最近被朋友问到HashMap相关知识,感觉自己不是很清楚,就做了一个总结,如下
问:hashmap是怎么计算index的下角标位置的呢
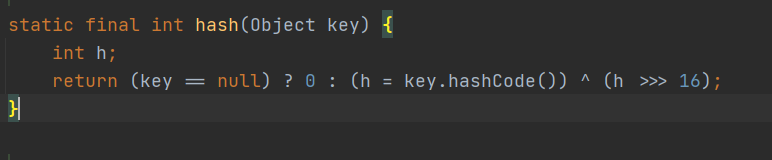
答: 首先看一下put时计算hash的方法,先是计算出key的hashcode,然后key的hashcode右移16位,最后在用key的hashcode只与右移后的值进行与运算,
添加位运算的公式

注意标红的地方,最后&运算,计算得出index的下角标位置

问:hashmap存放是有序存放还是无序存放?
答:存放是无序存放,使用单向链表,如果想有序使用LinkedHashmap,使用双向链表,在效率方面Linkedashmap比hashmap要低
问:hashmap中如何解决hash冲突问题
答:(使用数组的长度-1)& hash值
问:为什么从写equals还要重下hashcode方法
答:首先equals相等的话,hashcode值一定相等,hashcode值相等的话,内容值不一定相等。
在set集合中,因为他存储的是不重复的对象,依据hashcode和equals判断,必须重写这两个方法
如果是自定义对象作为map的key,也必须必须重写这hashcode和equals方法
问:使用hashmap的时候如何避免内存泄漏
答:重写这hashcode和equals方法,如果不重写的话,假如你用的是自定义对象作为key,无法实现gc,导致内存泄露。
问:hashmap根据key查询的时间复杂度
答:如果key不冲突 O(1)
key冲突的话,链表的话 O(n),红黑树的话o(logn)
问:hashmap1.7和1.8的区别
答:数据结构 1.7数组+链表
1.8数组+链表+红黑树
时间复杂度:1.8的时候会存在o(logn) 情况
1.7的话采用头插法,多线程会存在死循环的现象
1.8的话链表采用尾插法,避免了死循环的现象
问:为什么加载因子是0.75
答:如果是1的话,假如初始长度是16,需要满的时候才会扩容,那么万一在15个之后,每次put的值都发生hash冲突,在遍历的时候查询效率就不高,相反越小的话,反浪费也比较高,根据时间和空间利用率来说,根据松波分布,0.75是最为合适
问:hashmap如何存放1w条数据效率最高
答:如果效率高的话,首先是避免扩容,采用设定初始容量的方法,初始容量等于=存放数/0.75+1
问:在遍历map的时候,存放一个新的key,会发生什么,存放一个已经存在的key会发生什么?
答: 存放一个新的key会报错,存放一个已经存在的key,会覆盖原来的值 ,这里重点说一个modcount,在修改值的时候不会++,在添加新的值的时候会++,遍历的时候会比较这个值,如果发生变化就会报错。

**
此次分享就这么多,如果其他知识点可以留言 ,谢谢
**