Redis实战Demo
说明:本项目来自于学相伴飞哥的Redis教程:https://www.kuangstudy.com/,课程优质,收获很大!
项目gitee地址: https://gitee.com/ryt9806/redis-live-demo.git
本项目用于redis实现文章的pv统计、黑白名单问题、抽奖功能以及微信抢红包功能!
我这里项目 用到的是 连接远程服务器上安装的redis
1、实现文章的PV统计
使用Redis 中 的 String类型
@Controller
public class BbsTopicPvController {
@Autowired
private RedisTemplate redisTemplate;
/**
* 1、问题:如果访问 量不是很大,确实就可以解决业务问题了
* 2、但是如果访问量很大,10W + 10W文章 =10亿
* 3、文章和数据存入db,浏览数要做同步db操作!
*/
@GetMapping("/bbs/detail/{id}")
public String pvcount(@PathVariable("id") Integer id, Model model){
// 1: redis访问量进行叠加 并且存入到 redis 中! incr bbs:1
Long increment = redisTemplate.opsForValue().increment("bbs:" + id);
// 2: 增加的浏览数返回给 前端!
model.addAttribute("increment",increment);
return "pv01/index";
}
}
总结: Redis的 incr命令 实现文章浏览量的统计!
2、实现黑白名单过滤问题
使用Redis 中 的 Set 数据结构
黑白名单过滤器是在实际开发中有很多种:比如用户黑名单,IP黑名单等。在一些场景下,如果仅仅通过数据库DB来进行过滤处理。在并发量下的情况下是没有问题。但是如果在高并发的场景下,可能就会出现性能瓶颈,这个时候采用redis来实现是最佳的选择方案。如何进行开发和处理呢?答案是:redis中的数据结构 set。
-
先把黑名单的用户数据放入到redis的集合中或者在举报的时候把用户放入到黑名单中。
-
然后在登录或者评价或者在一些需要限制的地方,通过sismember命令来查询用户是否在黑名单列表中,如果存在就返回1,不存在就返回0
具体实现
@RestController
public class BlackListController {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private BlackUserListService blackUserListService;
public final static String BLACK_LIST_KEY = "blacklist:users";
// 判断用户是否在黑名单中 就是利用ismember key value
@GetMapping("/blacklist/exist/{id}")
public R existBlacklist(@PathVariable("id") Integer userid){
Boolean b = this.redisTemplate.opsForSet().isMember(BLACK_LIST_KEY, userid);
return b ? R.ok().message("用户"+userid+"在黑名单中") : R.error().message("用户"+userid+"是正常用户");
}
// 添加黑名单
@GetMapping("/blacklist/add")
public R addBlackList(Integer userid){
boolean b = blackUserListService.addBlacklist(userid);
return b ? R.ok().message("当前用户"+userid+"成功的添加到了黑名单中") : R.error().message("用户已经在黑名单中");
}
// 删除黑名单
@GetMapping("/blacklist/del")
public R delBlackList(Integer userid){
boolean b = blackUserListService.delBlacklist(userid);
return b ? R.ok().message("当前用户"+userid+"从黑名单中移除成功") : R.error().message("用户"+userid+"不在黑名单中");
}
}
总结: 利用Redis中 set数据类型 的 ismember来实现黑名单问题!
3、实现抽奖功能
使用Set数据类型来实现!
1、抽奖(奖抽了不移除) 抽K币
抽奖一般一般采用redis的set集合来操作。原因:
1:set集合的特点是元素不重复,可以存储比如:1k币,10k币,100K币 500K币
2:set集合提供了随机读取的方法
具体的技术方案是采用set集合的srandmember命令实现。随机返回set中的一个元素。
package com.kuangstudy.controller;
import com.kuangstudy.service.RandomService;
import com.kuangstudy.vo.R;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
@Log4j2
public class RandomController {
@Autowired
private RandomService randomService;
@Autowired
private RedisTemplate redisTemplate;
// 随机抽奖的方法
@GetMapping("/random/card")
public R randomData(){
try {
String result = null;
// 1、随机在set集合中获取一个元素出来 randomMember 类似于 srandmember key 不会删除集合中的元素 ,可以无限的抽取K币
String randomMember = (String)this.redisTemplate.opsForSet().randomMember(randomService.RANDOM_SET_KEY);
// 2、如果获取到对应的一个随机的成员
if (!StringUtils.isEmpty(randomMember)){
int splitIndex = randomMember.indexOf("#"); // 获取 # 所处的位置
int coin = Integer.valueOf(randomMember.substring(0, splitIndex));// 从 0 到 # 位置(不包括#号)截取,就取出了数值,转化为int类型!
