官方文档 -> https://kubernetes.io/zh/docs/home/
@Kubernetes 是什么?
https://v1-21.docs.kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/
| 访问和工具层 | Web控制台、RESTful API、日志、监控、CI/CD |
| PaaS服务层 | 统一服务平台 |
| 容器编排层 | K8S |
| 容器引擎层 | Docker |
| IaaS基础设施层 | 提供基础运行环境(物理机、虚拟机、网络、存储……) |
注意:Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 相比之下,Kubernetes 包含一组独立的、可组合的控制过程, 这些过程连续地将当前状态驱动到所提供的所需状态。 如何从 A 到 C 的方式无关紧要,也不需要集中控制,这使得系统更易于使用 且功能更强大、系统更健壮、更为弹性和可扩展。
@Kubernetes 为你提供...
- 服务发现和负载均衡
- 存储编排
- 自动部署和回滚
- 自动完成装箱计算 -> 允许指定每个容器所需 CPU 和内存(RAM),当容器指定了资源请求时,Kubernetes可以做出更好的决策来管理容器的资源。
- 自我修复
- 密钥与配置管理
@Kubernetes 组件
https://v1-21.docs.kubernetes.io/zh/docs/concepts/overview/components/
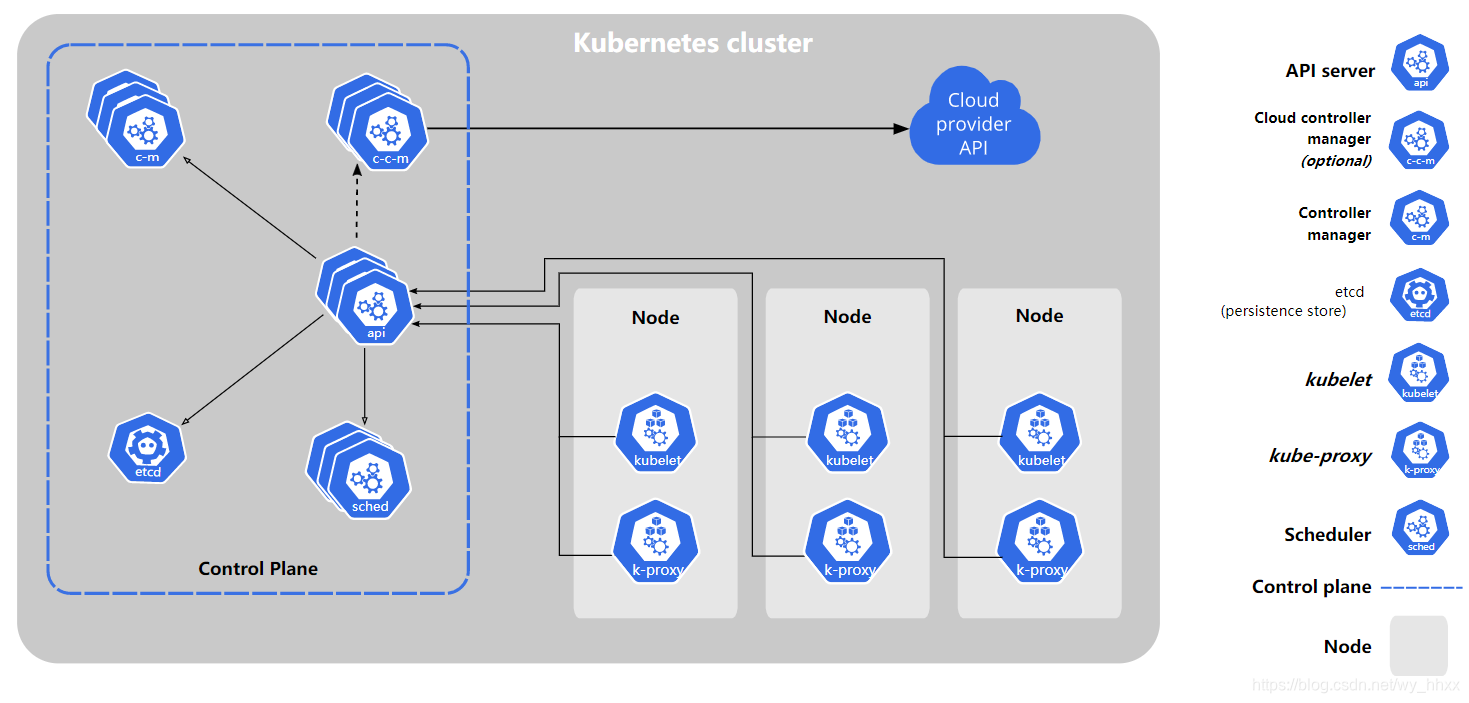
说明: 通常会在同一个计算机上启动所有控制平面组件,所以图中的控制平面(Control Plane)可以理解成Master节点
Master组件(3个,kube-apiserver、kube-scheduler、kube-controller-manager)
| kube-apiserver | 集群的统一入口,各组件协调者,以RESTful API提供接口服务。所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给etcd存储 |
| etcd | 不算是Master组件,可以部署在Master上。 etcd 是兼具一致性和高可用性的键值数据库。用于保存集群状态数据,比如Pod、Service等对象信息。 |
| kube-scheduler | 负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。 |
| kube-controller-manager | 处理集群中常规后台任务,一个资源对应一个控制器,而 ControllerManager就是负责管理这些控制器的。 |
Node组件
| kubelet | 是集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。 kubelet 不会管理不是由 Kubernetes 创建的容器。 |
| kube-proxy | 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service)概念的一部分。 维护节点上的网络规则和实现四层负载均衡。 |
| 容器运行时(Container Runtime) | 负责运行容器的软件,例如: Docker、 containerd、CRI-O |
@使用kubeadm部署集群
https://v1-20.docs.kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/ (步骤1-6)
https://v1-20.docs.kubernetes.io/zh/docs/reference/setup-tools/kubeadm/kubeadm-init/ (步骤7)
https://v1-20.docs.kubernetes.io/zh/docs/reference/setup-tools/kubeadm/kubeadm-join/ (步骤8)
例如有3台VM,下述步骤1-6在每个VM都要执行
1.确保每个节点上 MAC 地址和 product_uuid 的唯一性
你可以使用命令 ip link 或 ifconfig -a 来获取网络接口的 MAC 地址
可以使用 sudo cat /sys/class/dmi/id/product_uuid 命令对 product_uuid 校验
2.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld3.关闭selinux
# 永久关闭
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 临时关闭
