本文从namesrv与broker的交互角度,讲述namesrv的具体作用,以及与broker的关系:
broker启动时,需要指定namesrv地址(一个或多个),在建立好与所有namesrv的连接后,broker的一个重要任务就是向这些namesrv注册路由信息:
namesrv在内存中维护了下面几个数据结构,用于保存broker注册的有关数据,这些数据统称为路由信息,路由信息一个最重要的作用就是告诉consumer和producer,生产者可以往哪里发送消息,消费者可以从哪里进行拉取到消息,(后面一篇文章rocketMq工作原理_客户端与namesrv及broker的交互中有介绍到生产者与消费者如何进行路由数据拉取以及如何使用该数据进行消息生产和消费)
HashMap<String/* topic */, List<QueueData>> topicQueueTable;
HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
brokerAddrTable:维护了所有broker(包括master和slave)的地址信息,brokerData结构如下:

cluster表示当前broker所属的broker集群名称
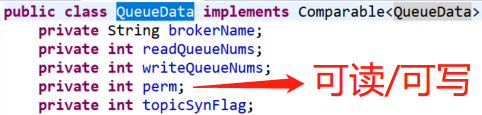
topicQueueTable:维护了所有topic对应的队列信息,如topicA在broker1上对应了几个可读可写queue,在broker2上对应了几个queue,queueData结构如下:(每个topic为何对应多个queue下面有介绍)

brokerLiveTable:维护了所有master-broker的心跳信息:
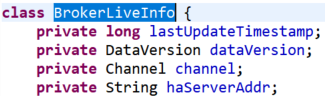
其中dataVersion在broker端维护,每当broker端有配置发生变更,该值会递增,当namesrv发现该值变动时,则会对应更新内存中的数据;
haServerAddr表示该master broker打开的用于主从通信的IP:port信息,在接受broker发来的注册请求时,如果发现是slave broker,则会找到其对应主master的haServerAddr信息,并返回给slave broker,slave broker根据该地址与master建立连接,之后的消息同步以及其他数据的同步就在此连接上进行。
namesrv对于broker下线的处理:
1).如果broker宕机,会调起netty的channel关闭事件,namesrv会进行路由信息清理等操作。namesrv端添加了netty的IdleStateHandler进行会话管理,如果与broker的连接超过120秒(默认)未发生读写事件,则执行会话清理以及路由清理工作。
2)另外,如果与broker端的网络不畅,namesrv端如果发现(10秒一次定时任务进行路由信息扫描)某个broker的路由信息超过120秒未更新,则也会进行路由清理
NameServer在清除失活Broker之后,并不会主动通知客户端,客户端每隔30秒会请求NameServer并获取最新的路由表,那么就意味着,如果只依赖nameServer的主动通知,客户端总会有30秒的延时,无法实时感知Broker服务器的宕机。所以在这个30秒里,生产者依旧会向故障的Broker发送消息,消费者也同样会试图从故障的上拉取消息,那么消息发送和消费的高可用性如何保证呢?
在生产者进行消息发送时,默认选择failover机制(失败切换)来保证消息发送的高可用。当消息生产者向Broker发送消息返回异常后,会选择另外一个Broker上的消息队列进行重试,结合重试机制,实现消息发送的高可用。不同于生产者,消费者发现拉取消息失败后,会选择切换到故障broker的slave broker上进行消息拉取,试下消息拉取的高可用
同时由于不需要NameServer通知众多不固定的生产者,也降低了NameServer实现的复杂性。
namesrv宕机:
namesrv集群目的是为了高可用,前面说到broker向所有namesrv注册路由信息,所以即使其中一台挂掉,也不影响整体使用。当客户端发现自己连接的namesrv挂掉后,会切换到另一台namesrv上获取路由信息,由于多个namesrv之间不会相互通信,所以namesrv上的路由信息并不保证强一致,属于AP架构(分区容错+可用性)
重点来啦:broker中的queue是什么意思,每个topic对应多个queue用意是什么?
要解释这个问题,首先得简单说说broker中消息的存储机制:
broker中,消息内容被存储在commitLog文件中,broker通过commitLog文件顺序写进行消息存储,此外,broker还为每个topic维护了n个queue(对应n个consumequeue文件),如图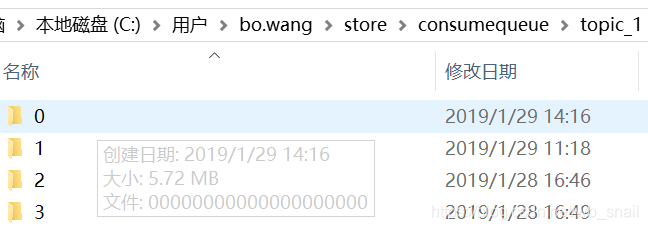 ,topic_1对应了四个consumequeue文件夹,每个文件夹中都有一个或多个consumequeue文件,每次向commitLog中写入一条消息后,还会向对应queueId的queue中写入一条数据,queue中存储的是commitLog中写入消息的具体位置、消息生产时的tag、消息大小等信息(下面就称为位置信息),在消息拉取时,会从queue中先拿到消息的位置信息,再从commitLog中查询。
,topic_1对应了四个consumequeue文件夹,每个文件夹中都有一个或多个consumequeue文件,每次向commitLog中写入一条消息后,还会向对应queueId的queue中写入一条数据,queue中存储的是commitLog中写入消息的具体位置、消息生产时的tag、消息大小等信息(下面就称为位置信息),在消息拉取时,会从queue中先拿到消息的位置信息,再从commitLog中查询。
在消息生产负载均衡,消息消费能力横向扩展,broker横向扩展方面,queue的意义是及其关键的,在下文rocketMq工作原理_客户端与namesrv及broker的交互中会有详细介绍,无论你是仅仅想知道为啥rocketMq扩展能力这么优秀,还是想要深入理解rocketMq,都必须对queue有更清楚的认知
顺带提下broker中消息删除机制:和传统mq(如activityMq),不一样,rocketmq中的消息不会在消费完成后进行删除,而是定期进行清理,这样有以下几个好处:
- rocketMq中一个消息往往被N个消费组消费,但消息只需要存储一份,消费进度单独记录互不影响,同一个消息,不同的消费者组的对其消费是互不影响的。下面一篇文章里会有详细介绍
- 由于消费从哪里消费的决定权一直都是客户端决定,所以只要消息还在,就可以消费到,这使得RocketMQ可以支持其他传统消息中间件不支持的回溯消费