一、概要
如今,很多监控系统开始倾向于使用Promethus+grafana的解决方案,Prometheus 是一个开源系统监控和警报工具包,最初在 SoundCloud 构建,采用go语言开发,它启发于 Google 的 borgmon 监控系统。目前,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司维护。为了强调这一点,并明确项目的治理结构,Prometheus 于 2016 年加入CNCF云原生计算基金会,成为继 Kubernetes 之后的第二个托管项目。

Prometheus 将其指标收集并存储为时间序列数据,即指标信息与记录它的时间戳一起存储,以及添加可选键值对的标签。Prometheus 最大优点就是可更好地记录任何纯数字时间序列,所以它有时也被称为一个时序数据库。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的架构。尤其在微服务中,它对多维数据收集和查询的支持是一个特殊的优势。但Prometheus收集的数据可能不够详细和完整,Prometheus 不适合做审计计费,因为它的数据是按一定时间采集的,关注的更多是系统的运行瞬时状态以及趋势,即使有少量数据没有采集也能容忍,但是审计计费需要记录每个请求,并且数据长期存储,这个 Prometheus 无法满足,这时可配合其他系统来收集和分析数据。


产品主要特性:
- 具有由度量名称和键/值对标识的**时间序列数据(TSDB(Time Series Database)时序列数据库)**的多维数据模型
- PromQL,一种利用这种维度的灵活查询语言
- 无需依赖分布式存储;单个服务器节点是自治的,可以使用联邦集群让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)对其进行扩展;参考:平均一个采样数据占3.5B左右,共320万个时间序列,每30秒采样一次,如此持续运行60天,占用磁盘空间大约为228GB左右;
- 通过 HTTP 上的拉模型进行时间序列收集,采用拉模式为主、推模式为辅的方式采集数据。
- 通过中间网关来推送这些时间序列
- 通过服务发现或静态配置来发现目标
- 支持多种图形模式和仪表板插件,比如Grafana
与Nagios、Zabbix、Ganglia、Open-Falcon等很多监控系统相比,Prometheus最主要的特色有4个:
- 通过PromQL实现多维度数据模型的灵活查询。
- 定义了开放指标数据的标准,自定义探针(如Exporter等),编写简单方便。
- PushGateway组件让这款监控系统可以接收监控数据。
- 提供了VM和容器化的版本。
选择 Prometheus原由,请参看Prometheus与其他监控对比。
二、架构及原理

Prometheus 生态系统由多个组件组成,其中许多是可选的:
Prometheus 服务器:它是Prometheus组件中的核心部分,负责从 Exporter 拉取实现对监控数据的获取,存储及查询。可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。
客户端库:用于检测应用程序代码的;Prometheus 对主流语言实现了客户端库的封装,通过客户端库,企业可以根据自己的业务需求,实现不同维度,适合自身应用业务的监控体系。Prometheus 客户端库主要提供四种主要的 metric 类型:
Counter: 一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
Gauge: 一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。可以任意加减。
Histogram: -可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
PushGateway推送网关:主要用于短期的jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus中间网关推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。(PushGatway类似zabbix proxy)
exporters:HAProxy、StatsD、Graphite 等各自对应的服务支持;Exporter将监控数据采集的端的数据通过HTTP服务的形式暴露给Prometheus Server,将其转化为Prometheus支持的格式,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。可以将Exporter分为2类:
\
- 直接采集:即原生支持的
这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
\- 间接采集:第三方厂商支持的
原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。如:Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager:在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警。当AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。
\
工作原理: Prometheus 可直接从监控作业任务或通过一个中间者(推送网关)从短期作业中进行监控指标的抓取。并将这些所有抓取的样本存储在本地,并对这些数据执行规则匹配,以聚合现有数据和记录新的时间序列(存储到新的时间序列中)或生成警报。 而Grafana 或其他 API 消费者则可用于可视化收集的数据。Prometheus server通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。