setenforce 0 4.允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system5.安装 runtime,例如docker
6.安装 kubeadm、kubelet 和 kubectl,可以指定版本
yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
systemctl enable kubelet说明:
kubeadm 初始化集群的指令。
kubelet 在集群中的每个节点上用来启动 Pod 和容器等。
kubectl 与集群通信的命令行工具。
步骤7在Master节点执行
7.部署Master节点
kubeadm init 此命令初始化一个 Kubernetes 控制平面节点
kubeadm init \
--apiserver-advertise-address=<Master IP> \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.20.0 \
--service-cidr=x.x.x.x/xx \
--pod-network-cidr=y.y.y.y/yy \
--ignore-preflight-errors=all说明1:
-apiserver-advertise-address 集群通告地址
--image-repository 默认拉取镜像地址k8s.gcr.io,这里指定阿里云镜像仓库地址
--kubernetes-version K8s版本
--service-cidr 默认值为"10.96.0.0/12",为服务的虚拟IP地址指定IP地址段,Pod统一访问入口
--pod-network-cidr 指明 pod 网络可以使用的 IP 地址段,注意与之后部署容器网络(CNI)里面定义Pod网络一致
--ignore-preflight-errors stringSlice 错误将显示为警告的检查列表,取值为"all"时将忽略检查中的所有错误
说明2:
--service-cidr 10.96.0.0/12,于是稍后起了服务给service分的CLUSTER-IP就是这个网段的
[root@k8s-master ~]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d <none>
nginx NodePort 10.105.63.231 <none> 80:32155/TCP 13d app=nginx--pod-network-cidr=10.244.0.0/16,于是稍后起了服务给pod分的IP就是这个网段的
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-58f8c48d58-48xbn 1/1 Running 2 10d 10.244.169.173 k8s-node2 <none> <none>
[root@k8s-master ~]#执行kubeadm init最后会打印如下信息
...
our Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
(说明:在Master节点执行下述蓝色命令)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
(说明:记录下述紫色命令,在每个Node执行使其加入集群)
kubeadm join 192.168.231.121:6443 --token cqqj2t.gwkj57io7aue66mr \
--discovery-token-ca-cert-hash sha256:ac272bbfc0a687db9a37099f440ff0dc0f684909117aa501ee3cd4b7474ae7b0
[root@k8s-master ~]#
步骤8在每个Node节点执行
8.加入工作节点到集群
每台Node执行上述kubeadm init步骤最后得到的kubeadm join命令
步骤9在Master节点执行
9.部署容器网络(CNI),以calico为例
下载yaml -> wget https://docs.projectcalico.org/manifests/calico.yaml
修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kubeadm init的 --pod-network-cidr指定的一样。
执行 kubectl apply -f calico.yaml
kubectl get pods -n kube-system 查看calico网络部署结果
kubectl get nodes 查看集群部署结果
(END)