目录
@bandaoyu,本文随时更新,连接:https://blog.csdn.net/bandaoyu/article/details/123018441
心跳是一种用于故障检测的手段。分布式系统中,各种异常,如:宕机、磁盘损坏、网络故障等,时有发生,通过心跳可以快速有效的定位集群中的错误结点,并做及时的处理保证集群正常服务。
心跳一般面对一下三个方面的问题:
错误检测时间和心跳导致的负载间的平衡;
结点间的心跳频率过高,会影响系统性能;
结点间的心跳频率过低导致定位故障结点的时间拉长,影响系统可用性;
ceph心跳机制
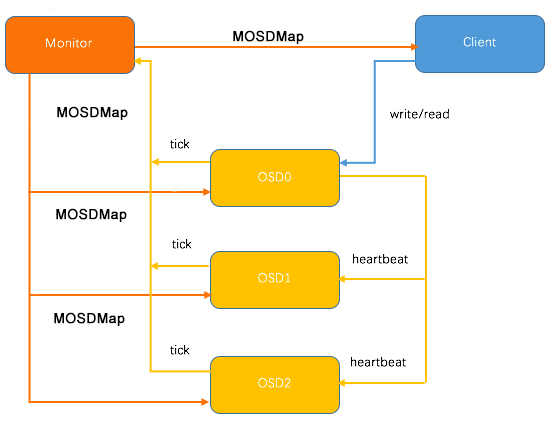
如下图,osd故障检测有mon和osd配合完成,在mon端通过名为OSDMonitor的PaxosService实时监控osd汇报的数据。
在osd端,运行tick_timer_without_osd_lock定时器,周期性的向mon汇报自身状态;
此外,osd对Peer osd进行Heartbeat监控,如果发现Peer osd故障,则及时向mon反馈。
更详细的见:ceph_osd故障检测 - hlc-123 - 博客园 https://www.cnblogs.com/hlc-123/p/10740035.html
进程间的心跳信息需要通过async messenger的传输。在osd启动过程中,创建了四个用于心跳通信的messenger对象(详见http://ceph-osd.cc)
intmain(intargc,constchar**argv){...Messenger *ms_hb_back_client = Messenger::create(g_ceph_context, cluster_msgr_type,entity_name_t::OSD(whoami),"hb_back_client",getpid(), Messenger::HEARTBEAT);Messenger *ms_hb_front_client = Messenger::create(g_ceph_context, public_msgr_type,entity_name_t::OSD(whoami),"hb_front_client",getpid(), Messenger::HEARTBEAT);Messenger *ms_hb_back_server = Messenger::create(g_ceph_context, cluster_msgr_type,entity_name_t::OSD(whoami),"hb_back_server",getpid(), Messenger::HEARTBEAT);Messenger *ms_hb_front_server = Messenger::create(g_ceph_context, public_msgr_type,entity_name_t::OSD(whoami),"hb_front_server",getpid(), Messenger::HEARTBEAT);...// start osderr = osd->init();
由于所有OSD进程处于对等地位,所以每个osd在创建了client的同时也创建了server。至于,front和back和ceph的网络规划有关,ceph将osd间的副本数据、迁移数据的传输交由cluster network,将client和ceph后端的数据传输交由public network,如下图:

front用的是public network,用于检测客户端网络连接问题,back用的是cluster network。
OSD间的心跳机制
发送
在osd→init()中创建了单独的线程heartbeat_thread用于发送心跳:
int OSD::init(){
...// start the heartbeatheartbeat_thread.create("osd_srv_heartbt")...
心跳的处理如下:
发送流程主体代码如下:
void OSD::heartbeat_entry()
{
Mutex::Locker l(heartbeat_lock);
if (is_stopping())
return;
while (!heartbeat_stop)
{
heartbeat();//发送消息
double ? wait = .5 + ((float)(rand() % 10) / 10.0) * (float)cct->_conf->osd_heartbeat_interval; //心跳间隔:在6s的基础上附加随机值
...
}
}void OSD::heartbeat()
{
...
