如需了解MySQL分区相关概念,使用场景以及限制等,点击这里
文章目录
本文示例表
创建表
CREATE TABLE `student_1` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(30) NOT NULL,
`SEX` char(2) NOT NULL,
`AGE` int(11) NOT NULL,
`CLASS` varchar(10) NOT NULL,
`GRADE` varchar(20) NOT NULL,
`HOBBY` varchar(100) DEFAULT NULL,
`CREATE_TIME` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`ID`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
插入两千万数据
DROP PROCEDURE IF EXISTS inst_data;
CREATE PROCEDURE inst_data() BEGIN
DECLARE incr INT DEFAULT 1;
WHILE incr <= 20000000 DO
INSERT INTO `study`.`student_1` (`NAME`, `SEX`, `AGE`, `CLASS`, `GRADE`, `HOBBY` ,`CREATE_TIME`)
VALUES
(
CONCAT( 'jsontom', incr),
CASE WHEN incr % 2 = 0 THEN '男' ELSE '女' END,
FLOOR(18 + ( RAND() * 7 )),
CONCAT(1 + FLOOR(RAND() * 10 ), '班' ),
CONCAT(1 + FLOOR(RAND() * 10 ), '年级' ),
CONCAT( '喜爱看第',1 + FLOOR(RAND() * 9 ),'个片儿'),
NOW()
);
SET incr = incr + 1;
END WHILE;
SELECT CONCAT('插入条数 ',incr);
END;
CALL inst_data ( );
range分区管理
当用某些字段作为分区字段时,则分区字段必须全部包含在主键或者某一个唯一索引中。
上表如果直接添加分区会报如下错
1503 - A PRIMARY KEY must include all columns in the table's partitioning function
本文示例表的分区字段为CREATE_TIME,该表除了主键id没有其他唯一索引。