告警流程图:


上图中的sendmessages告警模块基于springboot2进行开发,根据prometheus-manager-web设置的告警规则发送告警消息。所有alertmanager送来的告警消息,会存储至sendmessages的内存队列,通过ThreadPoolExecutor维护线程池,定时扫描内存队列里是否有消息,如有则进行发送。代码实现:
if (“firing”.equals(ai.getAlertStatus())) {
title = “<font color=#FF0000>告警</font> <br>”;
} else {
title = “<font color=#00FF00>恢复</font> <br>”;
}
使用 node_exporter,就可以轻松采集主机信息,更多 exporter 使用,请参考Third-party exporters;对于需要兼容传统 push 方式的 metrics 收集,可以使用 Push Gateway,将数据推送到 Push Gateway,即可快速实现指标采集,以下为采集本机进程数的脚本实现:

2.2、其他架构参考
1)telegraf+prometheus+grafana+aletmanager+dingtalk实现主机监控告警

telegraf:数据采集组件,类似于zabbix的agent,作为Prometheus的采集客户端,默认端口9273
prometeus:时序型数据库,也是整套监控的核心,提供web页面,默认主动从各个telegraf拉取数据,并根据rules产生告警推送给alertmanager管理告警
alertmanager:告警管理组件,控制告警频率、支持静默和抑制告警,并将告警发送给对应的route(邮件、钉钉、企微等)
dingtalk:管理alermanager发送过来的告警,可以定制告警模板,发送给指定的钉钉群
grafana:图形化界面,可以配置多种数据源(zabbix、prometeus、influx、redis等等)将数据源进行图形化展示,也可以配置告警,并发送告警
2)监控结构层

3)k8s监控

4)监控时序:云原生 UI 根据服务端返回的 Grafana 地址,访问获取到自定义模版,界面展示;

5)zabbix架构回顾

zbbix官方文档。
zabbix告警流程:


6)open-Falcon
OpenFalcon项目最初由小米公司发起的,是一款企业级、高可用、可扩展的开源监控解决方案。整个系统的后端,全部golang编写,portal和dashboard使用python编写。更多参看官方文档。


每台服务器都安装falcon-agent。falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标。只要安装了falcon-agent,机器就会自动采集各项指标,主动上报,不需要用户在server做任何配置。虽然server端有较大的压力,但是open-falcon的服务端组件单机性能足够高,同时可以水平扩展,所以自动采集足够多的数据,更方便SRE和DEV事后追查问题。另外,falcon-agent也提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
常见的OpenFalcon包含transfer、hbs、agent、judge、graph、API几个进程。但没有提供用户界面。用户界面的解决方案是OpenFalcon官方提供的Dashboard,由python编写的一个Web服务。Dashboard调用OpenFalcon的API节点REST,完成用户认证,查询历史等操作。 以下是各个节点的数据流向图,主数据流向是agent -> transfer -> judge/graph:

浏览器访问:http://ip:8081

7)Zabbix、Nagios、Open-Falcon这3大开源运维监控工具的比较

三、Prometheus系统部署
3.1、部署配置参考如下
1)执行./prometheus --help //会列出一些常用的配置参数
–config.file=“prometheus.yml” 默认prometheus的配置文件
–web.listen-address=“0.0.0.0:9090” 默认监听9090端口
–web.enable-lifecycle 开启热重启,可以通过web服务reload prometheus
–web.enable-admin-api 打开以后可以打快照、删除数据
–storage.tsdb.retention.time 默认tsdb数据存放15天,我将配置为30天
2)/usr/lib/systemd/system/下创建自启动服务:
cp ./watchdog-ping.service /usr/local/prometheus/
mv watchdog-ping.service prometheus.service
vi prometheus.service //修改配置如下
[Unit]
Description=prometheus
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle --web.enable-admin-api --storage.tsdb.path=/home/software/prometheus-data --web.listen-address=0.0.0.0:9090 --web.external-url= $PROM_EXTRA_ARGS
Restart=on-failure
StartLimitInterval=60
RestartSec=5
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
完成后,授权:
chown prometheus.prometheus ./prometheus.service
mv ./prometheus.service /usr/lib/systemd/system/
验证:
systemctl status prometheus
systemctl daemon-reload //当修改了prometheus.yml需要让其生效时,直接reload热重启,或执行:curl -XPOST http://127.0.0.1:9090/-/reload
systemctl list-dependencies multi-user.target
systemctl enable prometheus
systemctl start prometheus
更多Prometheus参数配置,请参看Prometheus运行参数详解。
3)验证
浏览器打开http://ip:9090(IP:9090端口)即可打开普罗米修斯自带的监控页面,使用http://ip:9090/targets 可查看监控信息;
3.2、添加Grafana组件
由于prometheus本身提供的图形页面过于简陋,所以我能使用grafana来提供图形页面展示。它本身支持多种数据来源,默认监听端口3000,同时自带告警功能,且告警规则可在监控图形上直接配置,但此种方式不支持模板变量,不便批量应用。
1)软件获取
grafana程序下载地址:https://grafana.com/grafana/download
grafana dashboard 下载地址: https://grafana.com/grafana/download/
2)软件安装
#rpm包安装
wget https://dl.grafana.com/oss/release/grafana-7.2.2-1.x86_64.rpm
sudo yum install grafana-7.2.2-1.x86_64.rpm
#
3)创建自启动服务
[Unit]
Description=Grafana
Documentation=http://docs.grafana.org
Wants=network-online.target
After=network-online.target
After=prometheus.service
[Service]
EnvironmentFile=/etc/sysconfig/grafana-server
User=grafana
Group=grafana
Type=simple
Restart=on-failure
WorkingDirectory=/usr/local/grafana
RuntimeDirectory=grafana
RuntimeDirectoryMode=0750
ExecStart=/usr/sbin/grafana-server
--config=${CONF_FILE}
--pidfile=${PID_FILE_DIR}/grafana-server.pid
--packaging=rpm
cfg:default.paths.logs=${LOG_DIR}
cfg:default.paths.data=${DATA_DIR}
cfg:default.paths.plugins=${PLUGINS_DIR}
cfg:default.paths.provisioning=${PROVISIONING_CFG_DIR}
LimitNOFILE=10000
TimeoutStopSec=20
[Install]
WantedBy=multi-user.target
完成后:
systemctl enable grafana-server.service
systemctl restart grafana-server.service
4)其他
dashboard模板,下载地址:https://grafana.com/grafana/download/
浏览器访问http://ip:3000(IP:3000端口),即可打开grafana页面,默认用户名密码都是admin,初次登录会要求修改默认的登录密码


