写在前面
本文内容基本来源于官网,然后我结合我自己实际工作中的一些场景 把我认为 重要 且常用 的一些操作给记录下来了。目前presto是拆分为了两个项目 prestodb 和 prestosql,有兴趣的小伙伴可以看一下,这里选用的是prestodb。
如果有任何不对的地方,欢迎小伙伴指正!笔芯~~
咱们开始把 !
#01 概述
不是数据库!()
Presto是一种分布式高效 大量数据的即席查询工具,简单来说就是对于 TB 或 PB 级数据,能够比较快的得到查询结果。
数据可以是传统关系型数据库,也可以是Hive表数据。
也可以在Join多个 不同的库的数据。
是Facebook开源和社区共同维护发展的。
目前在公司的场景中,对于一些临时的数据需求,可以很快方便的得到查询结果,
这里是区别于Kylin这个框架,Kylin是提前把所有维度的情况的结果 提前计算好,需要使用的时候,直接查询的是结果 所以会比较快。
#02 核心概念
There are two types of Presto servers: coordinators and workers
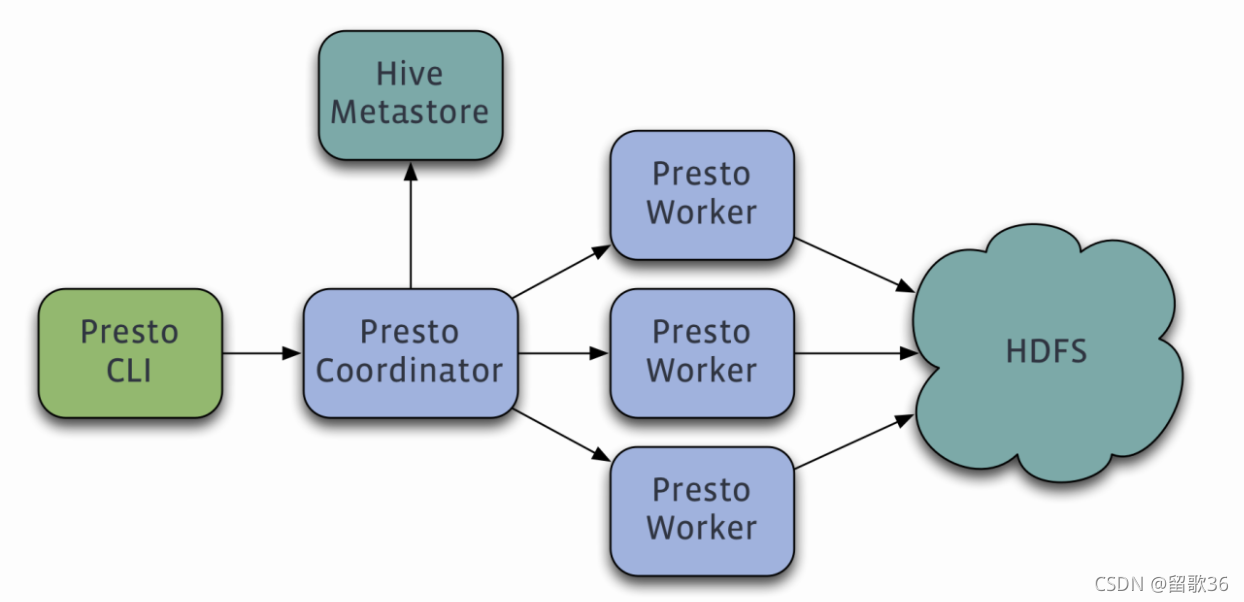
1.Coordinators# :协调器 主节点
Coordinators communicate with workers and clients using a REST API.
用途:
0.接收客户端提交过来的语句
1.parsing statements(解析语句)
2.planning queries (生成查询计划)
3.managing Presto worker nodes(管理从节点)
具体:
1.creates a logical model(query involving a series of stages )
创建一个逻辑模型(涉及一系列的 stages )
2.translated into a series of connected tasks running on a cluster of Presto workers
转化为一系列的 tasks 运行在 worker 节点上
3.fetching results from the workers and returning the final results to the client
2.Worker# :工作节点 从节点
Workers communicate with other workers and Presto coordinators using a REST API.
用途:
executing tasks and processing data.
starts up,启动从节点之后,它会自爆自己使得主节点发现它 ,这样主节点才能管理到该从节点
具体:
- fetch data from connectors and exchange intermediate(中间) data with each other
3.Data Sources
整个Presto的数据源模型有以下概念:
connector, catalog, schema, and table.
4.Connector
1.You can think of a connector the same way you think of a driver for a database
(简单可以类比为比如MySQL数据库的驱动程序)
2.Presto contains several built-in connectors
(内置连接器)
3.Many third-party developers have contributed connectors so that Presto can access data in a variety of data sources.