//遍历所有peers,发送心跳
for (map<int, HeartbeatInfo>::iterator i = heartbeat_peers.begin(); i != heartbeat_peers.end(); ++i)
{
int peer = i->first;
i->second.last_tx = now;
if (i->second.first_tx == utime_t())
i->second.first_tx = now;
i->second.con_back->send_message(new MOSDPing(monc->get_fsid(),
service.get_osdmap()->get_epoch(),
MOSDPing::PING, now,
cct->_conf->osd_heartbeat_min_size));
if (i->second.con_front)
i->second.con_front->send_message(new MOSDPing(monc->get_fsid(),
service.get_osdmap()->get_epoch(),
MOSDPing::PING, now,
cct->_conf->osd_heartbeat_min_size));
}
...
}getloadavg() 先获取一下当前系统CPU 1m load, system CPU load有1m, 5m, 15m
con_back/con_front->send_message() [AsyncMessenger] for循环, 分别向heartbeat_peers中的元素发送MOSDPING::PING message, 就是走messenger的send_message发送到目标osd上.
接收
主体流程如下:
osd使用单独的dispatcher类对心跳信息进行处理:
struct HeartbeatDispatcher : public Dispatcher{
OSD *osd;explicit HeartbeatDispatcher(OSD *o) : Dispatcher(o->cct), osd(o) {}...bool ms_dispatch(Message *m) override{
return osd->heartbeat_dispatch(m);}} heartbeat_dispatcher;int OSD::init(){
...//注册dispatcherhb_front_client_messenger->add_dispatcher_head(&heartbeat_dispatcher);hb_back_client_messenger->add_dispatcher_head(&heartbeat_dispatcher);hb_front_server_messenger->add_dispatcher_head(&heartbeat_dispatcher);hb_back_server_messenger->add_dispatcher_head(&heartbeat_dispatcher);...}
收到消息后,通过messenger内部的dispatch线程调用上面加入的heartbeat_dispatcher:
bool OSD::heartbeat_dispatch(Message *m){
switch (m->get_type()){
...case MSG_OSD_PING:handle_osd_ping(static_cast<MOSDPing *>(m));//处理心跳break;...}void OSD::handle_osd_ping(MOSDPing *m){
...switch (m->op){
case MOSDPing::PING: //处理心跳信息{
...if (!cct->get_heartbeat_map()->is_healthy()){
break;}Message *r = new MOSDPing(monc->get_fsid(),curmap->get_epoch(),MOSDPing::PING_REPLY, m->stamp,cct->_conf->osd_heartbeat_min_size);m->get_connection()->send_message(r);//发送回包...}break;case MOSDPing::PING_REPLY: //处理心跳回包{
map<int, HeartbeatInfo>::iterator i = heartbeat_peers.find(from);if (i != heartbeat_peers.end()){
//更新时间戳,避免心跳超时if (m->get_connection() == i->second.con_back){
i->second.last_rx_back = m->stamp;logger->tinc(l_osd_ping_roundtrip_lat, m->stamp - i->second.last_tx);// if there is no front con, set both stamps.if (i->second.con_front == NULL)i->second.last_rx_front = m->stamp;}else if (m->get_connection() == i->second.con_front){
i->second.last_rx_front = m->stamp;}...}
超时检测
心跳是否超时的检测主要是在后面要提到的tick_without_osd_lock函数中完成,tick_without_osd_lock调用heartbeat_check检查其和peer OSD间的心跳是否超过20S,假如超过20s则将该peer OSD加入到failure_queue
void OSD::tick_without_osd_lock(){
// osd_lock is not being held, which means the OSD state// might change when doing the monitor reportif (is_active() || is_waiting_for_healthy()){
heartbeat_lock.Lock();heartbeat_check();heartbeat_lock.Unlock();...}void OSD::heartbeat_check(){
...// check for heartbeat replies (move me elsewhere?)utime_t cutoff = now;cutoff -= cct->_conf->osd_heartbeat_grace;//默认20sfor (map<int, HeartbeatInfo>::iterator p = heartbeat_peers.begin();p != heartbeat_peers.end();++p){