3.3 监控代理node_exporter部署
即所谓agent端,prometheus官方提供了诸多exporter,在各监控节点主机部署后,负责抓取主机及系统各项信息,如cpu,mem ,disk,networtk.filesystem,…等等各项基本指标,默认监听端口: 9100,它将抓取到的各项指标metrics 通过http协议对方发布,供prometheus server端抓取,监控非常全面。
1)软件下载
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
2)配置
useradd -r -m -d /home/prometheus prometheus
mv node_exporter-1.3.1.linux-amd64/node_exporter /data
chmod +x node_exporter
ln -s /data/node_exporter /usr/local/bin/
./node_exporter --help # 查看支持的所有collectors,可根据实际需求 enable 和 disabled 各项指标收集
3)创建自启动脚本
vi /lib/systemd/system/node_exporter.service
[Unit]
# wallet
Description=Node Exporter Mtrices
[Service]
LimitNOFILE=65535
LimitNPROC=65535
LimitCORE=infinity
LimitMEMLOCK=infinity
EnvironmentFile='NODE_OPTS="--collector.textfile.directory /var/lib/node_exporter/textfile_collector \
--collector.tcpstat \
--collector.processes \
--collector.netclass.ignored-devices="^(cali.*|veth.*|cni.*|docker.*|flannel.*)$" \
--collector.netdev.ignored-devices="^(cali.*|veth.*|cni.*|docker.*|flannel.*)$" \
--collector.filesystem.ignored-fs-types="^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs|tmpfs)$" \
--collector.vmstat.fields="^(oom_kill|pgpg|pswp|pg.*fault).*" \
--web.disable-exporter-metrics"'
ExecStart=/usr/local/bin/node_exporter \$NODE_OPTS
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
完成后,启动:
systemctl daemon-reload
systemctl enable node_exporter.service
systemctl restart node_exporter
systemctl status node_exporter
4)验证:
curl http://localhost:9100/metrics
……
四、附录
1)其他监控
java全链路追踪 Sleuth+Zipkin : 我们已经接触过几种微服务的监控方式,比如:
Spring Boot Actuator 监控微服务,:https://blog.csdn.net/qq_33257527/article/details/88294016
Spring Boot Admin也是监控微服务,他是把Actuator的数据用可视化的方式呈现出来,Hystrix Dashboard监控Hystrix服务,Hystrix Turbine聚合多个Hystrix服务的监控信息等,接下来我们要讨论的是微服务的“跟踪"。
Prometheus jmx :https://www.cnblogs.com/caizhenghui/p/9132414.html 下载地址: https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
Prometheus监控tomcat:https://blog.csdn.net/tiny_du/article/details/108402265
Kube-prometheus监控jmx指标 : https://www.cnblogs.com/leozhanggg/p/14059720.html
2)监控的一些概念
SLA:服务水平协议
你承诺向用户提供的服务,如果你无法满足,可能会受到惩罚。
例如:“99.5%”的可用性。
关键词:合同
SLO:服务水平目标
你在内部设置的目标,驱动你的测量阈值(例如,仪表板和警报)。通常,它应该比SLA更严格。
示例:“99.9%”可用性(所谓的“三个9”)。
关键字:阈值
SLI:服务水平指标
你实际测量的是什么,以确定你的SLO是否在满足目标/偏离目标。
示例:错误率、延迟。
关键词:指标。
3)Linux 系统服务配置
#service配置文件分为[Unit]、[Service]、[Install]三个部分。
#[Unit]部分:指定服务描述、启动顺序、依赖关系,包括Description、Documentation、After、Before、Wants、Requires。
[Unit]
#Description指定当前服务的简单描述。
Description=nginx代理服务
#Documentation指定服务的文档,可以是一个或多个文档的URL,可选,一般不用配置该项。
Documentation=http://nginx.org/en/docs
#启动顺序,After和Before。
#注意,After和Before字段只涉及启动顺序,不涉及依赖关系。
#After表示当前服务在network.target之后启动,可以指定多个服务,以空格隔开。
After=network.target sshd.service
After=sshd-keygen.service
#Before表示当前服务在tomcat.target之前启动,可以设置多个,以空格隔开,可选,根据实际需要配置。
Before=tomcat.service