(第三方开发的connectors )
4.Every catalog is associated with a specific connector.
catalog configuration file(contains property connector.name )
你会发现每个catalog的配置文件都会包含 connector.name 这个属性
---------------pro.college_pro.test_table-------------
5.Catalog
catalog contains schemas and references a data source via a connector
包含 schemas 并且通过 连接器反射 得到数据库的数据
Schema/Table
When a statement is executed, Presto creates a query along with a query plan that is then distributed across a series of Presto workers.
#03 Data Types
1.Boolean
values true and false.
2.Integer
TINYINT ==> minimum value of -2^7 and a maximum value of 2^7 - 1
SMALLINT ==> minimum value of -2^15 and a maximum value of 2^15 - 1
INTEGER/INT ==> minimum value of -2^31 and a maximum value of 2^31 - 1
BIGINT ==> minimum value of -2^63 and a maximum value of 2^63 - 1
3.Floating-Point 浮点型
REAL 不常用
DOUBLE
4.Fixed-Precision 固定精度
DECIMAL -> A fixed precision decimal number. Precision up to 38 digits is supported but performance is best up to 18 digits.
DECIMAL(10,3), DECIMAL(20) 总位数 小数后面几位
5.String
VARCHAR -> Variable length character data
CHAR 不常用
VARBINARY -> Variable length binary data.
6.JSON
JSON value type, which can be a JSON object, a JSON array, a JSON number, a JSON string, true, false or null.
7.Date and Time
DATE -> DATE '2001-08-22'
TIME -> TIME '01:02:03.456'
TIME WITH TIME ZONE -> TIME '01:02:03.456 America/Los_Angeles'
TIMESTAMP -> TIMESTAMP '2001-08-22 03:04:05.321'
TIMESTAMP WITH TIME ZONE -> TIMESTAMP '2001-08-22 03:04:05.321 America/Los_Angeles'
INTERVAL '3' MONTH
INTERVAL '2' DAY
8.Structural
ARRAY -> ARRAY[1, 2, 3]
MAP -> MAP(ARRAY['foo', 'bar'], ARRAY[1, 2])
ROW -> A structure made up of named fields. The fields may be of any SQL type, and are accessed with field reference operator .
Example: CAST(ROW(1, 2.0) AS ROW(x BIGINT, y DOUBLE))
可以通过下面的命令查看所有的函数 。不同的presto版本支持的函数也是不同的。
SHOW FUNCTIONS
SHOW FUNCTIONS
SHOW FUNCTIONS
#04 Functions and Operators
1.Logical Operators# 逻辑运算函数
AND OR NOT
null and true -> null
null and false -> false
null or true -> true
null or false -> null
2.Comparison Functions and Operators 比较类函数
2.1Comparison Operators#
< > <= >= <> !=
2.2Range Operator: BETWEEN#
SELECT 3 BETWEEN 2 AND 6 等价于 SELECT 3 >= 2 AND 3 <= 6
2.3IS NULL and IS NOT NULL#
SELECT NULL IS NULL; -- true
SELECT 3.0 IS NULL; -- false
2.4Quantified Comparison Predicates: ALL, ANY and SOME# 【可以关注下】
SELECT 'hello' = ANY (VALUES 'hello', 'world'); -- true
SELECT 21 < ALL (VALUES 19, 20, 21); -- false
SELECT 42 >= SOME (SELECT 41 UNION ALL SELECT 42 UNION ALL SELECT 43); -- true
2.5 LIKE#
3.Conditional Expressions# 条件表达式
3.1CASE
3.2IF
3.3COALESCE
3.4NULLIF
3.5TRY 不常用
4.Lambda Expressions#
x -> x + 1
(x, y) -> x + y
x -> regexp_like(x, 'a+')
x -> x[1] / x[2]
x -> IF(x > 0, x, -x)
x -> COALESCE(x, 0)
x -> CAST(x AS JSON)
x -> x + TRY(1 / 0)
5.Conversion Functions# 类型转换函数
很坑的点:Presto不会自动将bigint值转换为等效的varchar
语法:
cast(value AS type) → type#
try_cast(value AS type) 和cast类似,但如果投射失败,则返回null。
#05 Mathematical Functions and Operators
1.Mathematical Operators#
+ - * / %
2.Mathematical Functions# 这块的数学函数有很多,可以去官网查阅 ,这里仅展示常用的
abs(x) -> 返回x的绝对值
ceil(x)/ceiling(x) -> 向上取整
mod(n, m) -> n 对 m 取模
random()/rand() -> 随机 0.0 <= x < 1.0
round(x) -> x rounded to the nearest integer
round(x, d) -> Returns x rounded to d decimal places
---------------Bitwise Functions#--------------
这块没看 但是感觉很重要
#06 String Functions and Operators
1.String Functions#
concat(...) / operator (||) -> 字符连接
length(string) -> Returns the length of string in characters.
lower(string) → varchar : Converts string to lowercase / upper(string) → varchar#
lpad(string, size, padstring) → varchar / rpad(string, size, padstring) → varchar#
ltrim(string) → varchar# : 删除左边的空格 / rtrim(string) → varchar# / trim(string) → varchar
replace(string, search) → varchar#
split(string, delimiter)# -> array
split_to_map(string, entryDelimiter, keyValueDelimiter) → map<varchar, varchar>#
demo:SELECT(split_to_map(‘a:1;b:2;a:3’, ‘;’, ‘:’, (k, v1, v2) -> v1)); – {
“a”: “1”, “b”: “2”} SELECT(split_to_map(‘a:1;b:2;a:3’, ‘;’, ‘:’, (k, v1, v2) -> CONCAT(v1, v2))); – {
“a”: “13”, “b”: “2”}
position(substring IN string) → bigint# 指定字符在字符中的位置,1开始,如果未找到返回0
substr(string, start) → varchar#
substr(string, start, length) → varchar#
#07 Regular Expression Functions
正则表达式
所有正则表达式函数都使用Java模式语法,具有一些显着的例外
1.regexp_extract_all(string, pattern)# 返回所有匹配项
SELECT regexp_extract_all('1a 2b 14m', '\d+'); -- [1, 2, 14]
SELECT regexp_extract_all('1a 2b 14m', '(\d+)([a-z]+)', 2); -- ['a', 'b', 'm']
2.regexp_extract(string, pattern) → varchar# 返回第一个匹配值
SELECT regexp_extract('1a 2b 14m', '\d+'); -- 1
SELECT regexp_extract('1a 2b 14m', '(\d+)([a-z]+)', 2); -- 'a'
3.regexp_like(string, pattern) → boolean# 区别是返回true or false
SELECT regexp_like('1a 2b 14m', '\d+b'); -- true
4.regexp_replace(string, pattern) → varchar# 匹配上的值直接删除
regexp_replace(string, pattern, replacement) → varchar# 匹配上的值直接替换为后面的值
SELECT regexp_replace('1a 2b 14m', '\d+[ab] '); -- '14m'
SELECT regexp_replace('1a 2b 14m', '(\d+)([ab]) ', '3c$2 '); -- '3ca 3cb 14m'
SELECT regexp_replace('new york', '(\w)(\w*)', x -> upper(x[1]) || lower(x[2])); --'New York'
5.regexp_split(string, pattern)# 没看懂
SELECT regexp_split('1a 2b 14m', '\s*[a-z]+\s*'); -- [1, 2, 14, ]
#08 JSON Functions and Operators
基本的数据类型都是可以cast与Json类型互相转换的
JSON Functions#
1.json_array_contains(json, value) → boolean#
SELECT json_array_contains('[1, 2, 3]', 2);
2.json_array_get(json_array, index) → json#
SELECT json_array_get('["a", [3, 9], "c"]', 1); -- JSON '[3,9]'
3.json_array_length(json) → bigint#
SELECT json_array_length('[1, 2, 3]');
4.json_extract(json, json_path) → json#
SELECT json_extract(json, '$.store.book');
5.json_format(json) → varchar#
SELECT json_format(JSON '[1, 2, 3]'); -- '[1,2,3]'
6.json_parse(string) → json#
SELECT json_parse('[1, 2, 3]'); -- JSON '[1,2,3]'
7.json_size(json, json_path) → bigint#
SELECT json_size('{"x": [1, 2, 3]}', '$.x'); -- 3
#09 Date and Time Functions and Operators
重点
Aggregate Functions#
Window Functions#
#10 Array Functions and Operators#
array_distinct(x) → array# 删除重复值
cardinality(x) → bigint#
contains(x, element) → boolean#
element_at(array(E), index)
array_sum(array(T)) → bigint/double#
filter(array(T), function(T, boolean)) -> array(T)#
SELECT filter(ARRAY [5, -6, NULL, 7], x -> x > 0); -- [5, 7]
transform(array(T), function(T, U)) -> array(U)#
SELECT transform(ARRAY [5, NULL, 6], x -> COALESCE(x, 0) + 1); -- [6, 1, 7]
#11 Map Functions and Operators
cardinality(x) → bigint
element_at(map(K, V), key)
map() → map<unknown, unknown>#
map(array(K), array(V)) -> map(K, V)#
SELECT map(ARRAY[1,3], ARRAY[2,4]); -- {
1 -> 2, 3 -> 4}
map_entries(map(K, V)) -> array(row(K, V))# Returns an array of all entries in the given map.
map_keys(x(K, V)) -> array(K)#
map_values(x(K, V)) -> array(V)#
#12 其他
SHOW TABLES [ FROM schema ]
SHOW STATS FOR table : 返回表的统计信息
SHOW SCHEMAS [ FROM catalog ] [ LIKE pattern ]
SHOW FUNCTIONS
to_char(timestamp, format) → varchar#
to_timestamp(string, format) → timestamp#
to_date(string, format) → date#