if (coin==0){
result = "谢谢你的参与";
}else if (coin == 10){
result = "获取到了10K币";
}else if(coin==50){
result = "获取到了50K币";
}else if (coin==100){
result = "获取到了100K币";
}else {
result = "谢谢你的参与";
}
if (coin>0){
// 1:抽取成功以后同步到redis的list集合中 ---排名---时间周期--- 7天结束!
// 2: 存储站内信息给对应用户
}
return R.ok().data("message" , result).data("coin" , coin);
}
return R.error().message("抽奖信息已经过期");
}catch (Exception e){
log.error("抽奖失败");
return R.error().message("服务忙!!!");
}
}
}
总结:利用到了Redis集合中的 srandmember来进行随机抽奖!
2、抽奖(奖抽了移除) 抽一等奖 3个 二等奖 6个 三等奖 10个
具体的技术方案是采用set集合的spop命令实现。随机返回set集合中的一个元素。
package com.kuangstudy.controller;
import com.kuangstudy.service.ZhifubaoDrawService;
import com.kuangstudy.vo.R;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Log4j2
public class ZhifubaoDrawController {
@Autowired
private ZhifubaoDrawService zhifubaoDrawService;
@Autowired
private RedisTemplate redisTemplate;
// 随机抽奖的方法
@GetMapping("/zhifubao/card")
public R zhifubaoData(){
try {
String result = null;
// 1、随机在set集合中弹出一个元素出来 pop 类似于 spop key 会删除集合中的元素 抽完就没了
String popit = (String)this.redisTemplate.opsForSet().pop(zhifubaoDrawService.ZHIFUBAO_SET_KEY);
// 2、如果获取到对应的一个随机的成员
if (!StringUtils.isEmpty(popit)){
int splitIndex = popit.indexOf("#"); // 获取 # 所处的位置
int draw = Integer.valueOf(popit.substring(0, splitIndex));// 从 0 到 # 位置(不包括#号)截取,就取出了数值,转化为int类型!
if (draw == 0){
result = "谢谢你的参与";
}else if (draw == 1){
result = "恭喜您获得一等奖";
}else if(draw == 2){
result = "恭喜您获得二等奖";
}else if (draw == 3){
result = "恭喜您获得三等奖";
}else {
result = "谢谢你的参与";
}
if (draw > 0){
// 1:抽取成功以后同步到redis的list集合中 ---排名---时间周期--- 1天结束!
// 2: 存储站内信息给对应用户!
}
return R.ok().data("message" , result).data("draw" , draw);
}
return R.error().message("奖品已经抽完,请您下次早点来");
}catch (Exception e){
log.error("抽奖失败");
return R.error().message("服务忙!!!");
}
}
}
4、实现微信抢红包功能
使用redis的list、set、String数据类型来实现微信抢红包
- 发红包
1:先把红包金额根据个数拆分成小金额的红包。比如:100元的红包,发30个,就自动拆分个30不同金额的小红包。
2:这里的如何存储的多个小金额的红包呢? - 抢红包
1:高并发的抢红包时的核心技术,就是控制各个小红包的原子性(也就是一个红包不允许出现被多个人抢到)。
比如:30个红包在一个200人的群里抢,30个红包被抢走一个就要同时红包的库存就要减1。即剩下29个。
可以采用:list来处理抢红包?为什么不是set和hash呢?