...if (p->second.is_unhealthy(cutoff))//检测是否超时{
if (p->second.last_rx_back == utime_t() ||p->second.last_rx_front == utime_t()){
//插入failure_queue队列,等待上报给MONfailure_queue[p->first] = p->second.last_tx;}else{
failure_queue[p->first] = MIN(p->second.last_rx_back, p->second.last_rx_front);}}}}
超时心跳的上报,也是在tick_without_osd_lock函数中完成的,该函数是被定时器调的,上报至MON的间隔在5-600s之间,大于600s必然上报
void OSD::tick_without_osd_lock(){
...if (is_active() || is_waiting_for_healthy()){
...if (report){
last_mon_report = now;// do any pending reportssend_full_update();send_failures();//错误peer osd的上报}map_lock.put_read();}...}void OSD::send_failures(){
Mutex::Locker l(heartbeat_lock);utime_t now = ceph_clock_now();while (!failure_queue.empty()){
int osd = failure_queue.begin()->first;if (!failure_pending.count(osd)){
entity_inst_t i = osdmap->get_inst(osd);int failed_for = (int)(double)(now - failure_queue.begin()->second);monc->send_mon_message(new MOSDFailure(monc->get_fsid(), i, failed_for,osdmap->get_epoch()));//向MON报告心跳超时failure_pending[osd] = make_pair(failure_queue.begin()->second, i);}failure_queue.erase(osd);}}
当MON收到消息后,会对消息进行处理,如果到达阈值,就会通过paxos算法将osd标记为down,更新osdmap,并通知相关peers。
peer OSD选择
上面梳理的心跳的发送、接收及检测流程,在此还遗留一个重要的问题,就是peer OSD的选择。peer OSD如果选择其他所有结点,则会增加集群负载影响系统性能。peer OSD的选择是通过maybe_update_heartbeat_peers,
- 遍历osd上pg对应的peer将其加入heartbeat_peer;
- 遍历probe集合将其加入到heartbeat_peer;
- 定义了两个集合, 一个是want, 一个是extras, 然后更新want和extras, want集合中都是什么呢? want中放的是osd的相邻osd id, 那什么算相邻osd呢? 有两个函数:
get_next_up_osd_after(whoami),get_previous_up_osd_before(whoami),分别是比当前osd id大的处于up的第一个osd(for循环, 查osd id, 从osd_id + 1开始找; 并且, osd id的大小判断标准是一个循环的, 最大的osd id的后一个是osd id最小的那个); 比osd id小的第一个up osd, want集合中的osd都是extras(额外的), 然后将额外的加入heartbeat peers中.
不是简单的加入heartbeat peers就结束了, 还要做一轮检查: - 删除已经down的osd;
- 假若heartbeat_peer的数量低于10,则随机加入peer OSD;
- 假若heartbeat_peer的数量过多则删除一些此前加入的不属于want(近邻属于want)的peer OSD.
peers的更新时机,主要是在pgmap变更时,具体有以下三处地方:
- pg创建的时候,参见handle_pg_create;
- osdmap变更时,参见handle_osd_map;
- tick定时器会周期性的检测.
peers更新标记,除了maybe_update_heartbeat_peers会操作外,在苹果peering状态机中,也会更新:
总结一下就是,osd启动或者异常退出,monitor会收到消息,然后进行paxos,将结果会反应在osdmap上,进而通知相关osd进程, osd进程收到消息后,会处理map的变更,可能导致pg重新peering。monitor也会收到创建pool或修改pg_num的消息,最终会导致创建pg, osd收到消息创建pg,也会导致peering。osd启动的过程中,load_pg也会导致peering,一旦有peering发生,osd进程的状态就是STATE_WAITING_FOR_HEALTHY, 就可能导致更新peer集合。
tick线程每隔0.5-1.5s检查osd peers,并做更新
OSD和MON间的心跳机制
osd上报给MON:
- 当osd有事件发生时(比如故障或者PG变更)
- osd启动5s内
- osd周期性上报给MON(上报周期最长为600s),上报流程如下(参看上面的超时上报流程):
- OSD检查检查failure_queue中的伙伴OSD的失败信息
- 向MON发送失效报告,并将失败信息加入failure_pending队列,然后将其从failure_queue移除;
- 收到来自failure_queue或者failure_pending中的OSD的心跳时,将其从两个队列中移除,并告知MON取消之前的失效报告;
- 当发生与MON网络重连时,会将failure_pending中的错误报告加回到failure_queue中,并再次发送给Monitor。
除了心跳信息的周期性上报外,osd和mon之间会周期性的发送pgmap信息(可视为osd心跳保活机制的最后保底),具体流程如下
OSD在初始化时,会启动一个定时器线程tick_timer_without_osd_lock
int OSD::init()
{
...
