第八章 多副本一致性(2学时)
内容:一致性模型,分发协议,一致性协议。
要求:掌握分布式系统中,数据存储多副本的目的是为了提高系统的可靠性和性能,掌握数据为中心的7种一致性模式和客户为中心的4中一致性模型,掌握分发协议中更新传播的模式,掌握主-从副本协议和复制写协议的原理与执行过程。

一致性模型(考试重点)



图中水平线表示客户进程对其数据存储副本执行操作,带箭头的虚线表示写操作向其他副本的传播修改。a中,客户A在其副本上对数据存储的数据项x执行写操作,写入值为a,同时向副本B传播写操作。客户B的副本接受客户A写操作传播,修改数据项x,然后对数据项x执行读操作,得到值a.
而b中没有达到严格一致性,因为B读到的不是a,而是数据项x的初值NULL,客户A的写操作没有立即传播到B,未能及时完成对副本的修改。
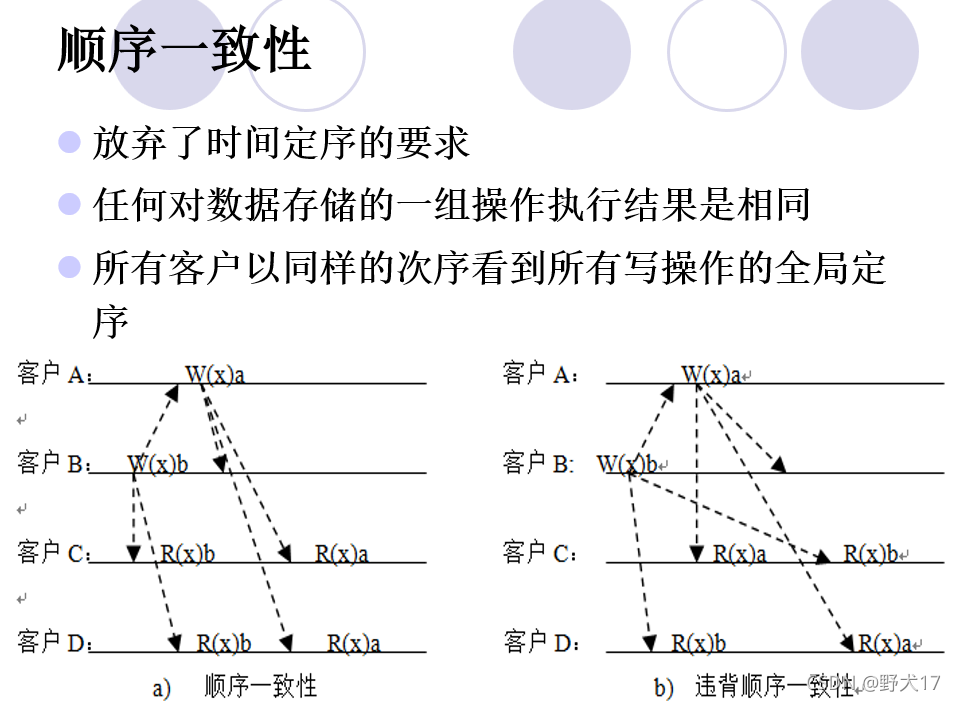
图a是顺序一致性,因为C和D都是先看到数据项x写b,再写a.
如果C,D都是先写a,再写b,那么也是顺序一致性。
但是图b不是顺序一致性。
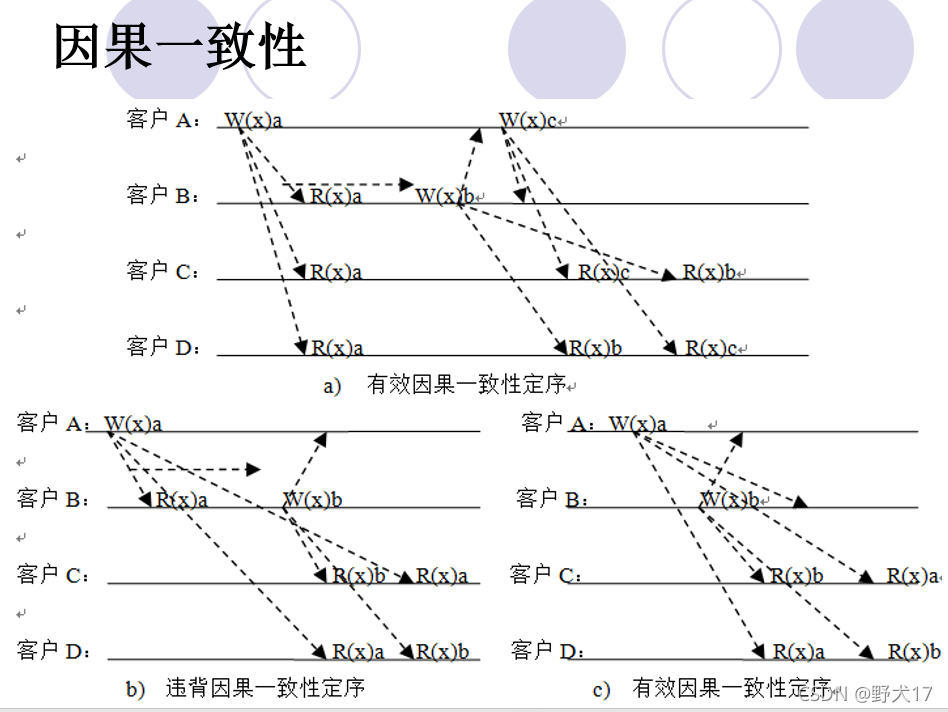