1:set不允许有重复元素,list可以
2:list提供了pop操作,可以弹出一个元素的同时会自动从该集合列表中剔除。它是一个原子性操作。
实现原理图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jVsejnZE-1623841720848)(C:\Users\86183\AppData\Roaming\Typora\typora-user-images\1623657760650.png)]
业务代码
package com.kuangstudy.controller;
import com.kuangstudy.service.RedPackageListService;
import com.kuangstudy.vo.R;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
@RestController
@Log4j2
public class RedPackageListController {
@Autowired
private RedPackageListService redPackageListService;
@Autowired
private RedisTemplate redisTemplate;
/**
* 发红包!
*
* @param total 总金额
* @param count 数量
* @return
*/
@GetMapping("/set")
public R setredPackage(int total, int count) {
// 1 、 拆解红包
Integer[] packages = redPackageListService.splitRedPackage(total, count);
// 2、 为红包生成全局唯一id --- eg:微信群1 微信群2
long getincrementid = redPackageListService.getincrementid();
// 3、 采用list存储红包!
String redkey = "redpackage:" + getincrementid;
// 4、 把所有拆解的红包都放入到list集合中
this.redisTemplate.opsForList().leftPushAll(redkey, packages); //redpackage:1 2 3 4 5
// 5、 设置红包有效期为 24 小时!
this.redisTemplate.expire(redkey, 24, TimeUnit.HOURS);
return R.ok().message("红包拆解成功").data("packages", packages);
}
/**
* 抢红包
* @param redPackageid 群号id
* @param userid 用户id
* @return
*/
@GetMapping("/get")
public R getredPackage(long redPackageid, String userid) {
// 1、第一步是验证用户userid有没有抢过红包!
String userhaskey = "redpackage:consumer:" + redPackageid; //redpackage:consumer:1
// 判断用户是否已经抢过红包了!
Object o = this.redisTemplate.opsForHash().get(userhaskey, userid);
// 2、 如果用户没有抢过
if (o == null) {
// 3、那么就从红包集合中随机抽取一个出来
String redkey = "redpackage:" + redPackageid; // 3
// 使用集合 lpop key
Object money = this.redisTemplate.opsForList().leftPop(redkey);
if (money != null) {
// 4、用户抢到红包之后,就用把抢过的红包用hash存储起来,目的就是把已经抢过红包的用户记录下来!
this.redisTemplate.opsForHash().put(userhaskey, userid, money); //redpackage:consumer:1 2 3
log.info("用户 {},抢到的红包金额是: {}", userid, money);
return R.ok().message("用户: " + userid + ",抢到的红包金额为:" + money).data("redmoney", money);
}
R.error().message("红包已经抢完了....");
} else {
return R.error().message("你已经抢过红包了....");
}
return R.ok().message("红包程序运行完成");
}
}
总结:
-
先要产生红包,用了一个拆解红包的算法
-
红包拆解完成后,带群号的key,value为拆解的值 放入到list集合中保存,并设置24小时自动过期时间!
-
自此,红包发送成功!
-
抢红包的实现为 当参数携带 群号 和用户id后,进入抢红包方法,首先判断用户是否已经抢过红包了,如果抢过红包的话(用hash存储),获取hash key1(redpackage:consumer:群id) key2(用户id) 是否存在money,若存在说明已经抢过了!
-
如不存在,说明没有抢过,开始分配红包,从红包中随机弹出一个(lpop),然后保存在hash中,保存的key1为
redpackage:consumer:群id , key2为用户id , value值为money抢到的金额!
-
如果**(lpop)弹出的money**为空,说明红包已经被抢完了!