#依赖关系,Wants和Requires,可选,根据实际需要配置。
#Wants为"弱依赖"关系,即如果"mysqld.service"启动失败或停止运行,不影响nginx.service继续执行。
#Requires为"强依赖"关系,即如果"mysqld.service"启动失败或异常退出,那么nginx.service也必须退出。
#想要添加多个服务,可以多次使用此选项,也可以设置一个空格分隔的服务列表。
#注意,Wants与Requires只涉及依赖关系,与启动顺序无关,默认情况下是同时启动的。
Wants=mysqld.service
Requires=mysqld.service
#[Service]部分:指定启动行为,包括Type、EnvironmentFile、ExecStart、ExecReload、ExecStop、PrivateTmp。
[Service]
#Type指定服务的启动类型,必须为simple, exec, forking, oneshot, dbus, notify, idle 之一。常用simple和forking。
#simple(默认值):ExecStart启动的进程为该服务主进程。
#exec:exec与simple类似,不同之处在于,只有在该服务的主服务进程执行完成之后,systemd才会认为该服务启动完成。 其他后继单元必须一直阻塞到这个时间点之后才能继续启动。
#forking:ExecStart将以fork()方式启动,此时父进程将会退出,子进程将成为主进程。
#oneshot:oneshot与simple类似,不同之处在于,只有在该服务的主服务进程退出之后,systemd才会认为该服务启动完成,才会开始启动后继单元。 此种类型的服务通常需要设置RemainAfterExit=选项。当Type= 与 ExecStart=都没有设置时,Type=oneshot 就是默认值。
#dbus:类似于simple,但会等待D-Bus信号后启动。
#notify:类似于simple,启动结束后会发出通知信号,然后 Systemd 再启动其他服务。
#idle:类似于simple,但是要等到其他任务都执行完,才会启动该服务。一种使用场合是为让该服务的输出,不与其他服务的输出相混合。
#建议对长时间持续运行的服务尽可能使用Type=simple(这是最简单和速度最快的选择)。注意,因为simple类型的服务 无法报告启动失败、也无法在服务完成初始化后对其他单元进行排序,所以,当客户端需要通过仅由该服务本身创建的IPC通道(而非由systemd创建的套接字或D-bus之类)连接到该服务的时候,simple类型并不是最佳选择。在这种情况下, notify或dbus(该服务必须提供D-Bus接口)才是最佳选择, 因为这两种类型都允许服务进程精确的安排何时算是服务启动成功、何时可以继续启动后继单元。notify类型需要服务进程明确使用sd_notify()函数或类似的API,否则,可以使用forking作为替代(它支持传统的UNIX服务启动协议)。最后,如果能够确保服务进程调用成功、服务进程自身不做或只做很少的初始化工作(且不大可能初始化失败),那么exec将是最佳选择。注意,因为使用任何 simple 之外的类型都需要等待服务完成初始化,所以可能会减慢系统启动速度。 因此,应该尽可能避免使用 simple 之外的类型(除非必须)。另外,也不建议对长时间持续运行的服务使用 idle 或 oneshot 类型。
Type=forking
#EnvironmentFile指定当前服务的环境参数文件。该文件内部的key=value键值对,可以用$key的形式,在当前配置文件中获取。
EnvironmentFile=/etc/nginx/nginx.conf
#启动命令
#ExecStart指定启动进程时执行的命令。
#ExecReload指定当该服务被要求重新载入配置时所执行的命令。另外,还有一个特殊的环境变量 $MAINPID 可用于表示主进程的PID,例如可以这样使用:/bin/kill -HUP $MAINPID。强烈建议将 ExecReload= 设为一个能够确保重新加载配置文件的操作同步完成的命令行。
#ExecStop指定停止服务时执行的命令。
#ExecStartPre指定启动服务之前执行的命令。不常用。
#ExecStartPost指定启动服务之后执行的命令。不常用。
#ExecStopPost指定停止服务之后执行的命令。不常用。
ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s quit
#设为 true表示在进程的文件系统名字空间中挂载私有的 /tmp 与 /var/tmp 目录, 也就是不与名字空间外的其他进程共享临时目录。 这样做会增加进程的临时文件安全性,但同时也让进程之间无法通过 /tmp 或 /var/tmp 目录进行通信。
#适用于web系统服务,不适用于mysql之类的数据库用户服务,数据库用户服务设为false。
PrivateTmp=true
#[Install]部分:指定服务的启用信息,只有在systemctl的enable与disable命令在启用/停用单元时才会使用此部分。
[Install]
#“WantedBy=multi-user.target”表示当系统以多用户方式(默认的运行级别)启动时,这个服务需要被自动运行。
WantedBy=multi-user.target
4)关于prometheus加入自启动,启动失败故障处理
执行:报错如下:
调试报错如下:
/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle --web.enable-admin-api --storage.tsdb.path=/home/software/prometheus-data
ts=2022-05-23T10:19:07.519Z caller=main.go:447 level=error msg="Error loading config (--config.file=/usr/local/prometheus/prometheus.yml)" file=/usr/local/prometheus/prometheus.yml err="parsing YAML file /usr/local/prometheus/prometheus.yml: yaml: unmarshal errors:\n line 27: field scrape_configs already set in type config.plain"