图a中,客户A的写操作W(x)a与客户B的写操作W(x)b有因果关系,所以C,D看到的是相同的定序,即先读出数据项x的值为啊,再读出b。
图C中,W(x)a和W(x)b是并发写的,也符合因果一致性要求。
图b中,C,D看到的定序不同,违背了因果一致性要求。
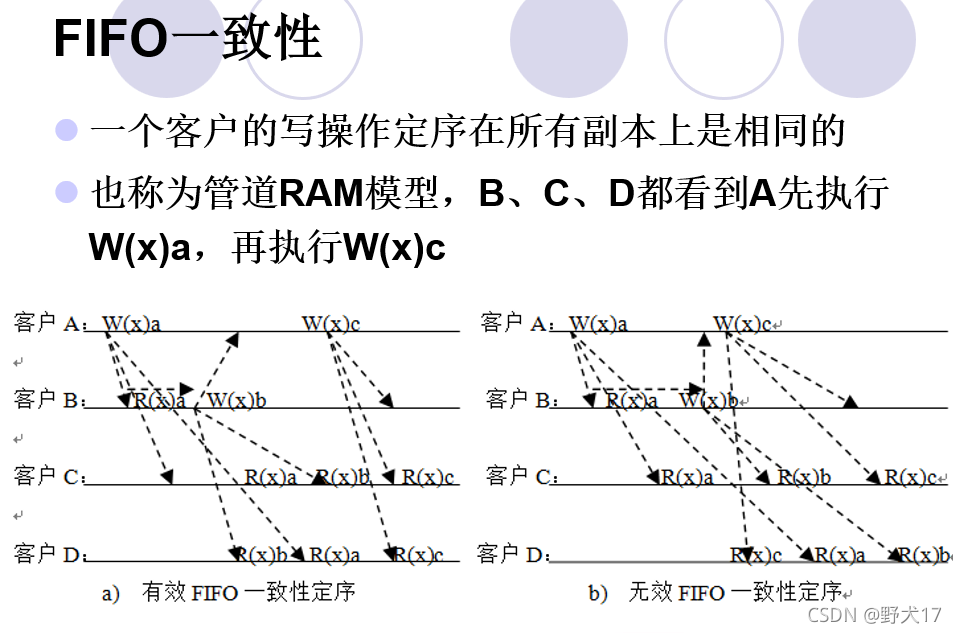
在讨论FIFO一致性时,我们并不在乎这个程序是否是否遵循其他的一致性,就像图a中,尽管它并不遵循因果一致性,但是对于这个系统中,C,D都是先看大客户A执行W(x)a,后执行W(x)c,因此遵循FIFO一致性。
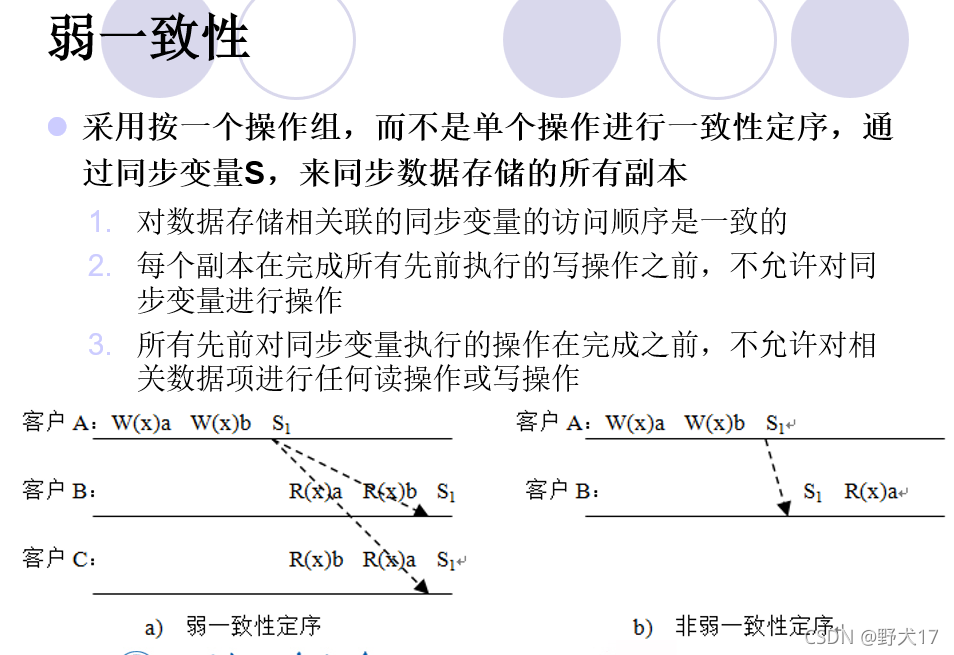
在图a中,客户A对数据项x执行了两次写操作,先后写入a和b,然后执行同步操作S1,这两个写操作就构成了一个操作组(指令组)。如果客户B和客户C还没有完成同步操作S1,对它们看到的东西无法做出保证,其中的事件顺序被认为是有效的。在b中,客户B已经完成了S1操作,本地副本已经更新了,它看到的应该是b,而不是a,因此客户B的副本不是按照弱一致性定序执行写操作。





分发协议(考试重点)
有关多副本实现的一个问题是:副本放置在何处?创建多少个副本?谁负责副本的创建于维护?何时创建副本?客户如何发现和连接到合适的副本?
