CUDA开发流程解析
CUDA编程
CUDA是Nvidia公司推出的使用GPU进行通用计算的并行计算平台和编程模型。在进行CUDA编程之前,我们需要先了解一些软件栈和编译链的基础知识。
一、CUDA软件栈
CUDA软件栈分为以下四层,最下面是内核态的GPU驱动程序,其次是用户态的驱动程序,上面是CUDA运行时,是基于用户态驱动的API实现的,再上面是CUDA运行时,是基于CUDA用户态API实现的,最上面是CUDA工具库,主要是基于CUDA运行时API实现的,例如cuBlas,cuDnn等。
参考文献链接
https://mp.weixin.qq.com/s/PT05zdRosN3hktHe9X9hiA
https://mp.weixin.qq.com/s/Dgw3Rqu-Nh5pRJALQkVBDA

二、CUDA编译链
cuda应用程序通常包含C++ host代码和GPU device函数,在cuda程序的编译过程中,会做两次preprecess,第一次preprocess将device函数通过nvidia编译器编译成ptx代码和cuda binary放到fatbinary文件中,第二次preprocess是host端为合成fatbinary文件做准备并且将cuda的c++扩展转换成标准c++组件,然后host compiler将host code和fatbinary联合起来编译成host的目标文件。
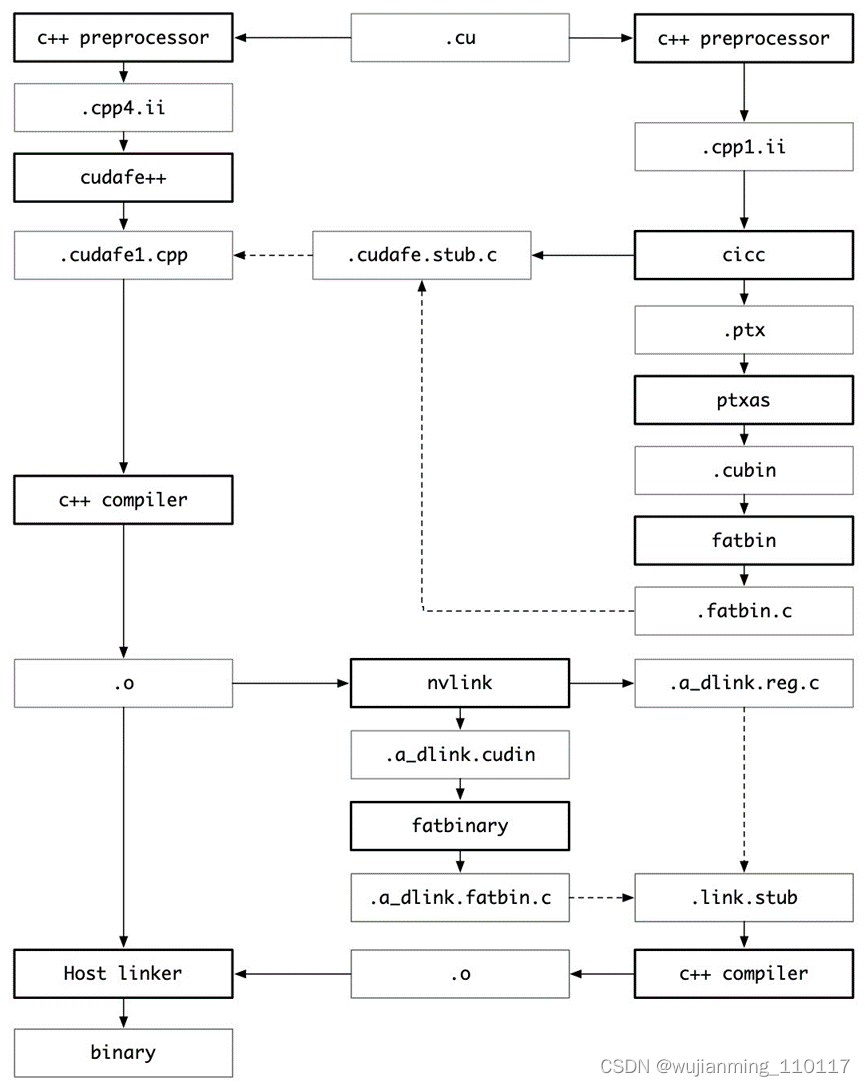
ptx(Parallel Thread eXecution)是CUDA环境中使用的汇编语言,类似CPU环境中的asm。
fat binary又叫multiarchitecture binary,是一种集成了多种指令集、可以运行在多种类型的处理器上的可执行程序。
GPU中有代(generation)的概念,不同代之间指令集不保证兼容,为了解决应用程序兼容性的问题。编译器层面上引入了两个概念,分别是虚拟架构的代(取值为compute_xy)和真实架构的代(sm_xy)。虚拟架构的不同代号是计算能力的泛化描述,跟具体的GPU型号无关,真实架构的代则跟具体的GPU型号相关。应用程序的最小虚拟代号和最小真实代号要求分别通过–gpu-architecture和–gpu_code两个参数来指定。例如
nvcc --gpu-architecture=compute_30 --gpu_code=compute_30
这个指令指定的都是虚拟代号,所以只会生成ptx中间代码,在程序运行时会通过JIT编译成目标二进制目标代码,保持程序正常运行,当然JIT也会导致在程序加载时有一定的延迟。
nvcc --gpu-architecture=compute_50 --gpu_code=compute_50,sm_50,sm_52
这个指令指定了虚拟代号,也指定了两个具体的GPU型号,所以既会生成ptx中间代码,也会生成针对sm_50和sm_52型号GPU的二进制代码(cubin)(这两个二进制会以fatbinary的形式存在)。这个程序不可以在虚拟代号低于compute_50的GPU卡上运行。
三、CUDA Docker开发环境
Docker镜像是代码开发的基础设施。使用CUDA的docker有两点条件,第一物理机上要插了GPU卡并且正确按照了GPU驱动程序,这可以通过nvidia-smi指令来确定。第二在启动镜像时挂载上GPU设备,可以通过下面的参数实现
–device=/dev/nvidiactl --device=/dev/nvidia-uvm --device=/dev/nvidia-uvm-tools --device=/dev/nvidia0
来个HelloWorld,代码文件one.cu
#include <stdio.h>
#include <cuda.h>
#include <cublas_v2.h>
#include <cuda_runtime.h>
// Host code
int main() {
int numDev = -1;
cudaError_t err = cudaGetDeviceCount(&numDev);
if (cudaSuccess != err) {
printf(“CUDA error %d, error message %s\n”, err__, cudaGetErrorString(err__));
return 1;
}
printf(“dev num = %d\n”, numDev);
return 0;
}
编译文件Makefile
NVCUDA_ROOT=/home/xxx/usr/local/cuda-10.1
one: one.cu
$(NVCUDA_ROOT)/bin/nvcc -o one one.cu -I $(NVCUDA_ROOT)/include -L ( N V C U D A R O O T ) / l i b 64 − L (NVCUDA_ROOT)/lib64 -L (NVCUDAROOT)/lib64−L(NVCUDA_ROOT)/lib64/stubs -lcuda -lcudart -lcublas
.PHONY clean:
rm -rf one
CUDA工具及其演化
















