什么是CircleLoss
- CircleLoss来源于旷视研究院《Circle Loss: A Unified Perspective of Pair Similarity Optimization》
- 论文链接地址:https://arxiv.org/abs/2002.10857
- CircleLoss是从相似性优化的角度,正式统一了两种基本学习范式(分类学习和样本对学习)下的损失函数
- 通过进一步泛化,CircleLoss获得了更灵活的优化途径及更明确的收敛目标,提高了所学特征的鉴别能力
- CircleLoss在人脸识别、行人再识别、细粒度图像检索等数据集上取得了极具竞争力的表现
从上述,我们不难发现,CircleLoss就是将分类学习和样本对学习进行了综合,那么什么是分类学习,什么是样本对学习呢
- SoftMaxLoss—>A-SoftMaxLoss—>AM-SoftMaxLoss—>Arc-SoftMaxLoss
- CenterLoss
- TripletLoss
对于上面的损失函数,我们对其进行重新定义:
- SoftMax及其变体、CenterLoss+SoftMax使用的是:图片+标签的训练方式。我们称这类损失函数为:粗分类损失函数(分类学习)
- TripletLoss使用的是:图片样本三元组的训练方式,训练中没有标签的参与。我们称这类损失函数为:细分类损失函数(样本对学习)
在这里我们要注意一下,SoftMax以及TripletLoss仅仅是分类学习和样本对学习的一个常用的代表
这两种学习方法之间其实没有什么本质的区别,他们的目的是一致的
- 最大化类内相似度(s_p)
- 最小化类间相似度(s_n)
在这些损失优化的时候,往往是将 s p s_p sp和 s n s_n sn组合成相似对来进行优化,并试图减小 ( s n − s p ) (s_n-s_p) (sn−sp) 增大 s p s_p sp可以等效为降低 s n 系 分 类 损 失 函 数 s_n系分类损失函数 sn系分类损失函数
为此我们结合所学可以将CircleLoss看成是SoftMax和TripletLoss结合的产物
结合CircleLoss中论文的描述,我们可以形似的推出: C i r c l e L o s s = S o f t M a x L o s s + T r i p l e t L o s s CircleLoss = SoftMaxLoss + TripletLoss CircleLoss=SoftMaxLoss+TripletLoss
回顾一下SoftMaxLoss的公式:
L c e = − l o g e x p ( y i ) ∑ i = 1 i = n e x p ( y i ) L_{ce} = -log\frac{exp(y_i)}{\sum_{i=1}^{i=n}exp(y_i)} Lce=−log∑i=1i=nexp(yi)exp(yi)
回顾一下TripletLoss的公式:
L t r i p l e t = a r g m i n ∑ i = 1 i = n ( ∣ ∣ x i a − x i p ∣ ∣ 2 − ∣ ∣ x i a − x i n ∣ ∣ 2 + t h r e s h o l d ) + L_{triplet} = argmin\sum_{i=1}^{i=n}(||x^a_i - x^p_i||^2 - ||x^a_i - x^n_i||^2 + threshold)_+ Ltriplet=argmin∑i=1i=n(∣∣xia−xip∣∣2−∣∣xia−xin∣∣2+threshold)+
论文中,把上面的两个损失函数进行统一
- 假定给定特征空间中样本x
- 与x类内相似的有K个,记为: s p i ( i = 1 , 2 , 3 , 4 , 5 , 6 , . . . , K ) {s_p^i}(i = 1, 2, 3, 4, 5, 6, ..., K) spi(i=1,2,3,4,5,6,...,K)
- 与x类间相似的有L个,记为: s n j ( j = 1 , 2 , 3 , 4 , 5 , 6 , . . . , L ) {s_n^j}(j = 1, 2, 3, 4, 5, 6, ..., L) snj(j=1,2,3,4,5,6,...,L)
- 注意一点:如果从距离方面考虑:相似度越大、距离就越小
- 为了实现最大化 s p {s_p} sp与最小化 s n {s_n} sn,论文中将所有的 s p {s_p} sp和 s n {s_n} sn进行两两配对,并通过所有的相似性对上穷举、减小二者之差,从而推断出公式

这个公式仅需要制定的修改可以转换为:粗分类损失函数和细分类损失函数
粗分类损失函数

细分类损失函数

将 s p s_p sp和 s n s_n sn组合成相似对来进行优化的缺点
- 优化缺少灵活度
- 因为 s p s_p sp和 s n s_n sn之间的比例是1:1,所以惩罚力度是相同的。
- 收敛状态不明确
- 优化 ( s n − s p ) (s_n-s_p) (sn−sp)得到的决策边界为: s p − s n = m s_p - s_n = m sp−sn=m (m是余量)
- 这个决策边界是平行于 s n = s p s_n = s_p sn=sp,在决策的时候收敛状态模糊(如左下图)