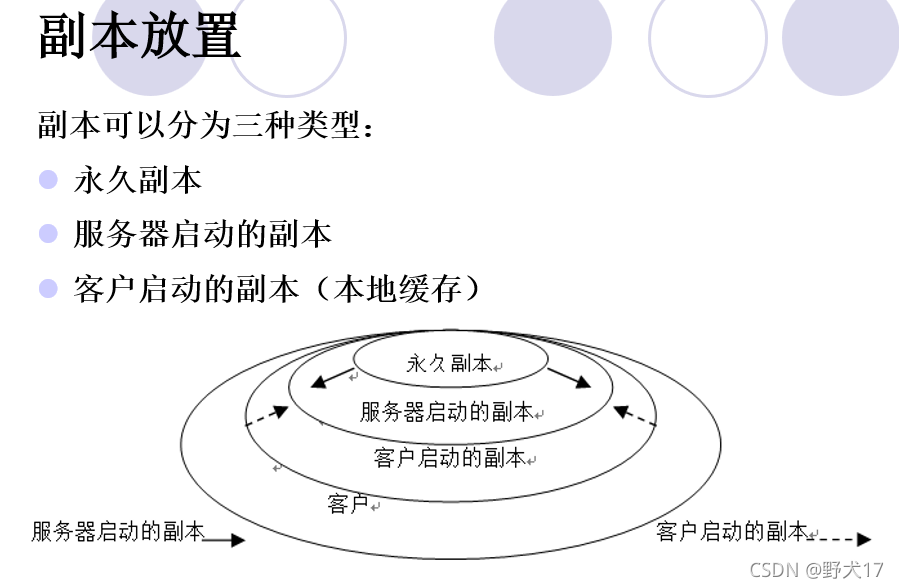
永久副本
永久副本是由数据存储的拥有者创建和管理,且作为数据拥有者的数据固定存储。这类多副本的目的包含满足容错要求。永久副本或多或少是静态配置的。一般情况下,永久副本的数量很少,被视为分布式数据存储多副本的最初集合。它的形式可以是单个服务器,或者一个集群,或者一个镜像组。
服务器启动的副本