第一种方式我们把id和CREATE_TIME字段作为联合主键。
第二种方式是新建一个唯一索引包含CREATE_TIME字段。
本文我们采用第一种方式,现实中根据实际情况进行选择。
分区的时间值请根据实际值修改。
创建表时进行分区
CREATE TABLE `student_1` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(30) NOT NULL,
`SEX` char(2) NOT NULL,
`AGE` int(11) NOT NULL,
`CLASS` varchar(10) NOT NULL,
`GRADE` varchar(20) NOT NULL,
`HOBBY` varchar(100) DEFAULT NULL,
`CREATE_TIME` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`ID`,`CREATE_TIME`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=20000001 DEFAULT CHARSET=utf8
PARTITION BY RANGE ( UNIX_TIMESTAMP(CREATE_TIME) )
(
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 10:04:42') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 12:44:02') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 15:23:22') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 18:02:42') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 20:42:03') ),
PARTITION pmax VALUES LESS THAN (UNIX_TIMESTAMP('2021-11-21 00:00:00'))
);
为现有数据的表进行分区
分区语句如下
ALTER TABLE student_1
PARTITION BY RANGE ( UNIX_TIMESTAMP(CREATE_TIME) )
(
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 10:04:42') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 12:44:02') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 15:23:22') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 18:02:42') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 20:42:03') ),
PARTITION pmax VALUES LESS THAN (UNIX_TIMESTAMP('2021-11-21 00:00:00'))
);
新增分区
ALTER TABLE student_1
ADD PARTITION (PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-26 20:42:03') ));
重组分区
注意:合并/拆分分区后,产生的新分区,查询新分区数据量为零,但是数据是真实存在的。
合并分区
把p1和p2分区合并成p1_p2分区
ALTER TABLE student_1
REORGANIZE PARTITION p1,p2 INTO
(
PARTITION p1_p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 12:44:02') )
);
拆分分区
把p1_p2分区拆分成p1和p2分区
ALTER TABLE student_1
REORGANIZE PARTITION p1_p2 INTO
(
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 10:04:42') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 12:44:02') )
);
查看分区的数据量
SELECT
PARTITION_NAME,
TABLE_ROWS
FROM
INFORMATION_SCHEMA.PARTITIONS
WHERE
TABLE_NAME = 'student_1';
删除分区
注意:当删除一个分区,该分区中所有的数据同时也被删除了。
ALTER TABLE student_1 DROP PARTITION p1;
取消分区
该种方式数据得以保留,恢复成普通表
alter table student_1 remove partitioning;
效率对比
对于如下SQL
