假设我们有两张表A和表B,表A有100条数据,表B有10000条数据,现在进行两表的内连接关联查询,MySQL优化器会默认选择数据量小的表A作为驱动表。
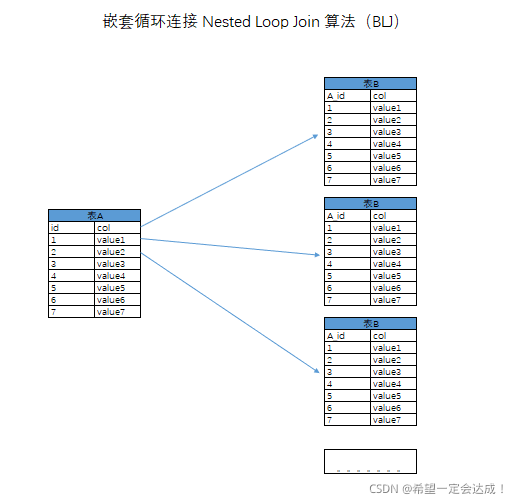
简单嵌套循环连接 Nested Loop Join 算法(BLJ)
如下图所示,该算法下,以A表作为驱动表,每扫描一条A表的记录,需要全量扫描B表进行匹配,扫描行数为
100(表A)+ 100 * 10000(100次表B)= 1000100 条
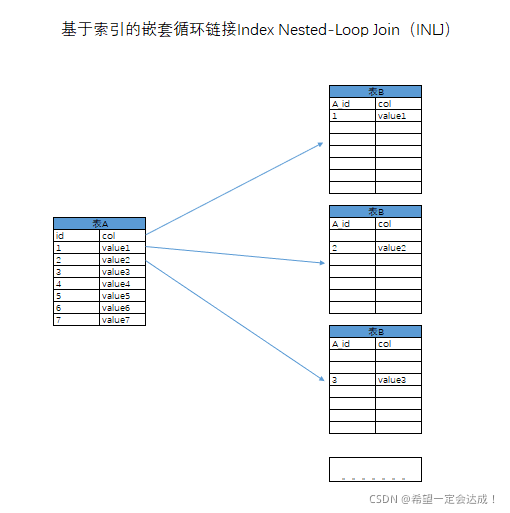
基于索引的嵌套循环链接Index Nested-Loop Join(INLJ)
如下图所示,该算法下,以A表作为驱动表,每扫描一条A表的记录,在一对一关联的情况下,只需要扫描B表的一条记录,扫描行数为
100(表A)+ 10000(表B)= 10100 条
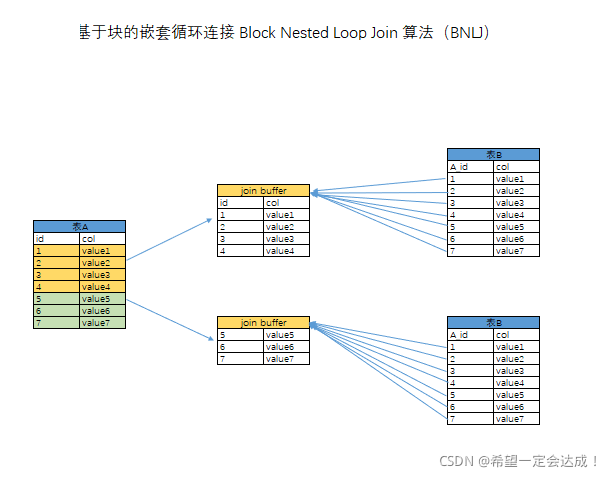
基于块的嵌套循环连接 Block Nested Loop Join 算法(BNLJ)
如下图所示,该算法下,引入了join buffer 缓存,假设join buffer的大小能够容纳50条数据,A和B表的每条记录的数据大小相同。
以A表作为驱动表,每次读取50条进入缓存,读取B表的全量数据进入内存,把B表的每条记录和join buffer的50条记录进行一一匹配。完成后重复上述步骤,扫描总行数计算如下
100 (表A扫描数) + 100 / 50 (join buffer个数) * 10000(扫描B表记录数) = 20100条
思考,为何选择缓存数据量小的驱动表A,不缓存被驱动表B?
我们不妨假设缓存表B算算数据量,计算如下:
10000 (表B扫描数) + 10000 / 50(join buffer个数) * 100(A表记录数) =30000条
由此得出缓存数据量小的表代价更低,效率更高。
总结
效率由高到低依次是
扫描二维码关注公众号,回复:
13305922 查看本文章

基于索引的嵌套循环链接 > 基于块的嵌套循环连接 > 简单嵌套循环连接
所以连表查询数据量大的情况下,建议在被驱动表的关联字段上建立合适的索引。