注意:prometheus自带的工具promtool检查配置文件。可使用./promtool检查配置是否正确,更多配置请参看官方Configuration。执行:
./promtool check config prometheus.yml
检查prometheus的配置文件中监控组配置scrape_configs,发现存在多个scrape_configs,注释掉多余的,只保留一个即可。再启动之前手动执行prometheus启动正常,可看到启动成功的提示:
caller=main.go:930 level=info msg="Server is ready to receive web requests
再次执行启动prometheus,却依然报错:
$ systemctl start prometheus
$ systemctl status prometheus //报错如下
● prometheus.service - prometheus
Loaded: loaded (/usr/lib/systemd/system/prometheus.service; disabled; vendor preset: disabled)
Active: failed (Result: start-limit) since Mon 2022-05-23 18:28:28 CST; 3s ago
Docs: https://prometheus.io/docs/introduction/overview/
Process: 31559 ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle --web.enable-admin-api --storage.tsdb.path=/home/software/prometheus-data (code=exited, status=2)
Main PID: 31559 (code=exited, status=2)
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: Unit prometheus.service entered failed state.
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: prometheus.service failed.
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: prometheus.service holdoff time over, scheduling restart.
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: start request repeated too quickly for prometheus.service
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: Failed to start prometheus.
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: Unit prometheus.service entered failed state.
May 23 18:28:28 2-bc-hb-56-centos7 systemd[1]: prometheus.service failed.
$ journalctl -xe //报错额如下
May 23 19:02:48 2-bc-hb-56-centos7 systemd[1]: Starting prometheus...
-- Subject: Unit prometheus.service has begun start-up
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit prometheus.service has begun starting up.
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:488 level=info msg="No time or size retention was set
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:525 level=info msg="Starting Prometheus" version="(ve
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:530 level=info build_context="(go=go1.18.1, user=root
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:531 level=info host_details="(Linux 3.10.0-862.el7.x8
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:532 level=info fd_limits="(soft=1024, hard=4096)"
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.036Z caller=main.go:533 level=info vm_limits="(soft=unlimited, hard=unlim
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: ts=2022-05-23T11:02:49.037Z caller=query_logger.go:90 level=error component=activeQueryTracker m
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: panic: Unable to create mmap-ed active query log
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: goroutine 1 [running]:
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: github.com/prometheus/prometheus/promql.NewActiveQueryTracker({0x7ffff76d5f23, 0x1e}, 0x14, {0x3
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: /app/promql/query_logger.go:120 +0x3d5