tick_timer.init();
tick_timer_without_osd_lock.init();
...
// tick
tick_timer.add_event_after(get_tick_interval(),
new C_Tick(this));
{
Mutex::Locker l(tick_timer_lock);
tick_timer_without_osd_lock.add_event_after(get_tick_interval(),
new C_Tick_WithoutOSDLock(this));
}
...
}
tick_timer_without_osd_lock线程会周期性执行tick_without_osd_lock函数,该函数除了上述心跳超时检测并上报失败信息外,默认5分钟上报一次beacon,beacon主要是当前节点持有的pg_t信息。
void OSD::tick_without_osd_lock(){
...if (is_active()){
...bool need_send_beacon = false;const auto now = ceph::coarse_mono_clock::now();{
// borrow lec lock to pretect last_sent_beacon from changingMutex::Locker l{min_last_epoch_clean_lock};const auto elapsed = now - last_sent_beacon;if (chrono::duration_cast<chrono::seconds>(elapsed).count() >cct->_conf->osd_beacon_report_interval)//osd_beacon_report_interval默认5分钟{
need_send_beacon = true;}}if (need_send_beacon){
send_beacon(now);//发送beacon}}...}void OSD::send_beacon(const ceph::coarse_mono_clock::time_point &now){
const auto &monmap = monc->monmap;// send beacon to mon even if we are just connected, and the monmap is not// initialized yet by then.if (monmap.epoch > 0 &&monmap.get_required_features().contains_all(ceph::features::mon::FEATURE_LUMINOUS)){
MOSDBeacon *beacon = nullptr;{
Mutex::Locker l{min_last_epoch_clean_lock};beacon = new MOSDBeacon(osdmap->get_epoch(), min_last_epoch_clean);...}monc->send_mon_message(beacon);}...}
假如900s后,某OSD的pgmap一直不更新,也会标记该OSD down(在mon主操作),但是这种状况下上层业务肯定会slow。
总结:
- 及时:建立心跳的OSD可以快速发现异常的OSD并上报给MON,MON在几分钟内把该OSD标记down;
- 适当的压力:由于有伙伴OSD汇报机制,MON和OSD间的心跳更像是一种保险措施,因此OSD向MON发送心跳的间隔可以长达600s,MON的检测阈值也可以长达900s。
- 容忍网络抖动:收到汇报的信息后,不立即下线OSD
- 扩散:作为中心节点的MON并没有在更新OSDMap后尝试广播通知所有的OSD和client,而是惰性的等待OSD和client来获取。减少了压力简化了交互逻辑。
作者:路锦博 https://zhuanlan.zhihu.com/p/128631881
CEPH网络模块使用案例:OSD心跳检测机制
Ceph网络模块使用案例:OSD心跳检测机制 - 灰信网(软件开发博客聚合)
2.2 心跳机制介绍
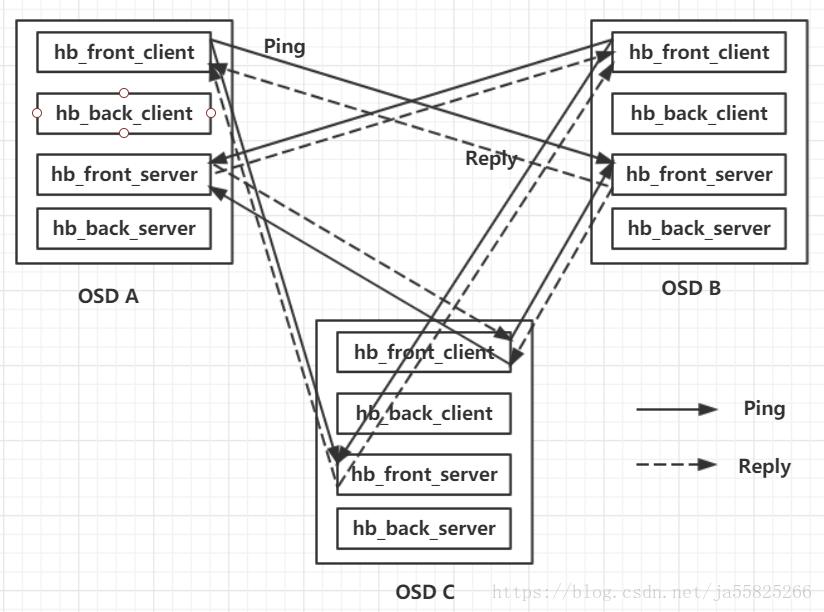
OSD 中有一个heartbeat_thread,这个heartbeat_thread的作用就是不断的发送ping请求给其他节点。在Ceph中,OSD的地位都是对等的,每一个OSD在向其他OSD发送ping消息的同时,也会收到其他OSD发来ping消息。OSD收到ping消息后会发送一个回复消息reply message。在部署ceph的时候,通常会使用两张网卡front和back,将流量分开。所以OSD使用两对messenger和来分别发送和监听front额back的ping心跳。图中展示了一个3个OSD的ceph集群的心跳检测过程,只画出了front网卡的心跳检测,back雷同。