5、微博实战
用Redis中的Hash数据类型来实现微博实战
1:Redis中的数据结构hash,它是String数据结构的升级版。就类似于java中的Map是一样的
Map<String,Map<String,String>> hash = new HashMap<String,HashMap<String,String>>();
2:每个hash存储的大小,可以存储2的(32-1)次方的键值对(40多亿条)。
Redis在现在的互联网公司中,使用的范围越来越广,因为redis天生拥有高并发的特征,使用的Redis最好的公司也属新浪未必。Redis技术覆盖了微博的每个领域和应用场景,比如:抢红包、粉丝数、用户数、点赞数、转评数、评论、广告、黑名单以及排行榜等等。使用了Redis以后,微博能够快速支撑日活跃用户达到1~2亿。每日的访问量能够达到百元甚至千亿的访问。而且微博的redis集群规模可以存储数据100T.10000+redis个业务节点的集群。也正因为微博中使用了redis所以后续的课程中我们会用微博来讲解和剖析redis在微博中的一些场景。
1、微博注册
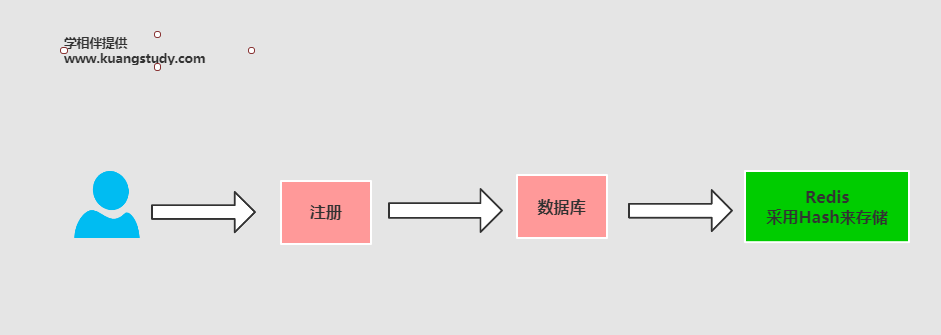
整个的流程是:
1:首先注册用户填写用户信息,先写入到db中
2:然后在存储数据到redis的hash结构中 key=”reg:user:id”
package com.kuangstudy.weibo.service;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.kuangstudy.weibo.config.Constants;
import com.kuangstudy.weibo.dao.UserMapper;
import com.kuangstudy.weibo.entity.User;
import com.kuangstudy.weibo.utils.ObjectUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* 关于用户service
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService{
@Autowired
private UserMapper userMapper;
@Autowired
private RedisTemplate redisTemplate;
/**
* 微博用户注册
* @param user
*/
@Override
public void regUser(User user) {
// 1. 把用户写入到db中
userMapper.insert(user);
// 2.把写入用户查询出来,写入到redis的hash数据结构中
User user2 = userMapper.selectById(user.getId());
try {
// 3.如何将用户对象存储在hash中
// 注意类似于 hmset key file value file value file value
Map<String, Object> usermap = ObjectUtils.objectToMap(user2);
String key = Constants.USER_REG_HASH + user2.getId();
this.redisTemplate.opsForHash().putAll(key,usermap);
//4、设置key的失效时间为一个月---- 为什么给过期时间 : 如果用户注册一直不用,就会占用内存空间
// 比如: 这个如果有100W用户注册了微博 , 其中30w用户注册但是没用,腾出内存空间就可以做其他的事情了!
// 过期了怎么办? 当用户再次登录的时候 再次放入hash 中保存!
redisTemplate.expire(key,30, TimeUnit.DAYS);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
总结 :微博的注册 使用 hash 来保存用户的注册信息! 当用户注册时,会先将用户信息存入db,在用hash去存储并设置一个月过期时间,当用户一个月不登陆时,从内存中移除!当用户一个月后再次登录的时候,再将用户信息查询出来,放入缓存之中!