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: main.main()
May 23 19:02:49 2-bc-hb-56-centos7 prometheus[3790]: /app/cmd/prometheus/main.go:587 +0x61bf
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: prometheus.service: main process exited, code=exited, status=2/INVALIDARGUMENT
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: Unit prometheus.service entered failed state.
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: prometheus.service failed.
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: prometheus.service holdoff time over, scheduling restart.
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: start request repeated too quickly for prometheus.service
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: Failed to start prometheus.
-- Subject: Unit prometheus.service has failed
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit prometheus.service has failed.
--
-- The result is failed.
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: Unit prometheus.service entered failed state.
May 23 19:02:49 2-bc-hb-56-centos7 systemd[1]: prometheus.service failed.
#授权
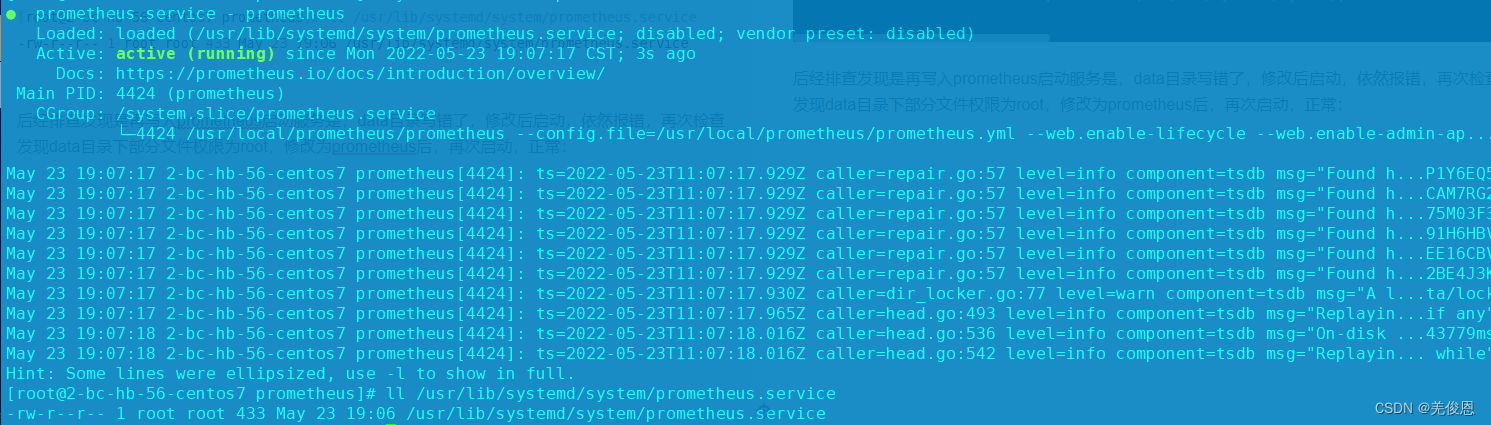
chown prometheus.prometheus -R ./data/
systemctl status prometheus
● prometheus.service - prometheus
Loaded: loaded (/usr/lib/systemd/system/prometheus.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2022-05-23 19:07:17 CST; 3s ago
Docs: https://prometheus.io/docs/introduction/overview/
Main PID: 4424 (prometheus)
CGroup: /system.slice/prometheus.service
└─4424 /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle --web.enable-admin-ap...
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...P1Y6EQ5
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...CAM7RG2
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...75M03F3
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...91H6HBV
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...EE16CBV
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.929Z caller=repair.go:57 level=info component=tsdb msg="Found h...2BE4J3K
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.930Z caller=dir_locker.go:77 level=warn component=tsdb msg="A l...ta/lock
May 23 19:07:17 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:17.965Z caller=head.go:493 level=info component=tsdb msg="Replayin...if any"
May 23 19:07:18 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:18.016Z caller=head.go:536 level=info component=tsdb msg="On-disk ...43779ms
May 23 19:07:18 2-bc-hb-56-centos7 prometheus[4424]: ts=2022-05-23T11:07:18.016Z caller=head.go:542 level=info component=tsdb msg="Replayin... while"
Hint: Some lines were ellipsized, use -l to show in full.
[root@2-bc-hb-56-centos7 prometheus]# ll /usr/lib/systemd/system/prometheus.service
-rw-r--r-- 1 root root 433 May 23 19:06 /usr/lib/systemd/system/prometheus.service
后经排查发现是再写入prometheus启动服务是,data目录写错了,修改后启动,依然报错,再次检查发现data目录下部分文件权限为root,修改为prometheus后,再次启动,正常: