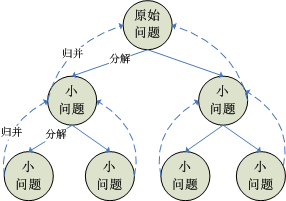
分治,字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。在计算机科学中,分治法就是运用分治思想的一种很重要的算法。分治法是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅里叶变换)等等。
目录
- 1 分治法
- 2 适用条件
- 3 设计步骤
- 4 大整数乘法
分治法
在求解一个输入规模为n,而n的取值又很大的问题时,直接求解往往非常困难。这时,可以先分析问题本身所具有的某些特性,然后从这些特性出发,选择某些适当的设计策略来求解。这种方法,就是所谓的分治法。
适用条件
采用分治法解决的问题一般具有的特征如下:
1. 问题的规模缩小到一定的规模就可以较容易地解决。
2. 问题可以分解为若干个规模较小的模式相同的子问题,即该问题具有最优子结构性质。
3. 合并问题分解出的子问题的解可以得到问题的解。
4. 问题所分解出的各个子问题之间是独立的,即子问题之间不存在公共的子问题。
设计步骤
1. 划分步:把输入的问题划分为k个子问题,并尽量使这k个子问题的规模大致相同。
2. 治理步:当问题的规模大于某个预定的n0时阈值,治理步由k个递归调用组成。
3. 组合步:组合步把各个子问题的解组合起来,它对分治计算的实际性能至关重要,算法的有效性很大地依赖于组合步的实现。
分治法的关键是算法的组合步。究竟应该怎样合并,没有统一的模式,因此需要对具体问题进行具体分析,以得出比较好的合并算法。
大整数乘法
通常,在分析一个算法的计算复杂性时,一般将加法和乘法运算当作是基本运算来处理,即将执行一次加法或乘法运算所需的计算时间,看作一个仅仅取决于计算机硬件处理速度的常数。
然而,在有些情况下,需要处理数值很大的整数,这些数值无法在计算机硬件能直接表示的范围内进行处理。如果要精确地表示大整数的数值并在计算结果中要求精确地得到所有位数上的数字,就必须用软件的方法来实现大整数的算术运算,即用分治法实现大整数的运算。另外,分治法实现大整数运算,可以大大提高运算效率。
设两个n(na,nb)位d进制数A、B相乘:
当位数n为偶数时,将数拆分为两段等长的数段,高位段为H,低位段为L,则有
A=Ha*d^(n/2)+La B=Hb*d^(n/2)+Lb
当位数n为奇数时,可在数的首位前添0,使数的位数为偶数,然后将数拆分为两段等长的数段。
例如,计算2进制数1010与1110的乘积。步骤如下:
(1):1010=10*2^(2)+10 1110=11*2^(2)+10
(2):1010*1110=(10*2^(2)+10)*(11*2^(2)+10)=10*11*2^(4)+10*11*2^(2)+10*10*2^(2)+10*10
(3):1010*1110=(1*2^(1)+0)*(1*2^(1)+1)*2^(4)+(1*2^(1)+0)*(1*2^(1)+1)*2^(2)+(1*2^(1)+0)*(1*2^(1)+0)*2^(2)+(1*2^(1)+0)*(1*2^(1)+0)=2*3*16+2*3*4+2*2*4+2*2=140
词条图册
下面是归并排序的代码:
非递归代码:
#include<iostream>
#include<ctime>
#include<cstring>
#include<cstdlib>
using namespace std;
void Merge(int* data,int a,int b,int length,int n){
int right;
if(b+length-1 >= n-1) right = n-b;
else right = length;
int* temp = new int[length+right];
int i=0, j=0;
while(i<=length-1 && j<=right-1){
if(data[a+i] <= data[b+j]){
temp[i+j] = data[a+i];i++;
}
else{
temp[i+j] = data[b+j];
j++;
}
}
if(j == right){
memcpy(temp + i + j, data + a + i, (length - i) * sizeof(int));
}
else if(i == length){
memcpy(temp + i + j, data + b + j, (right - j)*sizeof(int));
}
memcpy(data+a, temp, (right + length) * sizeof(int));
delete [] temp;
}
void MergeSort(int* data, int n){
int step = 1;
while(step < n){
for(int i=0; i<=n-step-1; i+=2*step)
Merge(data, i, i+step, step, n);
}
}
int main(){
int n;
cin>>n;
int* data = new int[n];
if(!data) exit(1);
int k = n;
while(k--){
cin>>data[n-k-1];
}
clock_t s = clock();
MergeSort(data, n);
clock_t e = clock();
k=n;
while(k--){
cout<<data[n-k-1]<<' ';
}
cout<<endl;
cout<<"the algorithm used"<<e-s<<"miliseconds."<<endl;
delete data;
return 0;
}
使用递归:
#include<iostream>
using namespace std;
void merge(int *data, int start, int mid, int end, int *result)
{
int i, j, k;
i = start;
j = mid + 1;
k = 0;
while (i <= mid && j <= end)
{
if (data[i] <= data[j]) data[j]
result[k++] = data[i++];
else
result[k++] = data[j++];
}
while (i <= mid)
result[k++] = data[i++];
while (j <= end)
result[k++] = data[j++];
for (i = 0; i < k; i++)
data[start + i] = result[i];
}
void merge_sort(int *data, int start, int end, int *result)
{
if (start < end)
{
int mid = start + (end-start) / 2;
merge_sort(data, start, mid, result);
merge_sort(data, mid + 1, end, result);
merge(data, start, mid, end, result);
}
}
void amalgamation(int *data1, int *data2, int *result)
{
for (int i = 0; i < 10; i++)
result[i] = data1[i];
for (int i = 0; i < 10; i++)
result[i + 10] = data2[i];
}
int main()
{
int data1[10] = { 1,7,6,4,9,14,19,100,55,10 };
int data2[10] = { 2,6,8,99,45,63,102,556,10,41 };
int *result = new int[20];
int *result1 = new int[20];
amalgamation(data1, data2, result);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
cout << endl;
merge_sort(result, 0, 19, result1);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
delete[]result;
delete[]result1;
return 0;
}
学会了吗?