这是我参与11月更文挑战的第23天,活动详情查看:2021最后一次更文挑战
连续Prompts
构造Prompt的初衷是能够找到一个合适的方法,让Pre-trained Language Model(PLM)更好地输出我们想要的结果,但其实并不一定要将Prompt的形式设计成人类可以理解的自然语言,只要机器理解就行了。因此,还有一些方法探索连续型Prompts——直接作用到模型的Embedding空间。连续型Prompts去掉了两个约束条件:
- 模版中词语的Embedding可以是整个自然语言的Embedding,不再只是有限的一些Embedding
- 模版的参数不再直接取PLM的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整
Prefix Tuning最开始由Li等人提出,这是一种在输入句子前添加一组连续型向量的方法,该方法保持PLM的参数不动,仅训练前缀(Prefix)向量。Prefix Tuning的提出主要是为了做生成任务,因此它根据不同的模型结构定义了不同的Prompt拼接方式,在GPT类的Auto-Regressive(自回归)模型上采用的是
[Prefix;x;y]的方式,在T5类的Encoder-Decoder模型上采用的是
[Prefix;x;Prefix′;y]的方式

输入部分
Prefix,x,y的Position id分别记作
Pidx,Xidx,Yidx。Prefix Tuning初始化一个可训练的矩阵,记作
Pθ∈R∣Pidx∣×dim(hi),其中
hi={Pθ[i,:],LMϕ(zi,h<i),if i∈Pidxotherwise
上述公式的含义是,索引
i如果属于前缀的部分,则从
Pθ中抽取向量;
i如果不是前缀部分,则由参数固定的预训练模型生成对应的向量。训练目标为:
ϕmax logpϕ(y∣x)=i∈Yidx∑logpϕ(zi∣h<i)
Pθ本质上是一个矩阵,而生成一个矩阵的方法又很多,可以用nn.Embedding(),或者nn.Linear()
同样是在连续空间上搜索Prompt,OptiPrompt构建的「模板」并不局限于前缀,也可以在句子的中间

首先根据AutoPrompt定义一个Prompt模板:
[x] [v]1 [v]2 ... [v]m [MASK]
其中
[v]i为一个连续型向量(与BERT的输入维度一致)。OptiPrompt还考虑以人工构建的离散Prompt作为起点,在连续空间上进行搜索以构建较优的Prompt。例如
[x] is [MASK] citizen可以转换为
[x] [v]1 [MASK] [v]2
将is和citizen对应的input Embedding作为
[v]1和
[v]2的初始化
Hard-Soft Prompt Hybrid Tuning方法可以说是人工设计和自动学习的结合,它通常不单纯使用可学习的Prompt模板,而是在人工设计的模板中插入一些可学习的Embedding。实际上有了上面的基础我们都知道,连续的Prompt要比离散的Prompt好一点,但是在此基础上还有什么改进的余地吗?Liu等人提出的**P-Tuning**解决了Prompt token之间的关联性问题
之前连续的Prompt生成方式无非都是训练一个矩阵,然后通过索引出矩阵的某几行向量拼起来。坦白地说,我们希望这些prompt token Embedding之间有一个比较好的关联性,而不是独立地学习,为了解决这个问题,P-Tuning引入了一个Prompt Encoder(如下图b所示)
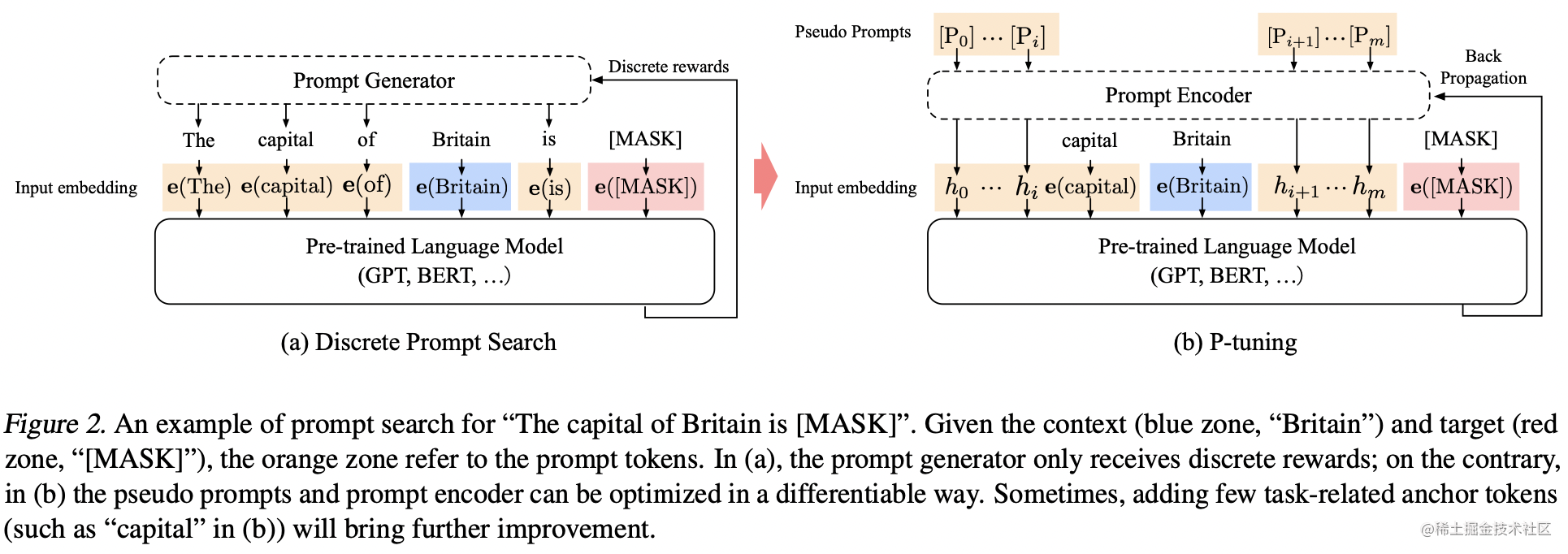
上图a是传统的离散型Prompt,我们把生成离散Prompt token的东西叫做Prompt Generator;上图b首先传入一些Virtual(Pseudo)token,例如BERT词表中的[unused1],[unused2],...当然,这里的token数目是一个超参数,插入的位置也可以调整。将这些Pseudo token通过一个Prompt Encoder得到连续的向量
h0,...,hm,其中
\begin{align} h_i &= \text{MLP}([\overrightarrow{\mathop{h_i}};\overleftarrow{\mathop{h_i}}])\\ &= \text{MLP}([\text{LSTM}(h_{0:i}):\text{LSTM}(h_{i:m})]) \end{align}
即,Prompt Encoder是由BiLSTM+MLP组成的一个简单网络。作者还发现加入一些anchor token(领域或者任务相关的token)可以有助于Template的优化。例如文本蕴含任务,输入是前提和假设,判断是否蕴含。一个连续的模版是
[PRE][continuous tokens][HYP][continuous tokens][MASK]
在其中加入一个anchor token:[?]效果会更好,此时模板变成
[PRE][continuous tokens][HYP]?[continuous tokens][MASK]
大家可能想问,如何优化P-tuning?实际上根据标注数据量的多少,分两种情况讨论
- 标注数据比较少。这种情况,我们固定PLM的参数,只优化
[P0]∼[Pm]这几个token的Embedding。换句话说,我们只是要更新Prompt Encoder的参数
- 标注数据很充足。这种情况直接放开所有参数微调