服务器启动的副本的目的是增强系统的性能,它们是应数据存储拥有者的请求根据永久副本而创建的,常常放置在另外的服务器中。尽管有时要求服务器启动的副本于永久副本有同样长的时间周期,但一般都是短于永久副本。
为了改进系统性能,服务器启动的副本放置在用户集中的地方。
服务器启动副本的一个问题就是决定创建或者删除副本的确切位置和时间。

更新传播:
对分布式副本数据存储的数据更新是用户启动的。数据更新应传播到所有的副本,对所有副本执行修改操作,以保持副本的一致性。
下面来讨论传播数据更新要考虑的一些设计问题。

数据更新设计的第二个问题是谁启动更新传播,即更新是“拉”的方式还是“推”的方式。“拉”的方式是由客户启动,“推”的方式由服务器启动。


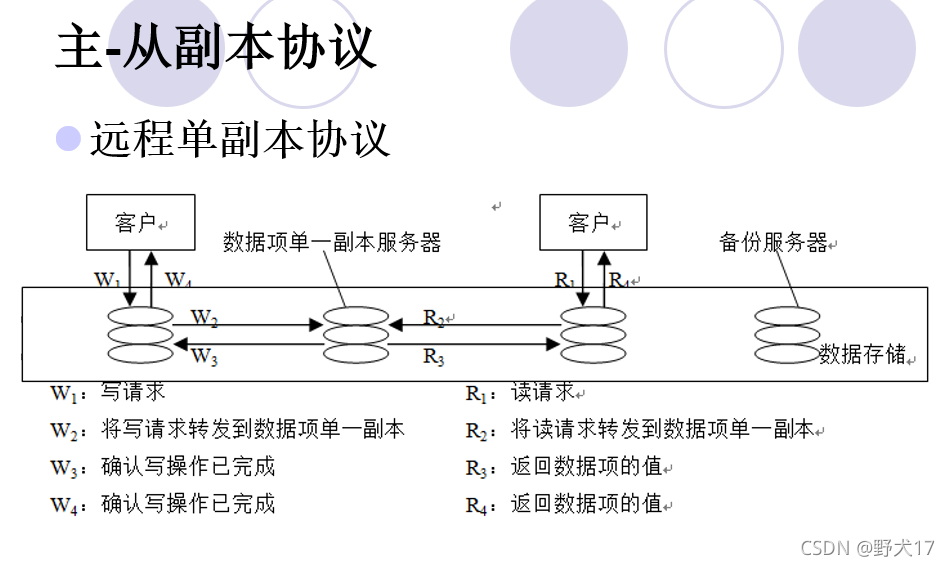
