Time Object Detection
- YOLO9000:Better, Faster, Stronger
- YOLOv3: An Incremental Improvement
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOX: Exceeding YOLO Series in 2021