- 频率派的AB Test统计原理,基于假设检验方法步骤,样本数的估算方法
- 贝叶斯派的AB Test统计原理:观测数据->计算后验->做出决策
- 工业界AB Test流程
频率派AB测试原理
假设检验:两样本t检验
AB测试算是频率派统计学理论应用的典型体现。他基于两个基本逻辑:
-
- 抽样分布的确定(大数定理、中心极限定理、三大分布t分布、F分布、Chi方分布),使得我们可以用抽样数据估计总体的均值与方差
-
- 假设检验的方法使得可以使用反证法,用小概率事件来推翻原假设,而接受我们要检测的备择假设
因此,频率派AB测试的思想一切都围绕一个原假设出发:H0: A/B组的指标均值无差异。那接下来的检验逻辑就差不多是两样本均值检验的流程。根据原假设写出指标A-指标B均值的抽样分布->构造统计量并计算p值->根据执行区间检验。
记A、B两个总体的指标为
X1,
X2, 抽样分布和均值差的分布可以直接写出来:
X1ˉ∼N(μ1,σ12/n), X2ˉ∼N(μ2,σ22/n)X1ˉ−X2ˉ∼N(μ1,μ2, σ12/n+σ22/n)if assume μ1=μ2,X1ˉ−X2ˉ∼N(0,σ12/n+σ22/n)
至此,如果总体方差已知,我们可以直接计算统计量检验。但大多数无法得总体方差。我们此时就借助频率派关于样本标准差的一些抽样分布进行推导:
已知当变量符合正态分布时,样本标准差
S和总体方差
σ符合分布:
σ2(n−1)S2∼χ2(n−1)
我们看见左边出现了总体方差
σ, 而
N(0,σ12/n+σ22/n) 头疼的正是方差位置,很自然的想法就是左边相除,把
σ消掉:
σ/n
Xˉ−μ/σ2∗(n−1)S2(n−1)
=S/n
Xˉ−μ∼ N(0,1)/n−1χ2(n−1)
=t(n−1)
t(n−1)就是假设检验常用的t分布。可以看到左边消除掉总体方差后,右边正好符合t分布。
于是,我们关于H0的假设使用的统计量为:
t=nS12+nS22
X1ˉ−X2ˉ−μ1−μ2assume μ1=μ2, t=nS12+nS22
X1ˉ−X2ˉ
至此,频率派的AB 测试的基本统计原理与假设总结如下:
- H0:
X1ˉ−X2ˉ=0
- 在总体方差未知、假设AB总体均值相同、且符合正态分布时, 构造的统计量为
t=nS12+nS22
X1ˉ−X2ˉ
- 按照置信区间
X1ˉ−X2ˉ± t2ασ12/n+σ22/n
检验
继续放宽条件,z检验
当然上述流程是基于两总体方差不同的假设
σ1=σ2. 如果我们继续放宽这一假设,使得两总体的方差、均值均相同。我们就可以直接使用
z 检验。也可以认为,当样本量继续放大时,样本标准差对方差的估计与总体误差越小,可以代替,直接可以用样本标准差计算z分数。z检验的置信区间:
X1ˉ−X2ˉ±z2α⋆σ12/n+σ22/n
下表基本涵盖了两样本均值检验的所有情形,除了AB测试外其他检验问题也适用。

如何确定测试所需的样本量?
频率派的AB测试借用假设检验的统计功效(Statistical Power)概念来估算要达到一定功效所需的样本量。下图是 假设检验两类错误的经典示意图:
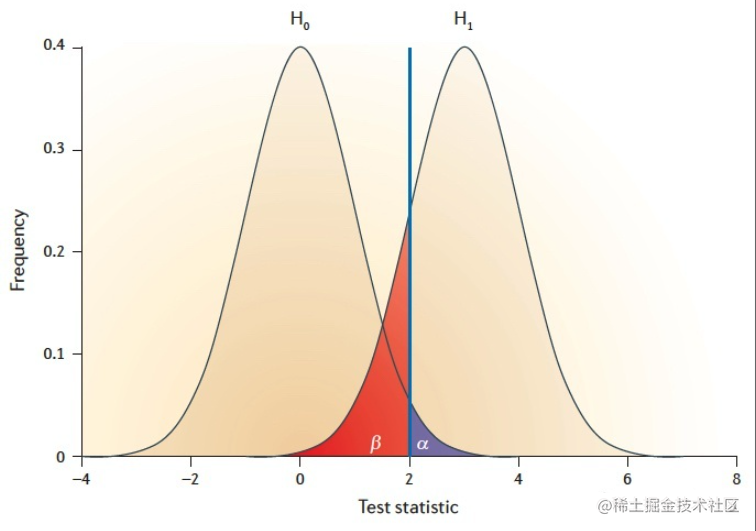
β部分即为我们错误地接受了原假设H0所犯的错误(第二类错误)。而不犯这个错误的概率
1−β就是这里两样本检验定义的统计功效。计算如下:
1−β=Φ(z−z1−α/2+Φ(−z−z1−α/2))z=σ^2/n
X1ˉ−X2ˉ
可见是由z分数计算而来的。这样输入我们期望的功效,得出所需的样本数。
贝叶斯派AB测试原理
贝叶斯方法的优势
频率派的AB测试有些缺点,例如他基于观测数据只能给出零假设反例的证据,无法给出接受备择假设的证据。也无法给出两个实验究竟孰优孰劣的证据。而贝叶斯的AB检验流程更加清晰明了[5]: 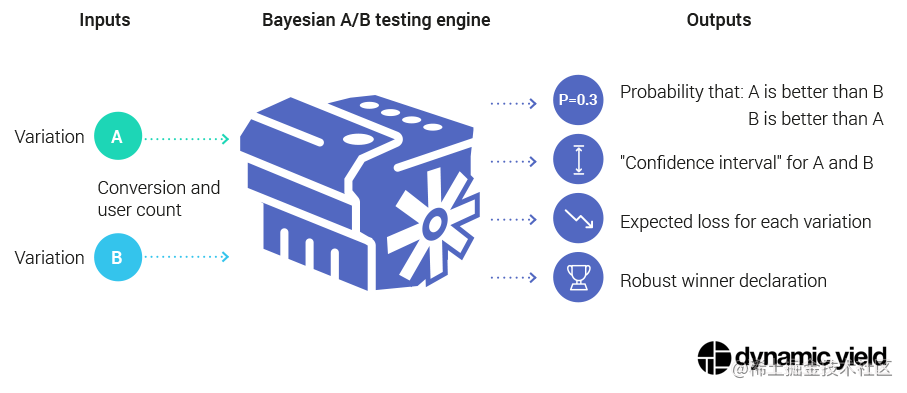
贝叶斯AB测试可以直接给出AB两个实验参数谁更优秀的结论。同频率派一样,贝叶斯AB测试也将贝叶斯统计的核心理论展现地淋漓尽致。
贝叶斯原理
这里假定大家对贝叶斯统计较为熟悉了。与频率派最大的区别在于贝叶斯统计认为参数是以概率分布的形式存在的,不是确定的。而贝叶斯定理就是用来在观测到新数据时正确地更新这些概率以降低我们对参数概率的不确定性。
贝叶斯统计围绕先验(prior), 似然(likelyhood),后验(posterior)和证据(观测,evidence)展开:
P(H∣d)=P(d)P(H)P(d∣H)
其中,
P(H∣d)是贝叶斯统计要得到的核心结论,参数的后验概率。这个参数H可以是我们对群体的参数估计,也可以是对参数的一些假设。
P(d) 的计算是贝特斯统计的核心挑战,他只能用积分计算精确:
P(d)=∫P(H∣d)P(H)dH。
贝叶斯AB测试
回到本文主题AB测试来,我们希望直接得到AB两个群体指标的后验分布,或者差值的后验分布。以线上的转化率(conversion)为例,贝叶斯AB测试的步骤为:
-
1. 确定似然的分布
转化率的分布看做A,B两个群体用户是否进行了某项转化行为,0代表无,1代表有这种行为。因此AB的转化行为是符合转化率
pA,pB的贝努力分布:
dA={0,1,0,...,1}dA∼Beinolli(NA,pA)dB∼Beinolli(NB,pB)
那么似然就可以直接写出来
P(d∣H)−P(dA,dB∣pA,pB)=P(dA∣pA)P(dB∣pB)=pAcA(1−pA)NA−cApBcB(1−pB)NB−cB
-
2. 选择参数的先验分布
参数的先验是我们对参数分布的一个初始假定。例如在转化率上,如果我们对线上的转化率一无所知,就可以假定为均匀分布。如果已经有了线上之前表现的历史经验,也可以假定为高斯分布。但为了后续计算方便,贝叶斯统计建议我们选择似然分布的共轭先验作为参数的先验。共轭先验与似然相乘后得到的后验分布于先验分布的数学形式一致。
例如,我们假定了AB线上转化率数据的似然是Beinoulli分布,他的共轭先验分布是Beta分布,这意味着计算出的后验也是Beta分布:
p∼Beta(α,β)=B(α,β)pα−1(1−p)β−1B(α,β)=Γ(α+β)Γ(α)Γ(β)
计算后验能推导得:
P(pA∣dA)∼Beta(α+cA,β+(NA−cA))P(pB∣dB)∼Beta(α+cB,β+(NB−cB))
-
3. 计算后验分布 上一步,如果我们选用了共轭先验,可以求出后验的解析解。但当变量多维、解析形式复杂时,我们也可以选用数值解(近似解)。后验近似解有很多种求解方法,如变分VA、MCMC。下面贴一个用PyMC3的MCMC采样求解出的转化率后验分布:
import numpy as np
import pymc3 as pm
import matplotlib.pyplot as plt
pA_true = 0.04
pB_true = 0.05
N_A = 2500
N_B = 3000
obs_A = np.random.binomial(1, pA_true, size=N_A)
obs_B = np.random.binomial(1, pB_true, size=N_B)
with pm.Model() as ab_model:
p_A = pm.Uniform('p_A', 0, 1)
p_B = pm.Uniform('p_B', 0, 1)
obs_A = pm.Bernoulli('obs_A', p_A, observed=obs_A)
osb_B = pm.Bernoulli('obs_B', p_B, observed=obs_B)
delta = pm.Deterministic('delta',p_B - p_A)
trace = pm.sample(5000)
pm.traceplot(trace)
复制代码
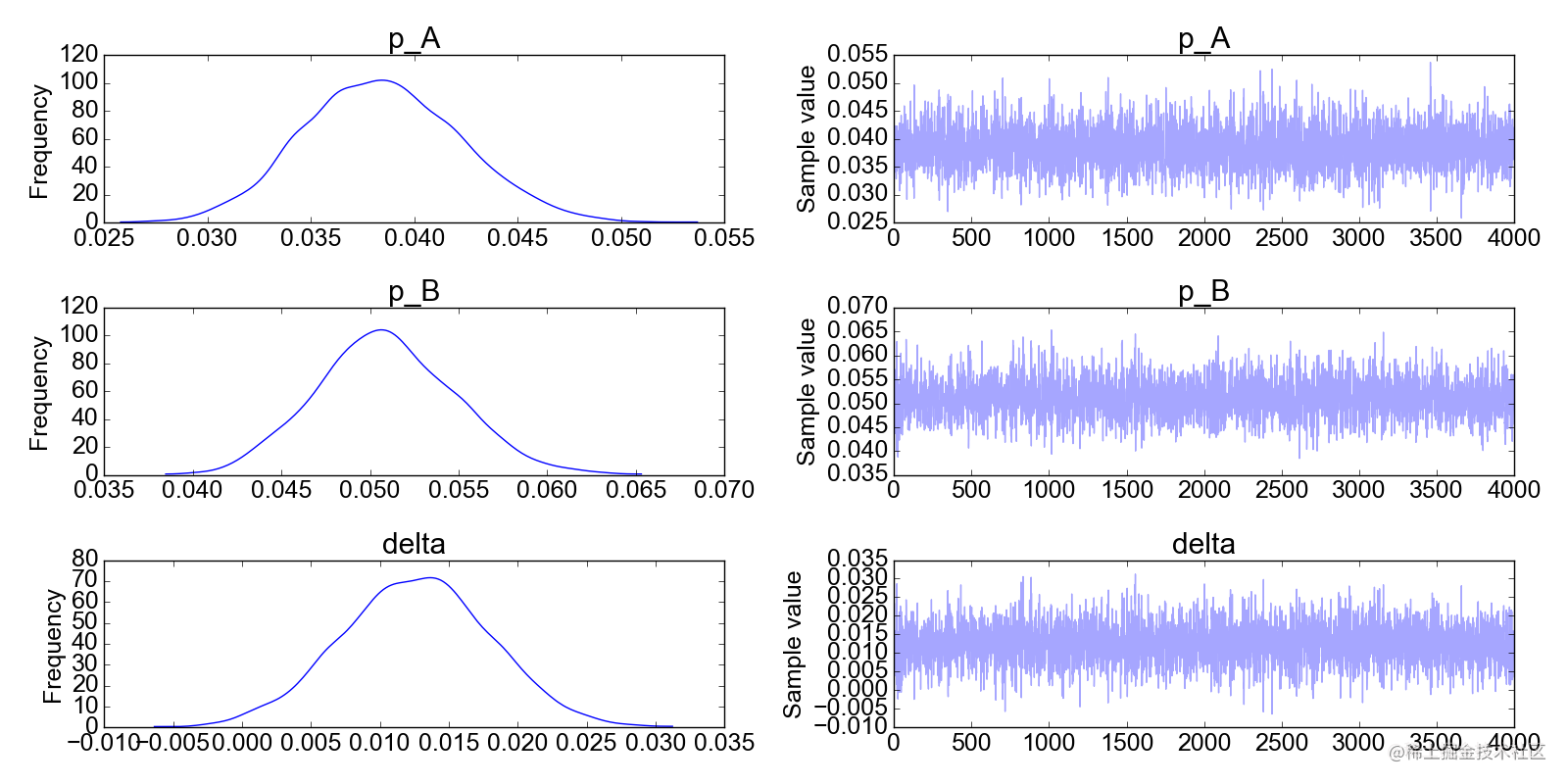
MCMC的数学细节不多叙述,只需要知道他是用一个已知能采样的分布对后验分布进行采样。且采样时能往密度函数的密集区域采样,保证了采样的高校。
复制代码
-
4. 做出决策 贝叶斯AB测试得出结论的方法没有标准范式,介绍两种常用做法。
Region Of Practical Equivalence (ROPE)[6]
首先定义一个Effective size:
σA2+σB2
μA−μB=±0.1, 这个指标的意思是,两组实验指标在10%的区域内是不能接受的(不能显著证明有结论的)。而我们拿什么跟这个Effective size比较呢?上一步我们得到了后验
P(μA−μB∣d),我们用其95%的HPD(High Posterior Density Interval)与之比较。HPD是后验分布的一个定义:
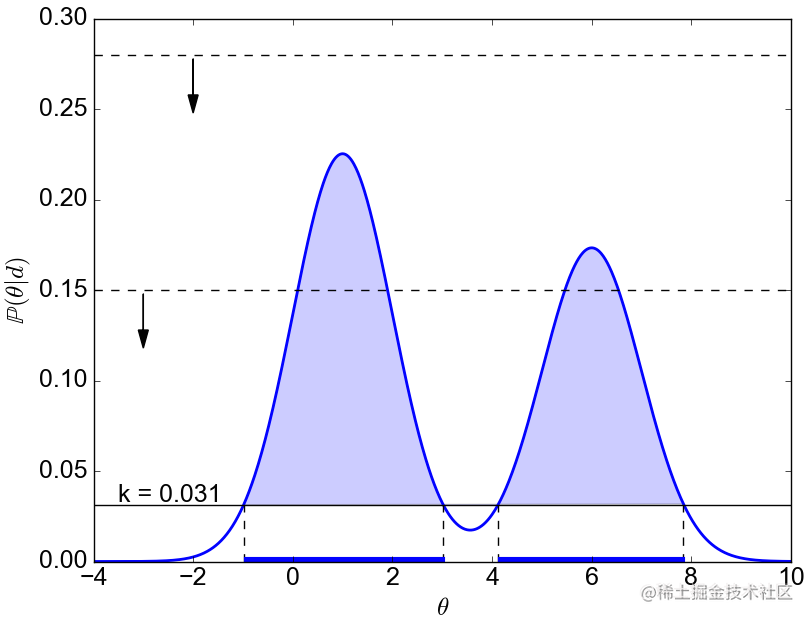
然后我们将95%-HPD与Effective size 做对比:
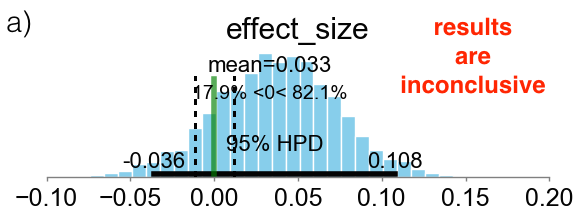