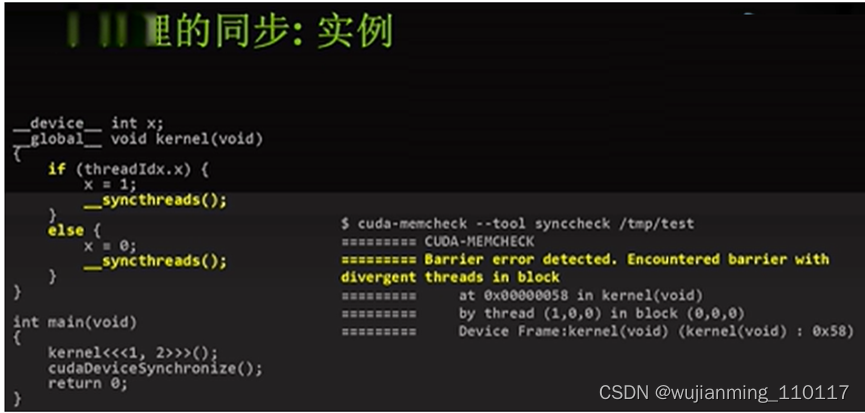
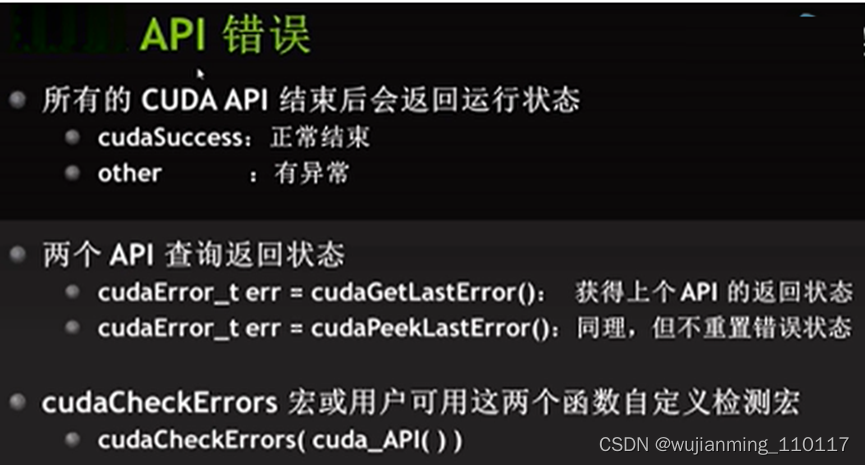













参考文献链接
https://mp.weixin.qq.com/s/PT05zdRosN3hktHe9X9hiA
https://mp.weixin.qq.com/s/Dgw3Rqu-Nh5pRJALQkVBDA