2.3 心跳检测中网络模块的使用
我们着重看两个osd节点间如何通信。上图展示了OSD A向OSD B发送Ping消息(hb_front_client_messenger(A) ->ms_hb_front_server(B)),然后OSD B收到消息后交给dispatcher进行处理,然后发送回复消息给OSD A (hb_front_client_messenger(A) <-ms_hb_front_server(B))的过程。具体的可以拆分成5个步骤:
- ① 连接(connection)建立
- ② Ping消息发送
- ③ Ping消息接受及处理
- ④ 回复消息
- ⑤ 处理PING_REPLY
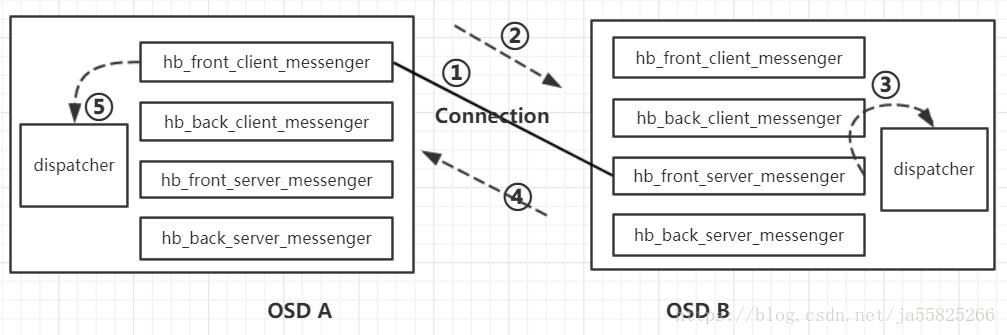
下面对这五个步骤进行一一介绍。
① 连接(connection)建立
获取目标 messenger B的链接connection
conn =hb_front_client_messenger(A)->get_connection(dest_server_B),如果没有链接就创建一个。
monitor中的osdmap记录了每一个osd的front地址和back地址,这个是在osd启动的时候就告诉monitor的。
OSDService::get_con_osd_hb(),首先先获取osdmap,获取目标osdB的front地址,然后在A的messenger hb_front_client_messenger中创建一个connection。
-
pair<ConnectionRef,ConnectionRef> OSDService::get_con_osd_hb(int peer, epoch_t from_epoch) -
{ -
OSDMapRef next_map = get_nextmap_reserved(); -
// service map is always newer/newest -
assert(from_epoch <= next_map->get_epoch()); -
pair<ConnectionRef,ConnectionRef> ret; -
if (next_map->is_down(peer) || -
next_map->get_info(peer).up_from > from_epoch) { -
release_map(next_map); -
return ret; -
} -
ret.first = osd->hb_back_client_messenger->get_connection(next_map->get_hb_back_inst(peer)); -
if (next_map->get_hb_front_addr(peer) != entity_addr_t()) -
ret.second = osd->hb_front_client_messenger->get_connection(next_map->get_hb_front_inst(peer)); -
release_map(next_map); -
return ret; -
}
osd->hb_back_client_messenger->get_connection(next_map->get_hb_back_inst(peer)); if (next_map->get_hb_front_addr(peer) != entity_addr_t()) ret.second = osd->hb_front_client_messenger->get_connection(next_map->get_hb_front_inst(peer)); release_map(next_map); return ret; }
② Ping消息发送
在OSD::heartbeat()中,对记录了osd连接信息map进行遍历,每一个heartbeatinfo中记录了一个目标osd的链接信息(connection),通过这些conns把消息发送出去。重点的就是红色部分。
-
void OSD::heartbeat() -
{ -
...... -
// send heartbeats -
for (map<int,HeartbeatInfo>::iterator i = heartbeat_peers.begin(); -
i != heartbeat_peers.end(); -
++i) { -
int peer = i->first; -
i->second.last_tx = now; -
if (i->second.first_tx == utime_t()) -
i->second.first_tx = now; -
dout(30) << "heartbeat sending ping to osd." << peer << dendl; -
