1 Flink Table与Kafka集成案例
1.1 需求
需求:Flink Table从kafka消费点击日志(JSON),转化为CSV格式之后输出到Kafka。
1.2 添加Maven依赖
FlinkTable集成Kafka需引入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
1.3 代码实现
Flink Table API实现Kafka生产者与消费者的完整代码如下所示。
package com.bigdata.chap02;
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkTableAPIKafka2Kafka {
public static final String input_topic = "clicklog_input";
public static final String out_topic = "clicklog_output";
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2、创建kafka source table
final Schema schema = Schema.newBuilder()
.column("user", DataTypes.STRING())
.column("url", DataTypes.STRING())
.column("cTime", DataTypes.STRING())
.build();
tEnv.createTemporaryTable("sourceTable", TableDescriptor.forConnector("kafka")
.schema(schema)
.format("json")
.option("topic",input_topic)
.option("properties.bootstrap.servers","hadoop1:9092")
.option("properties.group.id","clicklog")//每次都从最早的offsets开始
.option("scan.startup.mode","latest-offset")
.build());
//3、创建 kafka sink table
tEnv.createTemporaryTable("sinkTable", TableDescriptor.forConnector("kafka")
.schema(schema)
.format("csv")
.option("topic",out_topic)
.option("properties.bootstrap.servers","hadoop1:9092")
.build());
//5、输出(包括执行,不需要单独在调用tEnv.execute("job"))
tEnv.from("sourceTable")
.select($("user"), $("url"),$("cTime"))
.executeInsert("sinkTable");
}
}
1.4 打开Kafka数据生产与消费
#查看topic列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list
#创建输入与输出topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic clicklog_input --replication-factor 3 --partitions 3
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic clicklog_output --replication-factor 3 --partitions 3
#Kafka 输出topic打开消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic clicklog_output
#打开Kafka输入Topic生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic clicklog_input
{"user":"Mary","url":"./home","cTime":"2022-02-02 12:00:00"}
如果clicklog_input topic的生产者输入数据之后,在clicklog_output topic端能消费到数据,则说明Flink Table打通了Kafka端到端的数据流程。
2 Kafka SQL Connector高级特性
2.1 key和value格式
#仅指定value format
tEnv.createTemporaryTable("sourceTable", TableDescriptor.forConnector("kafka")
.schema(schema)
.format("json")
.option("topic",input_topic)
.option("properties.bootstrap.servers","hadoop1:9092")
.option("properties.group.id","clicklog")//每次都从最早的offsets开始
.option("scan.startup.mode","latest-offset")
.build());
#指定key和value format
tEnv.createTemporaryTable("sourceTable", TableDescriptor.forConnector("kafka")
.schema(schema)
.option("key.format","json")
.option("value.format","json")
.option("topic",input_topic)
.option("properties.bootstrap.servers","hadoop1:9092")
.option("properties.group.id","clicklog")//每次都从最早的offsets开始
.option("scan.startup.mode","latest-offset")
.build());
注意:format("json")和option("value.format",
"json")二选一,二者等价
2.2 Topic和Partition发现
可以通过topic或者topic-pattern来配置主题。

注意:要允许在作业开始运行后发现动态创建的topic,请为 scan.topic-partition-discovery.interval 设置一个非负值。
2.3 读取位置
作为source,是可以通过scan.startup.mode选项指定从哪个位置开始消费,可选的值如下。

2.4 Sink分区
当kafka作为sink时,可以通过sink.partitioner指定partitioner。支持的选项值如下。
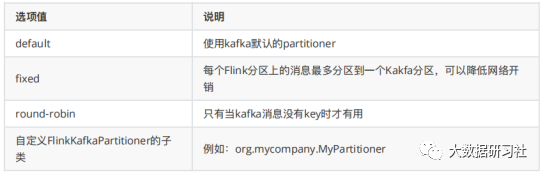
2.5 致性保证
默认情况下,如果启用checkpoint,Kafka sink使用at-least-once一致性语意。在启用checkpoint的前题下,可通过sink.delivery-guarantee来调整一致性语意:

一旦启用了事物来保证exactly-once语意,一定要注意下游消费者要配置isolation.level为read_committed(默认是read_uncommitted)。