旷视研究院仅仅做了一个小小的改动:把 ( s n − s p ) (s_n - s_p) (sn−sp)范化为 ( n ∗ s n − p ∗ s p ) (n*s_n - p*s_p) (n∗sn−p∗sp)
其中 n n n和 p p p是分别实现 s n 和 s p s_n 和 s_p sn和sp各自的线性函数
这样在网络中学习的时候,学习速度和优化状态相适应。相似度分数偏离最优解越远的时候,加权因子就越大
如此优化的决策边界为 ( n ∗ s n − p ∗ s p ) = m (n*s_n - p*s_p) = m (n∗sn−p∗sp)=m, 这样我们就把这个分界面由原来的平行到后来变成了弧形(右上图)
也就因为此,这一新提出来的损失函数称之为Circle Loss
对比于UnifiedLoss,CircleLoss的公式如下:
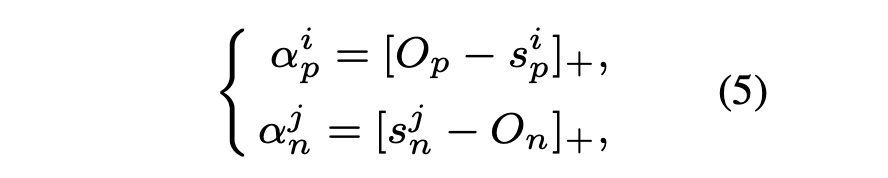
使用 ResNet34 主干网络在 LFW、YTF 和 CFP-FP 上的人脸识别准确度

import torch
from torch import nn, Tensor
def convert_label_to_similarity(normed_feature, label): # 计算类内,类间相似度,用于CircleLoss
similarity_matrix = normed_feature @ normed_feature.transpose(1, 0) # [256, 256]
label_matrix = label.unsqueeze(1) == label.unsqueeze(0) # [256]
positive_matrix = label_matrix.triu(diagonal=1) # 返回矩阵上三角部分(不包括对角线)
negative_matrix = label_matrix.logical_not().triu(diagonal=1) # 返回矩阵上三角部分(不包括对角线)和positive_matrix元素相反
# 对矩阵进行降维,便于获取类内相似度、类间相似度
similarity_matrix = similarity_matrix.view(-1)
positive_matrix = positive_matrix.view(-1)
negative_matrix = negative_matrix.view(-1)
return similarity_matrix[positive_matrix], similarity_matrix[negative_matrix] # 类内相似度、类间相似度
class CircleLoss(nn.Module):
def __init__(self, m, gamma):
super(CircleLoss, self).__init__()
self.m = m # 超参
self.gamma = gamma
self.soft_plus = nn.Softplus() # relu函数的平滑版本
def forward(self, sp, sn):
ap = torch.clamp_min(- sp.detach() + 1 + self.m, min=0.) # sp.detach() 不进行梯度更新
an = torch.clamp_min(sn.detach() + self.m, min=0.) # clamp_min 将数据限定在指定的范围
# 距离差: delta_p + delta_n = 1
delta_p = 1 - self.m
delta_n = self.m
# 获取类内相似度, 类间相似度的逻辑值
logit_p = - ap * (sp - delta_p) * self.gamma
logit_n = an * (sn - delta_n) * self.gamma
# logsumexp(x) = log(sum(exp(x)))
loss = self.soft_plus(torch.logsumexp(logit_n, dim=0) + torch.logsumexp(logit_p, dim=0)) # 调用损失公式
return loss # 返回损失函数
download=True
if __name__ == "__main__":
feat = nn.functional.normalize(torch.rand(128, 2, requires_grad=True)) # 特征图片
lbl = torch.randint(high=10, size=(128,)) # 标签值
print(feat.shape)
print(lbl.shape)
inp_sp, inp_sn = convert_label_to_similarity(feat, lbl) # 获取类内相似度, 类间相似度
criterion = CircleLoss(m=0.25, gamma=128) # 实例化CircleLoss
circle_loss = criterion(inp_sp, inp_sn) # 计算CircleLoss
print(circle_loss.item()) # 打印损失
运行结果
torch.Size([128, 2])
torch.Size([128])
222.5165557861328
手写数字分类

附录:公式推导