2、微博发送
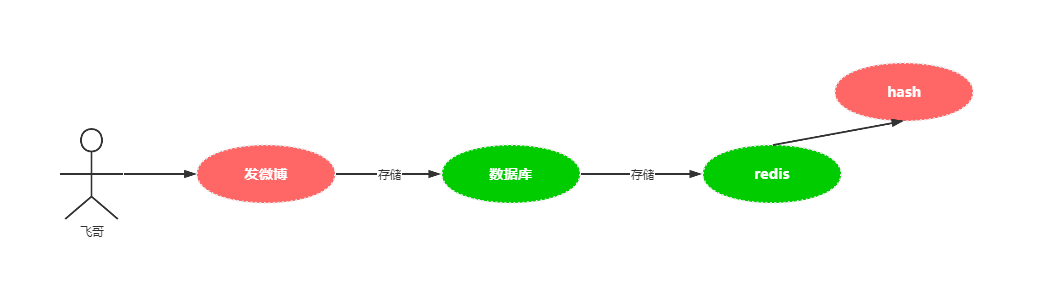
package com.kuangstudy.weibo.service;
import com.kuangstudy.weibo.config.Constants;
import com.kuangstudy.weibo.dao.ContentMapper;
import com.kuangstudy.weibo.entity.Content;
import com.kuangstudy.weibo.utils.JsonUtil;
import com.kuangstudy.weibo.utils.ObjectUtils;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import sun.dc.pr.PRError;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* 保存微博信息业务
*/
@Service
@Log4j2
public class ContentService {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private ContentMapper contentMapper;
public Content saveContent(Content content){
// 1、保存微博内容到db中
contentMapper.insert(content);
// 2、保存的内容写入到hash中
Map<String, Object> map = null;
try {
// 3、把发送的内容转化为map
map = ObjectUtils.objectToMap(content);
// 4、redis中hash的内容的key
String key = Constants.USER_COTENT_HASH + content.getId();
// 5、把微博的内容保存在hash中
this.redisTemplate.opsForHash().putAll(key, map);
// 6、设置微博的有效期是30天过期
this.redisTemplate.expire(key,30, TimeUnit.DAYS);
return content;
} catch (IllegalAccessException e) {
e.printStackTrace();
return null;
}
}
}
3、微博关注和粉丝(Set实现)
图解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W0K4OaVf-1623841720859)(C:\Users\86183\AppData\Roaming\Typora\typora-user-images\1623765223767.png)]
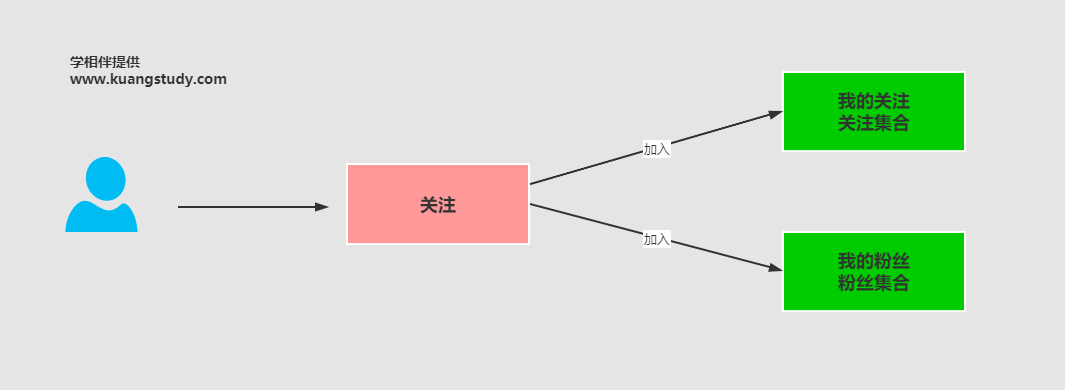
重点:首先会为每个用户创建两个set集合,一个关注集合一个粉丝集合。
比如飞哥关注狂神在后台的逻辑中会发生2个动作:
1、在飞哥的关注列表set中会有狂神的信息s
飞哥的关注set集合的key = guanzhu:飞哥userid
狂神的粉丝set集合的key = fans:狂神userid
package com.kuangstudy.weibo.controller.set;
import com.kuangstudy.weibo.config.Constants;
import com.kuangstudy.weibo.dao.UserMapper;
import com.kuangstudy.weibo.entity.User;
import com.kuangstudy.weibo.service.FollowService;
import com.kuangstudy.weibo.service.UserService;
import com.kuangstudy.weibo.vo.R;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
@RestController
public class FollowerController {
@Autowired
private FollowService followService;
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private UserMapper userMapper;
@Autowired
private UserService userService;
/**
* 用户关注
* @param userid 用户id
* @param followid 主播id
* @return
*/
@PostMapping("/follow")
public R follow(Integer userid ,Integer followid){
followService.follow(userid,followid);
return R.ok().message("用户关注成功,"+userid+"关注了"+ followid+"成功!");
}
/**
* 查看用户的关注信息
* @param userid 用户id
* @return
*/
@GetMapping("/guanzhulist")
public List<User> guanzhulist(String userid){
String key = Constants.USER_GUANZHU_SET + userid;