i->second.con_back->send_message(new MOSDPing(monc->get_fsid(), -
service.get_osdmap()->get_epoch(), -
MOSDPing::PING, now, -
cct->_conf->osd_heartbeat_min_size)); -
if (i->second.con_front) -
i->second.con_front->send_message(new MOSDPing(monc->get_fsid(), -
service.get_osdmap()->get_epoch(), -
MOSDPing::PING, now, -
cct->_conf->osd_heartbeat_min_size)); -
...... -
} -
}
i->second.con_back->send_message(new MOSDPing(monc->get_fsid(), service.get_osdmap()->get_epoch(), MOSDPing::PING, now, cct->_conf->osd_heartbeat_min_size)); if (i->second.con_front) i->second.con_front->send_message(new MOSDPing(monc->get_fsid(), service.get_osdmap()->get_epoch(), MOSDPing::PING, now, cct->_conf->osd_heartbeat_min_size)); ...... } }
③ Ping消息接受及处理
OSD B收到消息,Messenger B内部的dispatch线程会调用事先键入的dispatcher对消息进行处理。HeartbeatDispatcher会将message交给osd->heartbeat_dispatch()处理。
-
struct HeartbeatDispatcher : public Dispatcher { -
OSD *osd; -
explicit HeartbeatDispatcher(OSD *o) : Dispatcher(o->cct), osd(o) {} -
bool ms_dispatch(Message *m) override { -
return osd->heartbeat_dispatch(m); -
} -
...... -
}heartbeat_dispatcher -
bool OSD::heartbeat_dispatch(Message *m) -
{ -
dout(30) << "heartbeat_dispatch " << m << dendl; -
switch (m->get_type()) { -
case CEPH_MSG_PING: -
dout(10) << "ping from " << m->get_source_inst() << dendl; -
m->put(); -
break; -
case MSG_OSD_PING: -
handle_osd_ping(static_cast<MOSDPing*>(m)); -
break; -
default: -
dout(0) << "dropping unexpected message " << *m << " from " << m->get_source_inst() << dendl; -
m->put(); -
} -
return true; -
}
osd->heartbeat_dispatch(m); } ...... }heartbeat_dispatcher bool OSD::heartbeat_dispatch(Message *m) { dout(30) << "heartbeat_dispatch " << m << dendl; switch (m->get_type()) { case CEPH_MSG_PING: dout(10) << "ping from " << m->get_source_inst() << dendl; m->put(); break; case MSG_OSD_PING: handle_osd_ping(static_cast<MOSDPing*>(m)); break; default: dout(0) << "dropping unexpected message " << *m << " from " << m->get_source_inst() << dendl; m->put(); } return true; }
heartbeat_dispatch()根据消息的type进行处理,因为消息的type是MSG_OSD_PING,调到OSD::handle_osd_ping(MOSDPing *m)进行处理, 进入case MOSDPing::PING:
-
void OSD::handle_osd_ping(MOSDPing *m) -