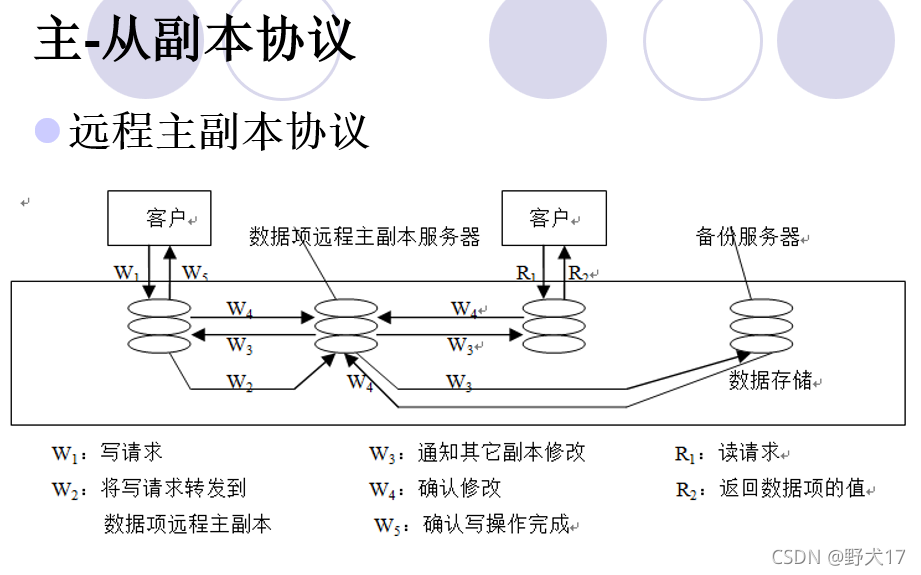
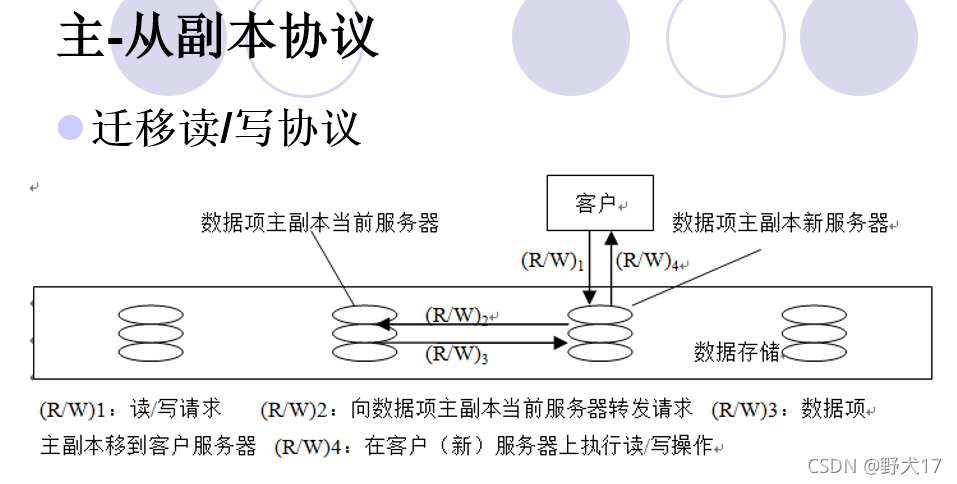
一致性协议


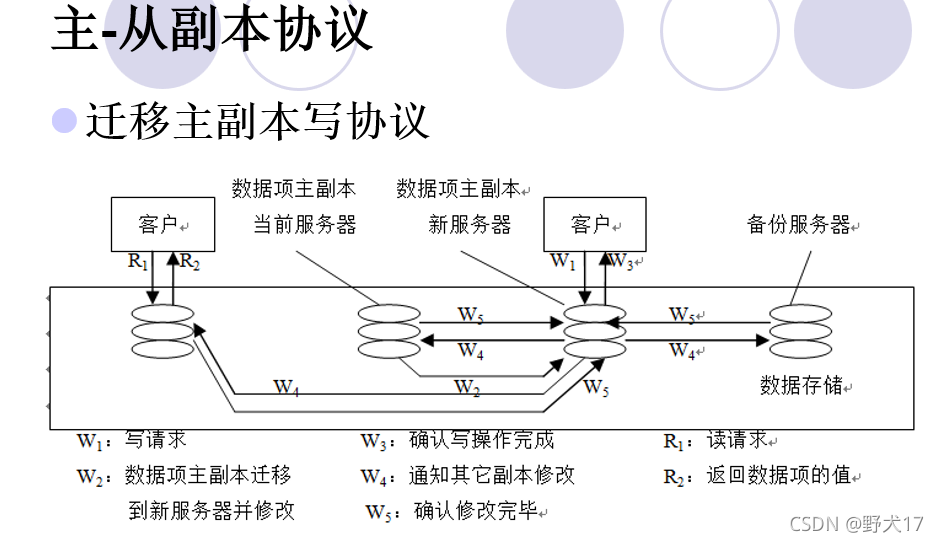
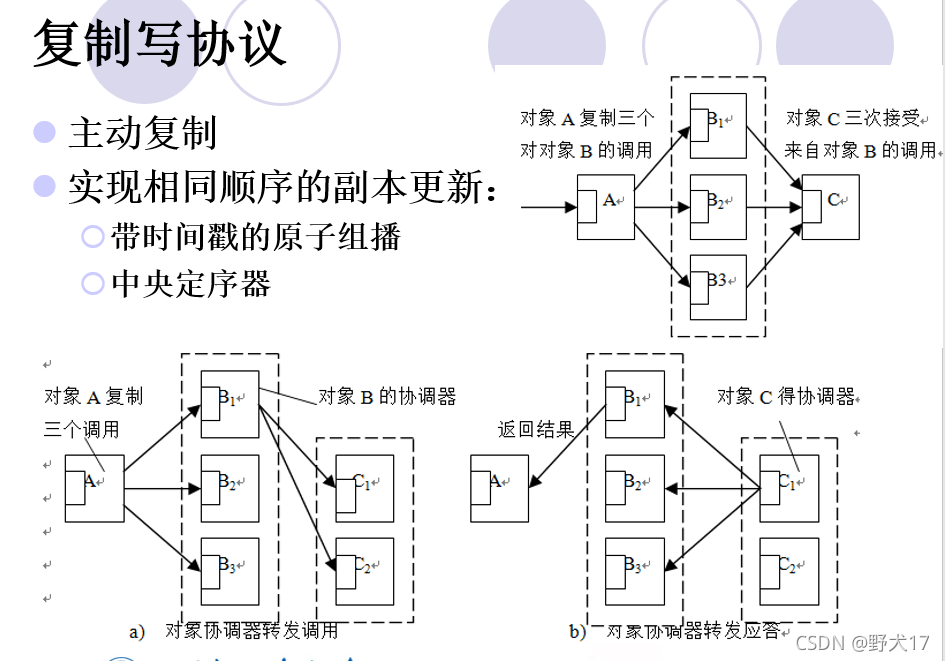