select * from student_1 where CREATE_TIME = STR_TO_DATE('2021-11-19 18:02:42','%Y-%m-%d %H:%i:%s')
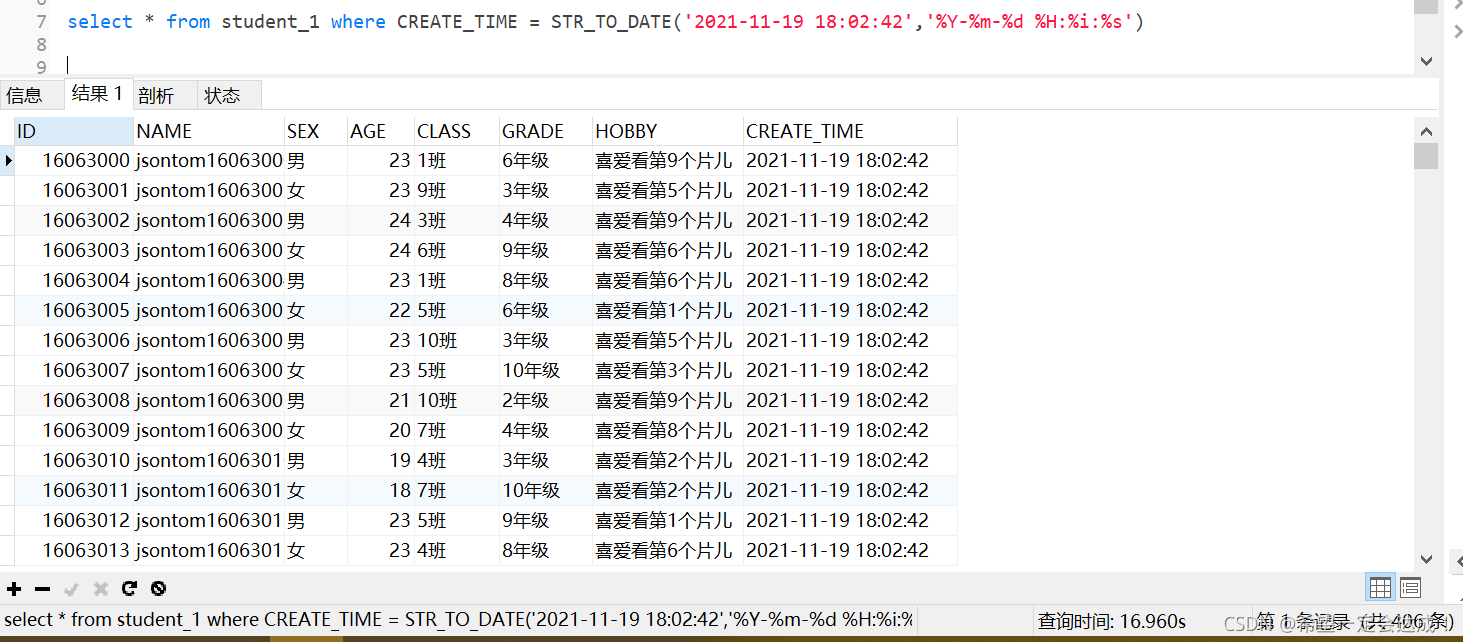
不使用索引和分区的查询
全表扫描查询用时16.960s
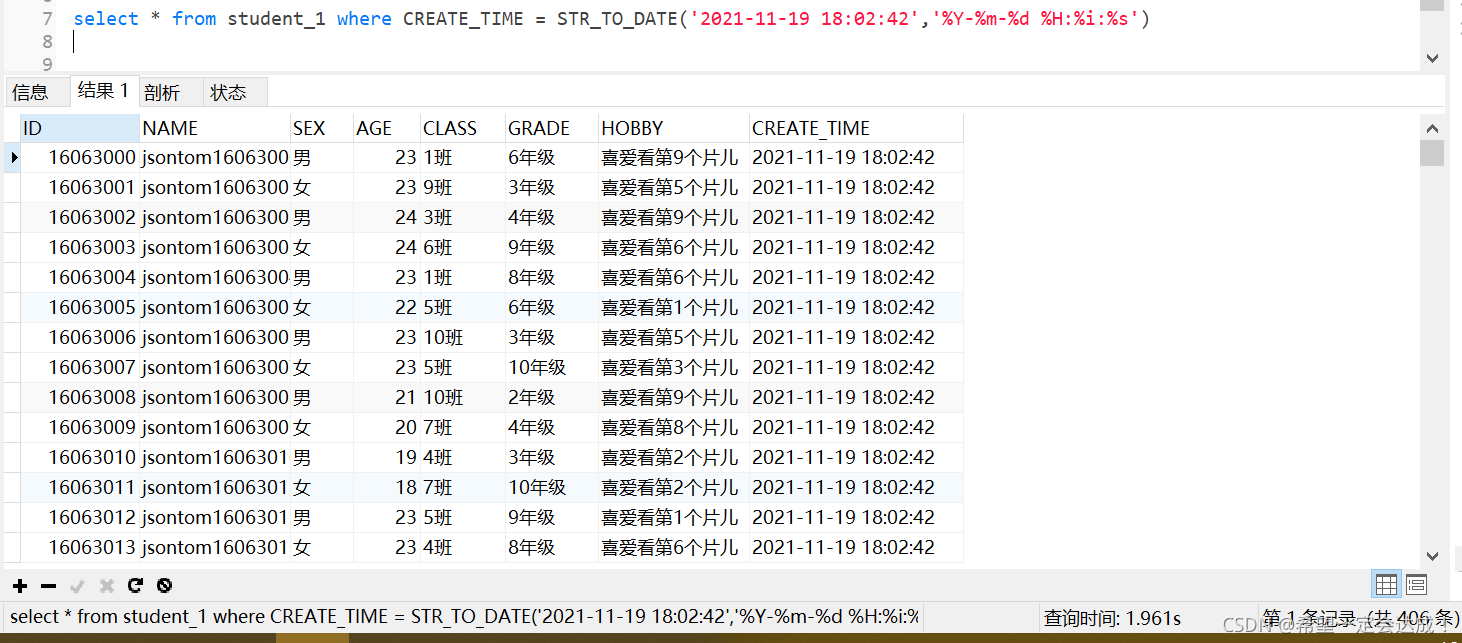
使用索引的查询
添加索引
alter table student_1 add index crtm(CREATE_TIME);
查询用时1.961s
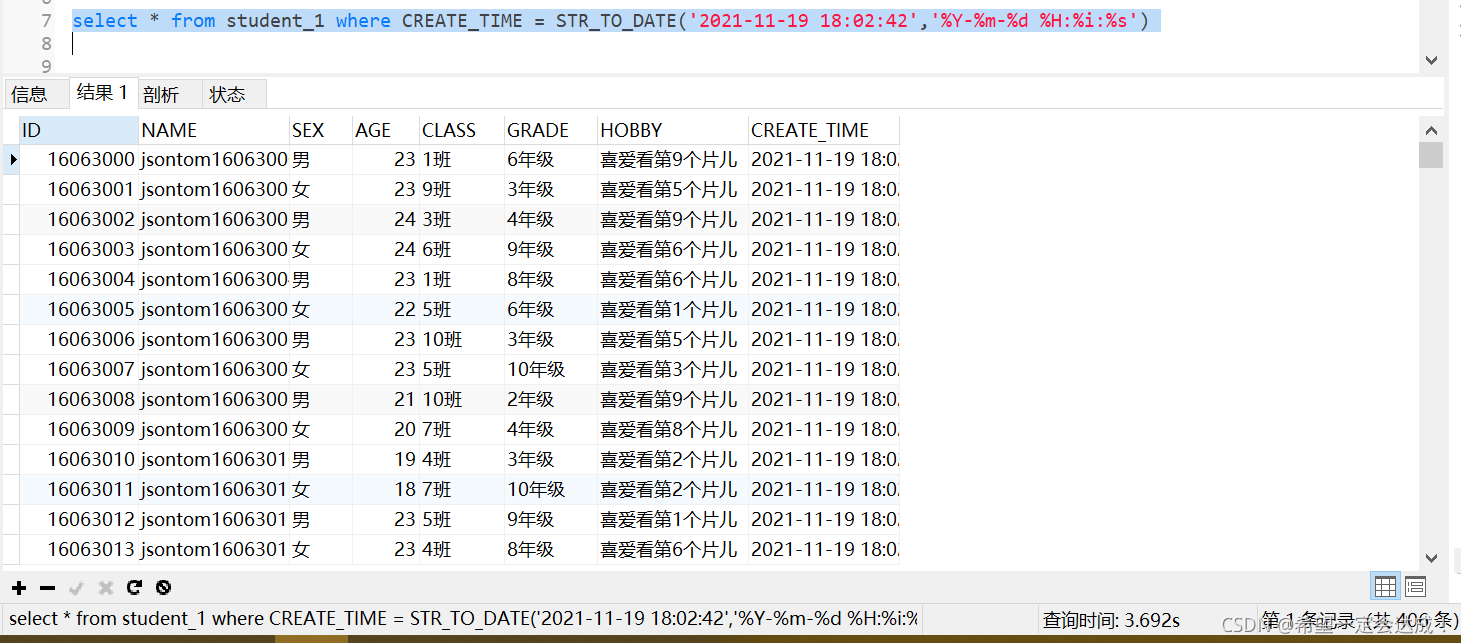
使用分区查询
添加分区
ALTER TABLE student_1
PARTITION BY RANGE ( UNIX_TIMESTAMP(CREATE_TIME) )
(
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 10:04:42') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 12:44:02') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 15:23:22') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 18:02:42') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-11-19 20:42:03') ),
PARTITION pmax VALUES LESS THAN (UNIX_TIMESTAMP('2021-11-21 00:00:00'))
);
查询耗时3.692s
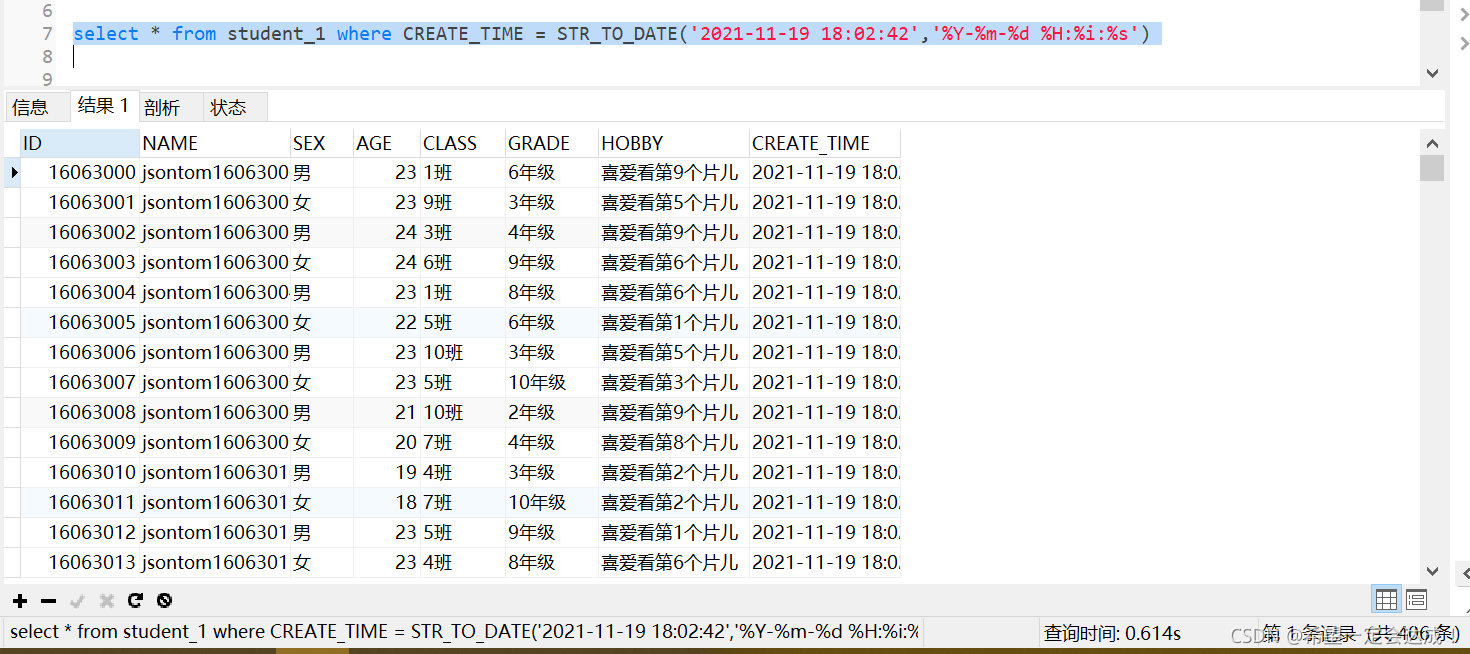
使用分区+索引查询
对表进行分区,并对CREATE_TIME字段添加索引,查询耗时0.614s
总结
效率由高到低为
使用分区+索引 > 使用索引 > 使用分区 > 不使用索引和分区
所以在使用索引效果不佳或者是索引维护代价高昂时,我们可以考虑引入分区的方式提升效率。
注意
访问分区表时,很重要的一点是在WHERE条件中带上分区列(不能是包含列的表达式),有时候看似多余的也要带上,这样可以让优化器能够过滤掉无须访问的分区。如果没有这样的条件,会访问所有的分区,代价高昂。
EXPLAIN PARTITIONS可以查看SQL语句是否执行了分区过滤