// 等价于 smember key
return getUserInfo(this.redisTemplate.opsForSet().members(key));
}
/**
* 查看用户的粉丝信息
* @param userid 用户id
* @return
*/
@GetMapping("/fanslist")
public List<User> fanslist(String userid){
String key = Constants.USER_FANS_SET + userid;
// 等价于 smember key
return getUserInfo(this.redisTemplate.opsForSet().members(key));
}
/**
* 获取具体的用户信息的数据
* @param userids 用户id
* @return
*/
public List<User> getUserInfo(Set<Integer> userids){
// 1、创建一个用户容器,用来把 对应粉丝 或者 关注列表 的 用户信息 从 hash 中查询出来,放入到userlist中
List<User> userList = new ArrayList<>();
// 需要获取的key定义 hmget user:reg:hash:2 id nickname password isdelete sex
List<String> hashkeys = new ArrayList<>();
// id nickname password isdelete sex
hashkeys.add("id"); // 0
hashkeys.add("nickname"); // 1
hashkeys.add("password"); // 2
hashkeys.add("isdelete"); // 3
hashkeys.add("sex"); // 4
// userid: 2 狂神 3 阿超
for (Integer userid : userids) {
// 用户hash注册的key
String key = Constants.USER_REG_HASH + userid;
// 相当于 hmset key file1 file2 file3
List multiGet = redisTemplate.opsForHash().multiGet(key, hashkeys);
// System.out.println(multiGet.get(0));
// System.out.println(multiGet.get(1));
// System.out.println(multiGet.get(2));
// System.out.println(multiGet.get(3));
// System.out.println(multiGet.get(4));
User user = null;
if (multiGet!=null && multiGet.size()>0){
user = new User();
user.setId(Long.parseLong(String.valueOf(multiGet.get(0))));
user.setNickname(String.valueOf(multiGet.get(1)));
user.setPassword(String.valueOf(multiGet.get(2)));
user.setIsdelete(Integer.parseInt(String.valueOf(multiGet.get(3))));
user.setSex(Integer.parseInt(String.valueOf(multiGet.get(4))));
}else {
// 如果30天之后,过期了,则查询db,再把数据库信息重新放到redis的hash中!
user = userMapper.selectById(userid);
// 查询出的用户 重新注册到缓存之中保存!
userService.regUser(user);
}
userList.add(user);
}
return userList;
}
/**
* 取消关注
* @param userid
* @param followid
* @return
*/
@PostMapping("/unfollow")
public R unfollow(Integer userid ,Integer followid){
followService.unfollow(userid,followid);
return R.ok().message("用户取消关注成功,"+userid+"取消关注了"+ followid+"成功!");
}
}
6、Redis实现抖音推荐引擎-布隆过滤器
利用布隆过滤器实现今日头条的去重过滤!
场景分析
今日头条,抖音的推荐,相信很多小伙伴在预览的时候,头条会根据的你喜好,为你推荐一些图文信息供你阅读,比如:你喜欢汽车、喜欢美女,它就会经常推荐一些美女图或者汽车文章供你阅读。
我们今天讲的内容不是推荐算发,而是:已读去重算法。
就是推荐引擎给你推荐文章的适合,要过滤你已经阅读过的,不然就会导致重复给你推荐。比如你阅读了一篇文章,如果你已经阅读了,如果没有已读去重,明天又给你推荐。你会烦死去,之间把APP卸载了。故为了达到更好的体验效果必须把你读过的内容下去重。
什么是已读去重算法呢?
说到这种已读去重的技术解决方案,一般的开发者会想到的就是数据库存储。这种方案对于一线互联网公司来说是有问题的。像今日头条这种高并发的场景,每次推荐都去数据库查询,必定导致数据库扛不住。所有肯定是redis缓存来处理的。
既然用到了redis,同学们想一想用什么数据结构?