{ -
switch (m->op) { -
case MOSDPing::PING: -
{ -
//做了一系列处理 -
... -
//发送回复包 -
Message *r = new MOSDPing(monc->get_fsid(), -
curmap->get_epoch(), -
MOSDPing::PING_REPLY, m->stamp, -
cct->_conf->osd_heartbeat_min_size); -
m->get_connection()->send_message(r); -
... -
} -
case MOSDPing::PING_REPLY: -
{ -
// 更新时间戳,避免心跳超时 -
// osd有专门的tick线程进行周期性的检查,如果发现有心跳超时的,就会上报monitor -
} -
}
case MOSDPing::PING: { //做了一系列处理 ... //发送回复包 Message *r = new MOSDPing(monc->get_fsid(), curmap->get_epoch(), MOSDPing::PING_REPLY, m->stamp, cct->_conf->osd_heartbeat_min_size); m->get_connection()->send_message(r); ... } case MOSDPing::PING_REPLY: { // 更新时间戳,避免心跳超时 // osd有专门的tick线程进行周期性的检查,如果发现有心跳超时的,就会上报monitor } }
④ 回复消息
第③步中,在OSD B的dispatcher中对消息做一系列处理后,会封装一个回复消息PING_REPLY,然后发送OSD A。
------------------------------------------------------------------------
Message *r = new MOSDPing(monc->get_fsid(),
curmap->get_epoch(),
MOSDPing::PING_REPLY, m->stamp,
cct->_conf->osd_heartbeat_min_size);
m->get_connection()->send_message(r);
------------------------------------------------------------------------
这个过程和前面类似,不同的是这次是OSD B的Messenger去获取connection链接,(这个链接就是之前OSD A建立的链接,通过看Asyncmessenger.cc 可以看到在执行第②步中AsyncConnection::send_message(Message *m)时,通过 m->set_connection(this);将connection赋给了message,所以说A向B发送消息和B向A发送回复消息都是用的同一条链接connection),发送回复消息给OSD A。
⑤ 处理PING_REPLY
OSD A 的Messenger(hb_front_client_messenger)监听到了回复消息,交给自己的Dispatcher处理。
还是先进入osd->heartbeat_dispatch(m)的MSG_OSD_PING,然后使用OSD::handle_osd_ping(MOSDPing *m)根据 消息的type做相应处理,这次是进入ping reply
-
void OSD::handle_osd_ping(MOSDPing *m) -
{ -
switch (m->op) { -
case MOSDPing::PING: -
{ -
... -
//发送回复包 -
Message *r = new MOSDPing(monc->get_fsid(), -
curmap->get_epoch(), -
MOSDPing::PING_REPLY, m->stamp, -
cct->_conf->osd_heartbeat_min_size); -
m->get_connection()->send_message(r); -
... -
} -
case MOSDPing::PING_REPLY: -
{ -
// 更新时间戳,避免心跳超时 -
// osd有专门的tick线程进行周期性的检查,如果发现有心跳超时的,就会上报monitor -
} -
}
case MOSDPing::PING_REPLY: { // 更新时间戳,避免心跳超时 // osd有专门的tick线程进行周期性的检查,如果发现有心跳超时的,就会上报monitor } }
可以看出,心跳的发送流程是很简单的,也是很独立的。在设计分布式系统的时候,为了保证集群的内部状态正确,应尽量不要引入过多复杂的因素影响心跳的流程。 毕竟心跳快速正确的处理是确保集群运转正常的最基本条件。