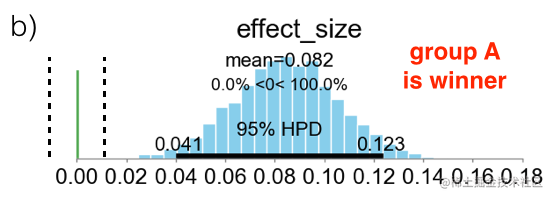
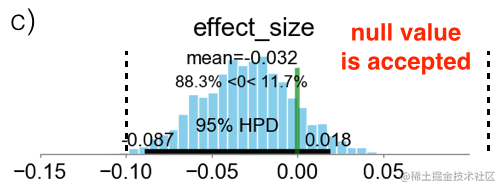
图(a)表示HPD在Effective size两侧,没有充分证据证明两组有差距;图(b)HPD完全在Effective size一侧,可以宣布某方胜利;图(c)HPD被Effective size完全包含,可以宣布两者无显著差别。
Expected Loss Method[7]
定义一个期望loss:
E(L)=min(E(LA),E(LB))E(LA)=∫01∫01max(μA−μB,0)P(μA∣dA)P(μB∣dB)dμAdμBE(LB)=∫01∫01max(μB−μA,0)P(μA∣dA)P(μB∣dB)dμAdμB
其中
E(LA)意思是如果我们宣布A胜利的loss值是多少;决策规则就是:如果
E(L)小于一个我们设定的阈值,则按照loss较小原则选择A或B胜利;如果
E(LA) 和
E(LB)都小于设定阈值,则宣布两者无差别。
工业界AB测试流程
工业界AB测试框架除了背后的统计学原理的应用,往往最重要的是流量的分层与分桶。两个对照组要尽可能地保证除了控制参数外其他的流量特征正交。可以理解为两组用户的画像一致,画像包含但不限于性别、年龄、所在城市等。
流量分桶原理 采用如下步骤将流量分配到具体模型上面去[1]:
- 把所有流量分成N个桶。
- 每个具体的流量Hash到某个桶里面去。
- 给每个模型一定的配额,也就是每个策略模型占据对应比例的流量桶。
- 所有策略模型流量配额总和为100%。
- 当流量和模型落到同一个桶的时候,该模型拥有该流量。
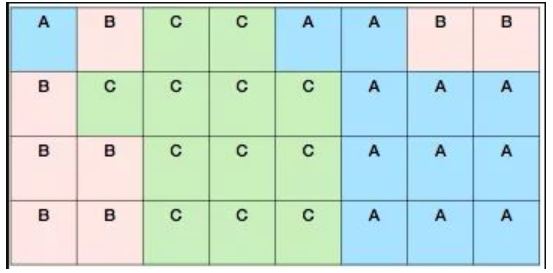
举个栗子来说,所有流量分为32个桶,A、B、C三个模型分别拥有37.5%、25%和37.5%的配额。对应的,A、B、C应该占据12、8和12个桶。为了确保模型和流量的正交性,模型和流量的Hash Key采用不同的前缀。
Reference