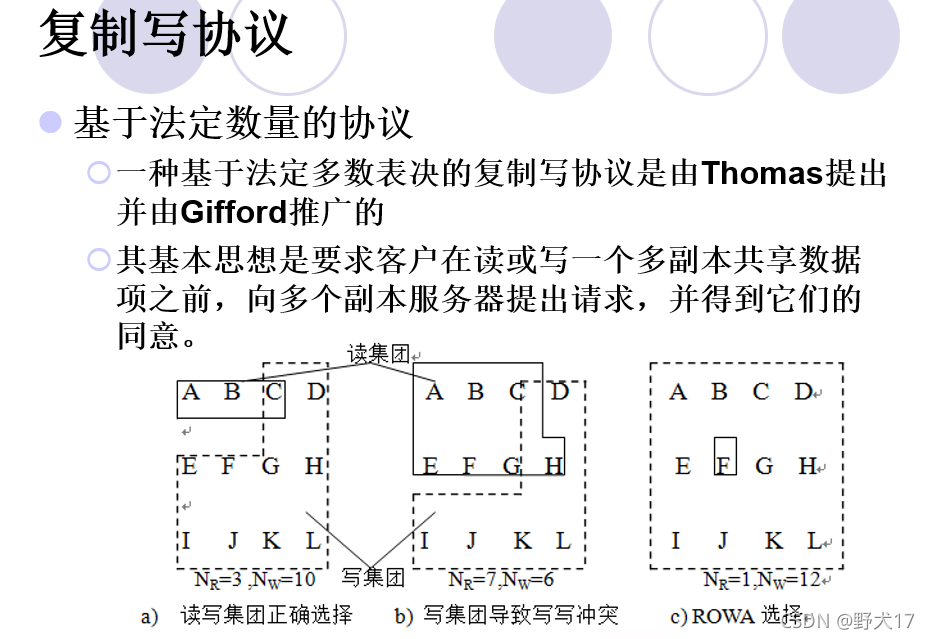

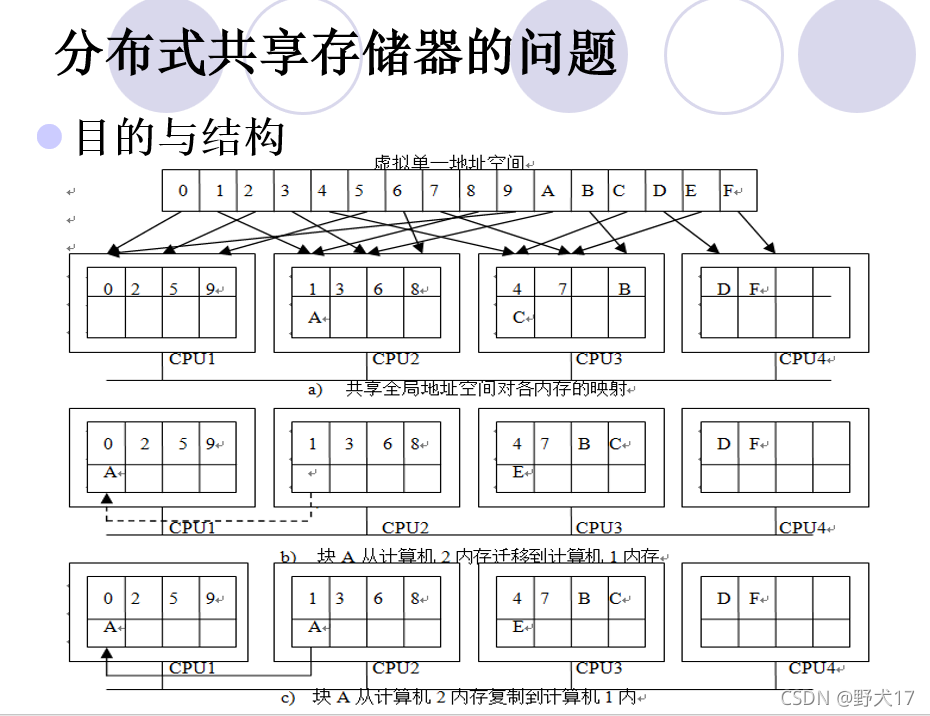
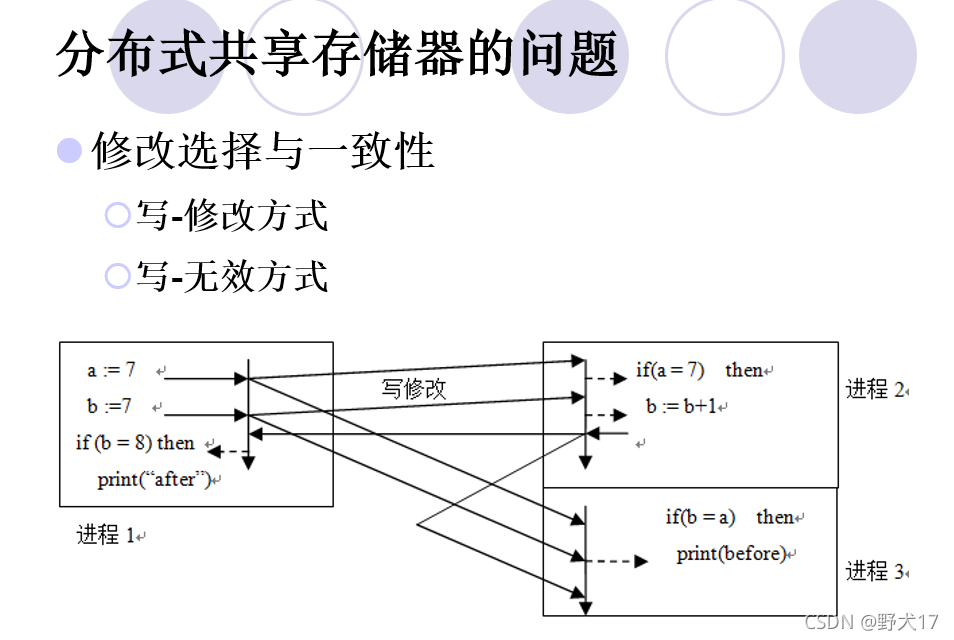
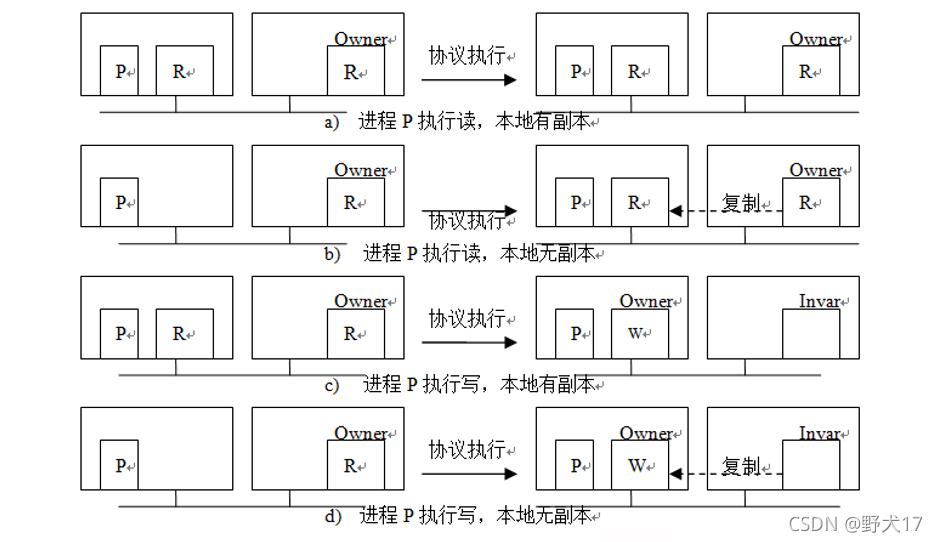
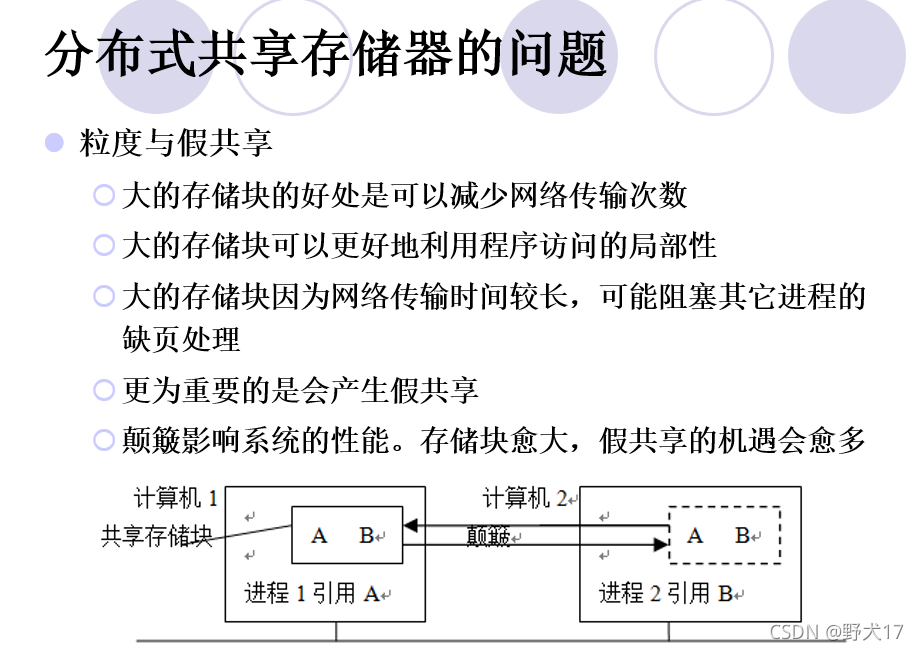