大部分的像伙伴会想到set。set是一种很不错的去重数据结构,对于小量数据可以实现,但是对于大数据,例如:几个月的已读历史数据的存储,set就不太适合了。业界的做法一般是使用布隆过滤器来是实现。
什么是布隆过滤器
布隆过滤器是:全名(Bloom Filter)是1970年由布隆提出。
它实际上是一个很行的二进制向量和一系列随机映射的函数。布隆过滤器可以用于检索一个元素释放在一个集合中。
优点是:空间效率和查询时间都比一般的算发要好的多。
缺点是:有一定的误识别率和删除困难
布隆过滤器你可以理解为一个:不怎么精确的set结构,就是用于过滤数据释放重复的一种数据结构。
Redis官方提供的布隆过滤器到Redis4.0才提供了插件功能之后才正式登场。
布隆过滤器作为一个插件加载到Redis Server中,给Redis提供了强大的布隆去重功能。
布隆过滤器是有错误的,默认错误率为0.0.1
具体的实现
1、添加依赖
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.1.0</version>
</dependency>
2、配置文件yml
redis:
bloom:
host: ip
port: 端口
capacity: 100 # 100条数据
password: 密码
rate: 0.01 # 错误率
业务代码
package com.kuangstudy.weibo.controller.bloom;
import com.kuangstudy.weibo.config.KsdRedisBloomConfiguration;
import io.rebloom.client.Client;
import io.swagger.models.auth.In;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
@RestController
@Log4j2
public class BloomFilterController {
@Autowired
private Client rebloomClient;
// 每次用户刷新或者第一次访问的时候,直接最多给18条最新的视频或者文章给用户!
private int SIZE = 18;
// 场景: 抖音、今日头条上访问的1个月的数据量,我用bloomfilter把他进行存储!
// 模拟某个用户,访问了1W篇文章,已读数据!
/**
* 添加用户历史数据
* @param userid 用户id
*/
@GetMapping("/initusers")
public String init(Integer userid){
String[] topics = new String[10000];
for (int i = 0; i < 10000; i++) {
topics[i] = String.valueOf(i);
}
// 相当于 bf.madd redis:uid:filter:2 1 2 3 4 5 8 .....
this.rebloomClient.addMulti("redis:uid:filter:"+userid,topics);
return "success innit";
}
/**
* 模拟信息流的大数据信息服务数据
* 获取18条数据
*
* 拿者 18 条 数据 到 布隆过滤器 中 去过滤!!
*
* @return
*/
public List<Integer> getArticleIds(){
Random random = new Random();
// 大数据推荐的接口
// bigdataService.getData();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < SIZE; i++) {
int id = random.nextInt(100000);
list.add(id);
}
return list;
}
/**
* 拉取 18 条数据 去布隆过滤器(bloom) 中 取过滤!
* @param userid 用户id
* @return
*/
@GetMapping("/redloom")
public List<Integer> redloom(Integer userid){
// 1:过滤某个用户的数据
String key = "redis:uid:filter:" + userid;
// 2:定义容器去装配那些过滤以后的数据 (文章、视频)
List<Integer> list = new ArrayList<>();
while (true){
// 步骤1:到大数据中心拿取 18 条 数据
List<Integer> dataList = this.getArticleIds();
// 步骤2: 判断这 18 条数据 , 是否在布隆过滤器中 , 存在就进行过滤已读的数据
String[] arrays = new String[dataList.size()];
for (int i = 0; i < dataList.size(); i++) {
arrays[i] = String.valueOf(dataList.get(i));
}
// 批量过滤 existsMulti 相当于 bf.mexists key arrays
boolean[] booleans = this.rebloomClient.existsMulti(key, arrays);
for (int i = 0; i < dataList.size(); i++) {
boolean flag = booleans[i];
if (!flag){
// 存储未读的进行返回
list.add(dataList.get(i));
if (list.size()==SIZE){
break;
}
}else{
// 已经读过的进行过滤
log.info("过滤: {}" , dataList.get(i));
}
}
// 读到了18 条为止 就开始 结束 获取
if (list.size()==SIZE){
break;
}
}
// 把本次读取出来的数据再次放入布隆过滤器 , 代表已读!
String[] strings = new String[list.size()];
for (int i = 0; i < list.size(); i++) {
strings[i] = String.valueOf(list.get(i));
}
this.rebloomClient.addMulti(key,strings);
// list -- hash/db 找到完整的数据返回!
return list;
}
}