基础环境
| linux | ubuntu20.04 |
|---|---|
| java | jdk1.8 |
| hadoop | hadoop2.7.7 |
| spark | spark-2.4.7-bin-hadoop2.7 |
| python | python3.7 |
安装配置
-
下载安装spark:https://spark.apache.org/downloads.html
sudo tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz -C /usr/local/ cd /usr/local mv spark-2.4.7-bin-hadoop2.7/ spark # 更改文件夹名 sudo chown -R hadoop:hadoop spark # hadoop是当前登录Linux系统的用户名 -
需要先安装hadoop,可参考:https://blog.csdn.net/weixin_44018458/article/details/109130969
cd /usr/local/spark/conf cp spark-env.sh.template spark-env.sh vi spark-env.sh # 在文件最后面添加如下内容 export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) -
在 spark 中设置 JAVA_HOME
cd /usr/local/spark/sbin vi spark-config.sh # 在文件末尾添加你自己的jdk export JAVA_HOME=/usr/local/jdk8
保存配置文件后,就可以启动、运行 Spark 了
若需要使用 HDFS 中的文件,则在使用 Spark 前需要启动 Hadoop
设置环境变量
sudo vi /etc/profile
# 添加如下内容
# set spark environment
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/bin:$PATH
# 刷新配置
source /etc/profile
验证是否安装成功
# 为了快速找到我们想要的执行结果,可以通过 grep 命令进行过滤
bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
# 结果
Pi is roughly 3.147475737378687
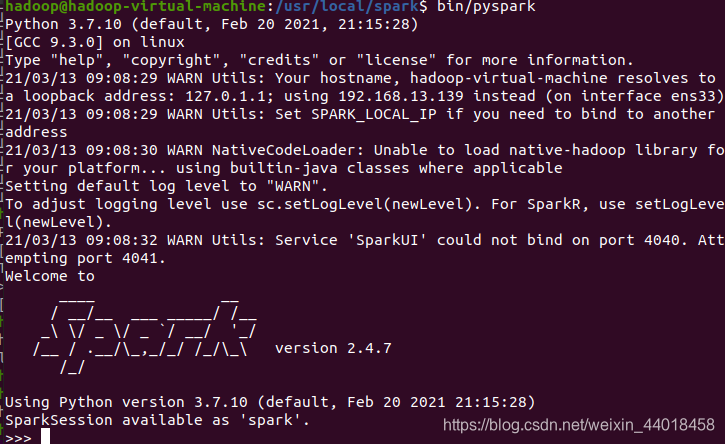
运行 pyspark
ubuntu20.04 自带 python3.8,现在需要安装 python3.7,否则会报错
见常见错误 2. pyspark 2.4.7 不支持python 3.8
常见错误
-
4040端口被占用
sudo apt install net-tools netstat -ap | grep 4040 kill -9 PID号 -
pyspark 2.4.7 不支持python 3.8
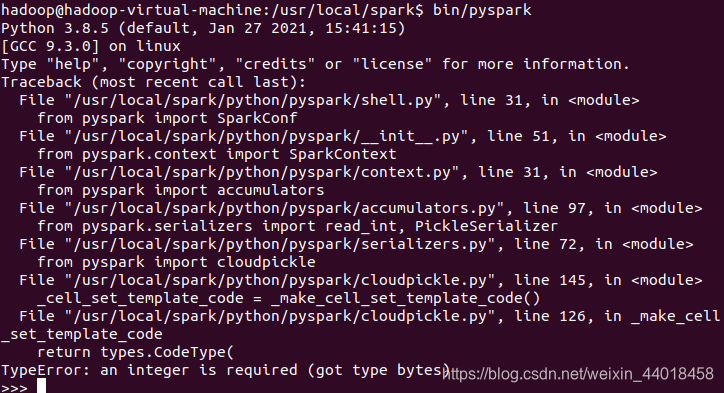
现在降级到Python3.7,应该没问题。# 安装Python3.7 sudo apt update sudo apt install software-properties-common sudo add-apt-repository ppa:deadsnakes/ppa sudo apt install python3.7 # 测试是否安装成功 python3.7 --version # 删除原来的链接,指定新的链接 sudo rm /usr/bin/python sudo ln -s /usr/bin/python3.7 /usr/bin/python -
找不到 python 命令
 扫描二维码关注公众号,回复: 13464800 查看本文章
扫描二维码关注公众号,回复: 13464800 查看本文章
sudo rm /usr/bin/python # 删除原来默认指向python2.7版本的链接 sudo ln -s /usr/bin/python3.7 /usr/bin/python # 指定新的链接