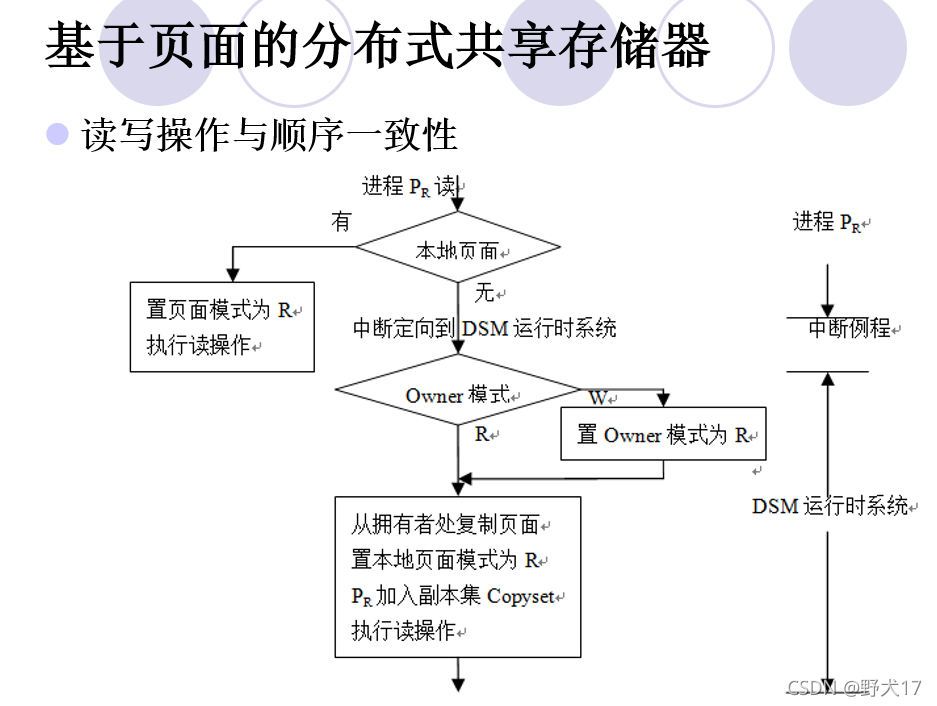
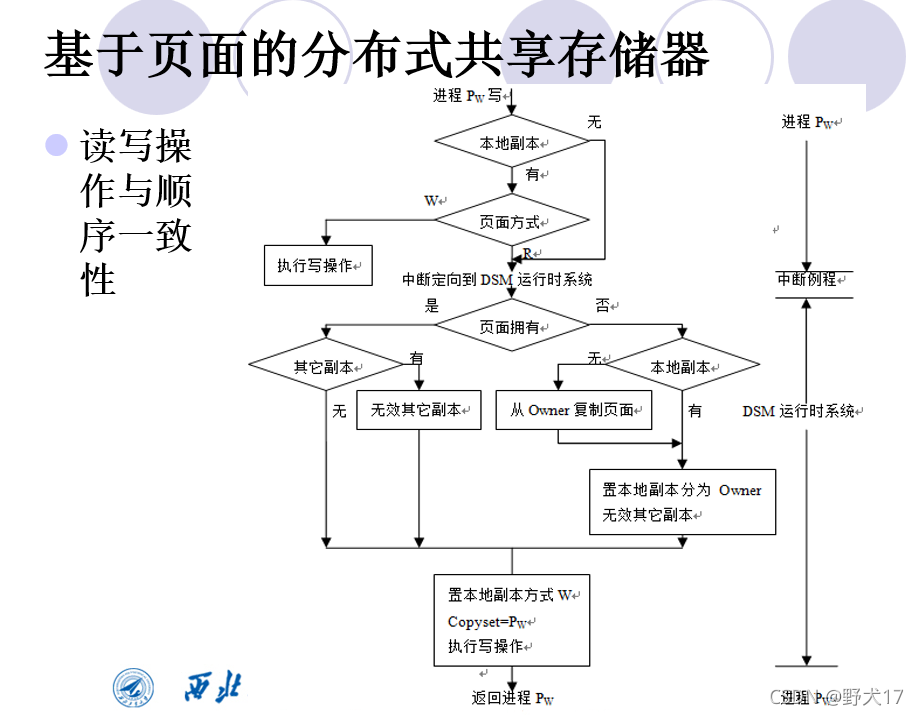
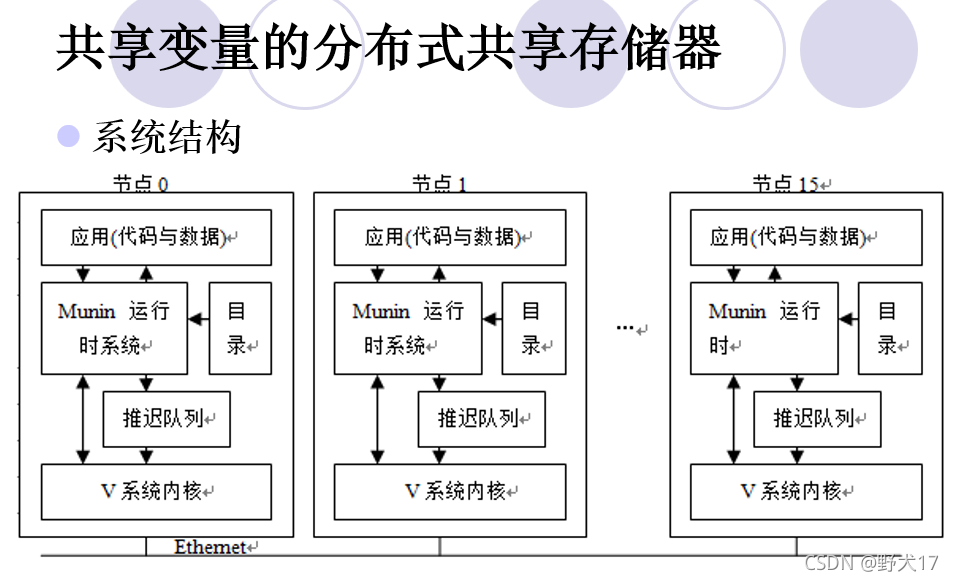
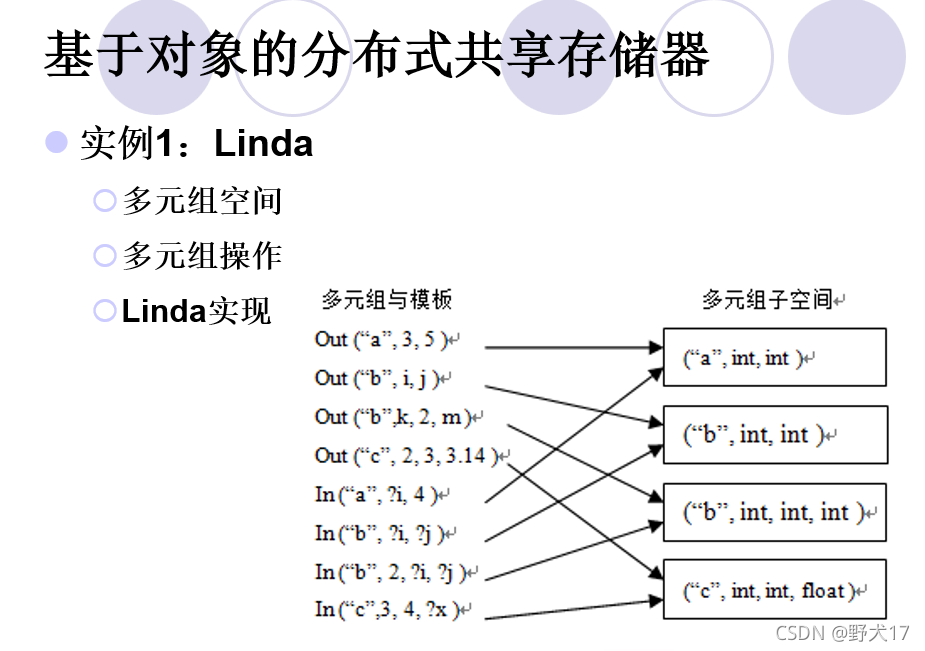
分布式共享存储器(不考)