0.前言
这是一篇CVPR2021年的无监督深度学习超分辨率的文章,论文原文下载链接在这里。作者还在Github上传了项目源码。
面对的问题(本文要解决的问题):
1.许多现有的SR方法都是在假定退化方式是双三次下采样而进行的,当面临真实场景下的数据时往往会由于实际退化方式不同而导致许多SR方法出现问题。
2.有许多方法通过退化估计来解决问题1,但是这又面临着新的问题,那就是许多退化估计的方法十分耗时,并且在退化估计不准的情况下直接会导致超分辨的失败。
为了解决上述的两个问题,本文提出了一个种基于无监督退化表示学习的盲超分辨方法,该方法学习简单的退化表示来区分处于整个表示空间中的不同退化表示而不是在像素级的空间进行估计。本文还提出了一个退化感知超分辨率网络(DASR) ,这个网络可以基于学习到的退化表示来完成对图像的超分辨率任务。
1.介绍
本文提出了一种无监督退化表示学习方法,在这个方法中,作者假定同一个图像中任意部分的退化方式是相同的,不同图像的退化方式是不同的,也就是说一个图像中的某个图像块应该是和在这个图像中的其它图像块相似(退化表征相似),而和其它图像中的某个图像块不相似(退化表征不相似),如下图所示:

这个图中,两个橙色的退化表征块是从同一个图像中的两个块中提取表示的,两个紫色的退化表征快从另一幅图像中的两个块中提取表示的,用x和x+来表示不同的橙色块,x-表示两个紫色退化表示特征快,这里采用对比学习,对比学习的目的就是让x更加接近于x+(因为x和x+本来就属于同一个图像,也就是同一种特征表示),让x更加远离x-,这样的对比学习就实现了无监督的训练,而不需要再为某个退化方式标注标签。
本文提出的DASR网络就是利用这个特征表示向量去预测卷积核和通道级的调制系数(这两个东西也对应着后面作者结构中用到的退化感知卷积的两个操作,实际上就是利用退化表示来得到个卷积核和注意力权值,这个到后面的结构再具体讲)。
2. 相关工作
2.1 单图像超分辨率
单图像超分辨率的有关研究包括基于单一退化和多种退化模式的研究。单一退化的单图像超分辨率从SRCNN开始出现了一系列基于深度学习的方法;基于单一退化的在实际运用时会因为退化与固定的双三次退化相差甚远而产生比较差的效果,为了解决这个问题,许多工作开始研究非盲的SR问题,从SRMD开始出现了一系列把退化作为输入来完成SR任务,当然还有一些零样本的方法。
上述的将退化作为输入的方法会存在一定的问题也就是前面前言部分提到的问题2.
2.2 对比学习
这里文章介绍了无监督学习中常用到的一种方法——对比学习。在这里,我简单地阐述一下我对对比学习的理解,可能并不深刻和准确,但是应该比较容易理解。
在有监督学习中,我们往往需要groundtruth(标签)去对整个网络的学习过程进行监督,让网络朝着groundtruth的方向去优化。具体到分类问题,比如我们现在想要分出猫和狗,我们需要人工的把每张图贴上标签,告诉网络哪张是猫,哪张是狗。而在基于对比学习的无监督学习中,不需要标签,只需要正样本和负样本,网络最终输出的(或者说学习到的)是一种表征(说白了就是一个向量),这个表征向量代表着图像的某种属性(我们希望网络要学习的某种属性),比如本文中的这个网络,这个表征向量代表的就是退化方式,我们需要先假定不同图像的退化方式不同,而相同图像的退化方式相同,那我们就构建出了正样本和负样本,正样本就是与这次输入的图像块同属同一张图像的某个图像块,而负样本就是属于不同图像的图像块,这也可以通过一种类似于交叉熵的函数来进行监督,通过每次与正样本和负样本的对比,网络最终就会学到图像的退化表示。注意,网络最后学到的是退化表示,即给一张图就会给出一个退化表示,不同的图(不同退化方式得到的图)会给出不同的退化表示,这个过程是网络自己学习的,并不是人为的分了多少类退化方式让网络学习,这样学习到的退化表示可以有很多种。
3. 方法理论
3.1 问题表达
图像的退化模型可以建模为下面这个公式:
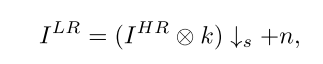
I LR 和I HR分别代表退化得到的低分辨率图像和原高分辨率图像,k表示一个滤波卷积核,下箭头表示下采样操作,s表示下采样的级别,n表示额外的高斯噪声。本文的所有实验其实是基于这个模型所进行的,也就是说,我们图像的退化过程并不是一无所知,而是建立了一个数学模型去研究的,所以我感觉这种基于上面公式的工作,可能还算不上完全意义上的盲超分辨。
3.2 本文的方法
本文方法由两部分组成:退化编码和退化感知超分辨率网络组成,结构如下图所示:

3.2.1 退化表征学习
退化表征学习其实就是通过基于对比学习的一个网络来实现的。对比学习需要正样本和负样本,所以我们要先假设在同样的图像中退化方式是相同的,在不同的图像中退化方式是不同的。
退化表征的网络结构如下:

整个的训练过程的简要表述如下:
在输入到一个图像块时,与其在相同图像中的图像块可以作为它的正样本,不在相同图像中的图像块作为负样本,这个图像块和它的正样本和负样本通过几层卷积核MLP最终得到了退化表征x, x+, x-.训练的过程就是为了让x更加接近x+,更加远离x-.
为了实现上述的训练过程,我们需要使用下面这样的损失函数:
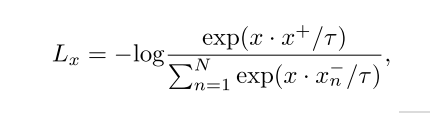
这个损失被称为infoNCE损失,是在论文《Momentum contrast for unsupervised vi-sual representation learning》中被提出的,它可以用来衡量样本的相似度。其实这个函数就和传统的对比学习的loss差不多,只不过多了个 τ \tau τ这个超参数,其中·代表向量点积,向量的点积可以表示两个向量的相似度,N是负样本的总数。优化这个函数让它变小,就可以让分数的部分变大,也就是让分子和分母的差距变大,也就实现了让x更加接近x+,更加远离x-.
现有的对比学习的方法中强调有一个蕴含丰富(具有多样性的)负样本是对表征学习直观重要的吗,所以本文需要构建一个有丰富变化信息的队列来作为负样本。具体做法是,在训练期间,随机挑选B张低分辨率的图像(也就是有B种不同退化方式的图像,因为前面我们已经假设不同的图像的退化方式不同)然后随机的从每一张图中裁剪出两个图像块,然后这总共2B个图像块被编码成2B个图像表征,如下:
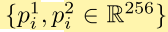
下标i代表第i张图像(共B张),上标代表的是裁剪的第1或者第2个图像块,那么实际整个的退化损失就是下面的这个函数: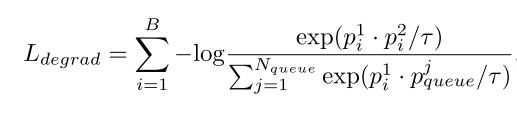
Nqueue表示在当前这个队列样本中负样本的数量,这个公式和前面的式子没有本质上的区别,只是符号表示根据本文的实际情况进行了更换。
3.2.2 退化感知超分辨率网络
退化感知超分辨率的网络结构如下:

这个结构图基本上比较清晰,唯一需要仔细讲的就是这个DA卷积的结构,DA卷积的结构如下:

这个结构其实也比较清晰,只有两个地方有点迷,就是我画圈圈的位置:
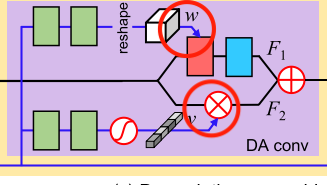
上面这个卷积核是如何形成的并且怎么用在深度卷积上的呢?底下这个经过全连接层和Sigmoid生成的一维向量是如何与原图像的矩阵进行点乘的呢?这个时候看下源代码会更加清晰(以下源代码来自于作者发布的Github项目):
class DA_conv(nn.Module):
def __init__(self, channels_in, channels_out, kernel_size, reduction):
super(DA_conv, self).__init__()
self.channels_out = channels_out
self.channels_in = channels_in
self.kernel_size = kernel_size
self.kernel = nn.Sequential(
nn.Linear(64, 64, bias=False),
nn.LeakyReLU(0.1, True),
nn.Linear(64, 64 * self.kernel_size * self.kernel_size, bias=False)
)
self.conv = common.default_conv(channels_in, channels_out, 1)
self.ca = CA_layer(channels_in, channels_out, reduction)
self.relu = nn.LeakyReLU(0.1, True)
def forward(self, x):
'''
:param x[0]: feature map: B * C * H * W
:param x[1]: degradation representation: B * C
'''
b, c, h, w = x[0].size()
# branch 1
kernel = self.kernel(x[1]).view(-1, 1, self.kernel_size, self.kernel_size)
out = self.relu(F.conv2d(x[0].view(1, -1, h, w), kernel, groups=b*c, padding=(self.kernel_size-1)//2))
out = self.conv(out.view(b, -1, h, w))
# branch 2
out = out + self.ca(x)
return out
class CA_layer(nn.Module):
def __init__(self, channels_in, channels_out, reduction):
super(CA_layer, self).__init__()
self.conv_du = nn.Sequential(
nn.Conv2d(channels_in, channels_in//reduction, 1, 1, 0, bias=False),
nn.LeakyReLU(0.1, True),
nn.Conv2d(channels_in // reduction, channels_out, 1, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
'''
:param x[0]: feature map: B * C * H * W
:param x[1]: degradation representation: B * C
'''
att = self.conv_du(x[1][:, :, None, None])
return x[0] * att
从这个代码里看就很清晰了,self.kennel完成的就是从退化表征向量生成卷积核的任务,生成的卷积核还是个一维的,又通过.view给reshape成了一个二维的卷积核,然后通过F.conv2d这个函数来利用刚刚生成的卷积核,通过选择groups来完成深度卷积。底下这里是通过self.ca来生成一个向量的,但是代码中并没有用全连接,CA_layer直接使用1x1的卷积操作来替代全连接层,直接生成一个二维的权值,所以就可以直接与原图像进行相乘。至此,两个结构的疑问就在代码中被解决了。
现在已有的方法通常是把图像的特征喂到CNN中去学习退化表示并且进行超分辨率,但是由于退化表示和图像特征之间的联系不是很大,直接这样学习的效果并不好。所以本文不同于现存的方法,而是基于特征表示通过预测卷积核(DA conv上面的分支)和调制系数(DA conv下面的分支,类似注意力的结构)来完成超分辨任务,所以效果比较好。
4.实验
4.1 数据集和实现细节
本文是根据3.1节中的退化表达式生成LR图像用来训练和测试。训练集来自DIV2K的800张图像和Flickr2K2650张图像,验证集来自benchmark数据集。高斯核的尺寸固定在21x21.
本文首先基于无噪声的各向同性的高斯核的退化方式训练网络,高斯核中对于x2,x3和x4缩放级别的 σ \sigma σ的取值范围被设置在[0.2,2.0], [0.2,3.0] 和 [0.2,4.0]。接着又在许多基于有噪声的各向不同性的高斯核的退化方式上训练网络。这句话基本是按照原文翻译过来的,所以读起来很拗口,简单理解就是本文采用了两种退化方式来获得训练集训练网络,一种是用一个各向同性的高斯核来对图像进行退化,并且不加噪声获得退化的图像,另一种则是用一个各向不同性的高斯核对图像进行退化并且还要增加噪声。对于不同缩放级别的退化样本,高斯核的 σ \sigma σ也有不同,这也就能形成多种退化方式,以模拟实际场景下的退化。更进一步的细节是,对于各向不同性的高斯核还有一些细节,但是目前还看不太懂这块内容,先把这块内容的原文放在这里:

训练的过程中,随机选择32张高分辨率的图像,然后随机地对他们进行旋转和翻转从而进行数据扩充。然后随机选前述的那样构建的32个高斯核生成低分辨率图像,并添加一些高斯噪声。然后就是从中随机的提取48x48的图像块,每幅图像提取两张,共64张图像块送入训练。
本文中,将3.2.1小节中的损失函数中的 τ \tau τ设置为0.07,负样本数量Nqueue设置为8192(这个负样本数量可能是经过数据扩充之后的值)
整个的训练过程如下:
1.单独训练退化表征网络,损失函数为Ldegrad(3.2.1小节中提到的),训练100个epoch,初始学习率为0.001,在60个epoch后学习率变为0.0001.
2.训练整个网络(退化表征网络+退化感知超分辨率网络),损失函数为Ldegrad和LSR,LSR就是超分辨率图像和高分辨率图像的L1范数(其实这里面感觉又有一种有监督的感觉),训练125个epoch,初始学习率设置为0.0001,在125个epoch之后减小为0.00005.
4.2 基于无噪声和各向同性的高斯核的实验
基于无噪声和各向同性的高斯核的退化方式来做的实验在本文是作为消融实验的,因为这样就可以把本文的DASR和RCAN,SRMD,MZSR,IKC和RCAN作比较,因为这些现在有的最好的SR网络都使用了各向同性的高斯核作为退化方式(不加噪声)。所以这部分所介绍的本文做的实验的退化方式都是基于各向同性的高斯核和无噪声的。
退化表征学习
为了证明退化表征学习的有效性,本文引入了一个本文网络的变体(Model1),这个Model1去掉了本文整体结构的表征学习部分(只是去掉了对比学习的过程,结构并没有去掉),在训练时也就不需要Ldegrad,就直接训练超分辨率网络500个epoch。把本文的完整结构记作Model4,那么首先就是要对比Model1和Model4.本文使用B100数据集通过不同的退化方式得到低分辨率图像输入Model1和Model4得到退化表示,使用T-SNE方法可视化数据,如下图:

T-SNE就是一种数据可视化的方法,从这个可视化的图中可以看出Model1的结果更加混乱一点,也就是退化表征的边界不是很清晰,所以经过对比,证明本文的表征学习是有效的。
退化感知卷积DACONV
这里的消融实验是为了证明本文提出的退化感知卷积结构的有效性。作者又用vanilla卷积代替DA卷积构建了Model2,去掉通道级模块分支构建了Model3(去掉了DA卷积的上半部分),比较结果如下:

显然,还是结构完整的效果更好一点。
盲超分辨VS非盲超分辨
为了看DASR网络的性能还能否提高,作者还试着都让DASR进行非盲超分辨。做法就是将退化编码网络用5个全连接层代替,然后直接用退化表示的groundtruth对网络进行训练,这类似个分类的过程,就是不采用对比学习的过程,用groundtruth对网络进行监督,这样的模型记作Model5,作者训练了500个epoches,这个模型达到了一个最好的效果,从上一张表能看出PSNR是最高的。综上,Model4达到了盲分辨率的最高性能,Model5达到了非盲超分辨的最高性能。
退化表示研究
这一部分做的消融实验室为了证明本文的退化表示对不同图像内容的有效性(不同的图像内容有相同的退化方式时能不能有相同的性能,保持较高的鲁棒性)。结果如下图:

横轴表示在set14数据集中随机选的10张图,纵轴表示经过某种退化方式恢复的超分辨图像的PSNR,这个图里相同的退化方式在不同内容的图像上用本文方法进行超分辨时的性能很稳定,这说明本文的退化表征对于不同的图像内容也是很稳定的。
和之前网络的比较


4.3 基于有噪声和各向不同性的高斯核的实验
退化表示研究
本文作者又做了一些实验,使用不同的高斯核和增加不同的噪音,同样经过T-SNE数据可视化方法,得到下面的结果:
这个图表示本方法在各向不同性的不同高斯核上和不同噪音上的不同退化方式,能够很好地表示他们的不同性。
和之前网络的比较

4.4 在真实场景下退化的实验
