https://blog.csdn.net/zf18234031156/article/details/103047649
反复做这一步,30多个文件一个一个弄,有乱码用txt打开,黏贴覆盖,
目录
1.前言
2.原因(UTF-8+BOM造成)
3.如何解决
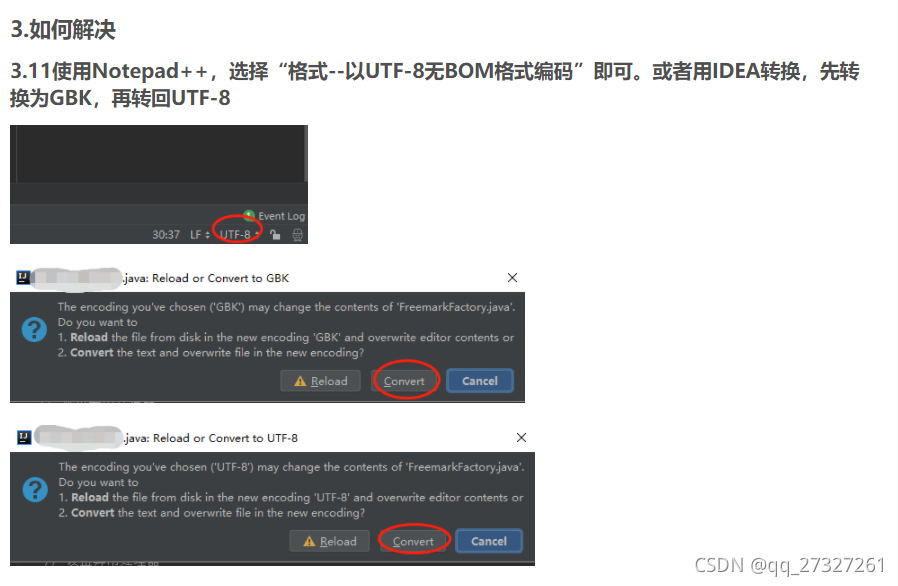
3.11使用Notepad++,选择“格式--以UTF-8无BOM格式编码”即可。或者用IDEA转换,先转换为GBK,再转回UTF-8
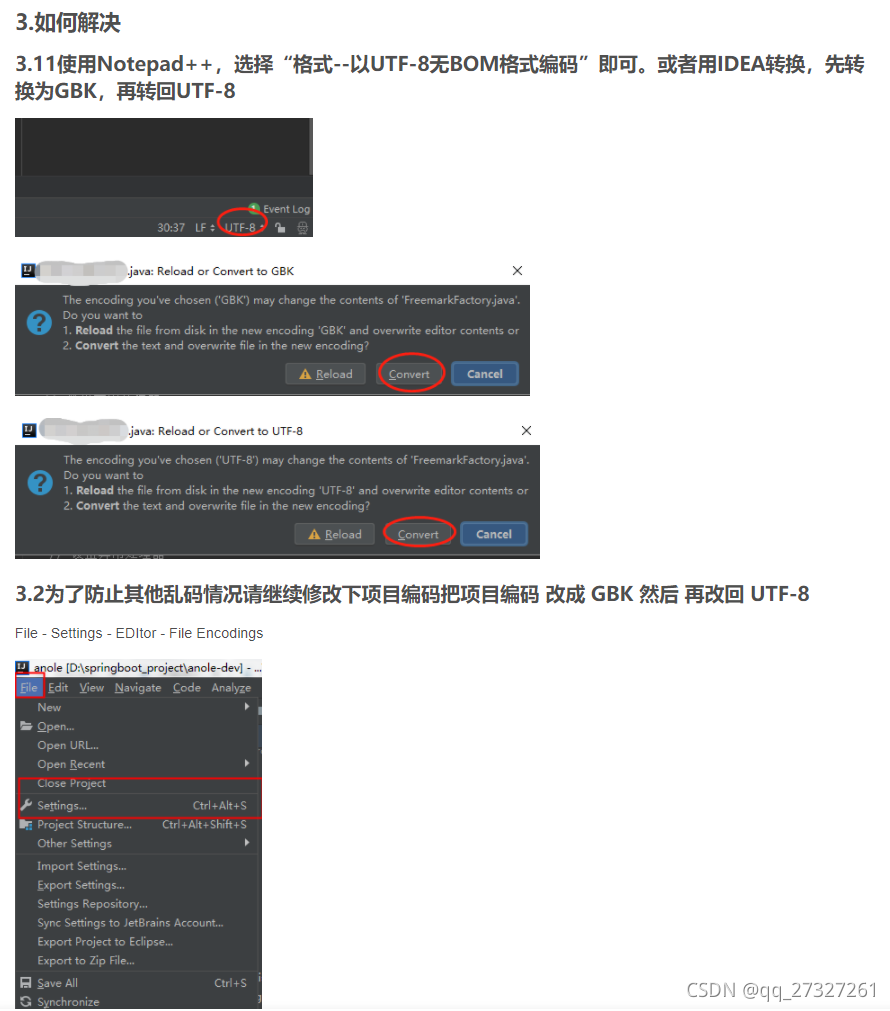
3.2为了防止其他乱码情况请继续修改下项目编码把项目编码 改成 GBK 然后 再改回 UTF-8
4.BOM相关了解
1.前言
之前一直在STS(eclipse的包装版)中进行开发,今天想用ideaiu进行开发,启动项目后报了Error:(1, 10) java: 需要class, interface或enum的问题。
2.原因(UTF-8+BOM造成)
原因还是编码的问题,eclipse会智能的UTF-8+BOM文件转换为普通的UTF-8文件,但是在ideaiu中是没有这种智能转换的。
什么是BOM(Byte Order Mark,就是字节序标记)
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE“(零宽度无间距空间)的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。
UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE“。
如果接收者收到FEFF,就表明这个字节流是大字节序的;如果收到FFFE,就表明这个字节流是小字节序的。因此字符”ZERO WIDTH NO-BREAK SPACE“又被称作BOM
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE“的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
意思就是UTF-8文件有两种一种是前面带有字符ZERO WIDTH NO-BREAK SPACE(BOM)的UTF-8文件,一种是前面不带BOM的UTF-8文件。虽然都是UTF-8但还是会出现编码问题。
3.如何解决
3.11使用Notepad++,选择“格式--以UTF-8无BOM格式编码”即可。或者用IDEA转换,先转换为GBK,再转回UTF-8
3.2为了防止其他乱码情况请继续修改下项目编码把项目编码 改成 GBK 然后 再改回 UTF-8
File - Settings - EDItor - File Encodings
重新编译后 整个项目的乱码问题就解决了
4.BOM相关了解
https://blog.csdn.net/weixin_33656548/article/details/79724045
https://www.cnblogs.com/codingmengmeng/p/11028744.html
https://blog.csdn.net/LegendaryHsl/article/details/78794121
————————————————
版权声明:本文为CSDN博主「zf18234031156」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zf18234031156/article/details/103047649