更多可关注
计算机视觉-Paper&Code - 知乎
Abstract
恺明出品必属精品,目前在Facebook AI Research,多的不用多说。可以说这篇17年的论文即使到现在也绝不过时,其中一些思想和实验都给人很深的启发
总结来说本文主要以下贡献
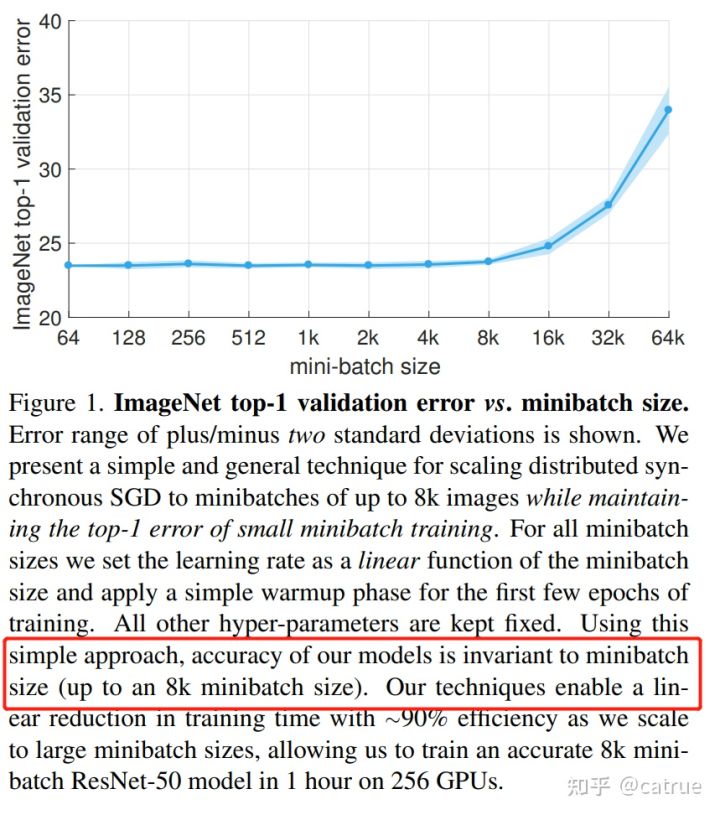
- 作者展示了256GPUS的超强财力,表明batchsize不是越大越好,达到极限16k之后learning rate,validation error都降不下来
- 提出hyper-parameter-free linear scaling rule,学习率随着ecopch增大而减少,随着batchsize增大二增大,加快模型收敛以及提高性能
- 太大的学习率又会在一开始使模型训练不稳定,因此提出warmup 方法用来解决模型前期优化的问题
Algorithm
作者写的实在比较清晰
Large Minibatch SGD
损失函数和权重更新方法如下,不过多解释。关于Batchsize作者如下观点(经验来说选用32)
- 当batch size太小的时候,在一定的epoch数里,训练出来的参数是无法逼近整体数据集定态分布的
- 当batch size太大,深度学习的优化(training loss降不下去)和泛化(generalization gap很大)都会出导致在validation 上 error 很高
- 随机梯度噪音的在深度学习中是正比于learning rate/batch size(也证明了line scale的有效率),batch size太大,噪音就太小了。其中随机梯度噪音对于逃离saddle points (优化问题)和sharp minima (反话问题)都必不可少的作用


- batchsize增加k,学习率也对应增大,每次更新时,都采用bs个样本的平均loss进行梯度更新

Warmup
- constant warmup,也就是通过手动固定设置epoch<5时的较下lr,再依次增大
- gradual warmup, 逐渐将学习率从小到大增大,到epoch=5时,达到k倍lr,k代表batchsize。之后再继续执行lr schedule这个效果很好。如图可以看到,使用warmup的training error更低

Batch Normalization
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
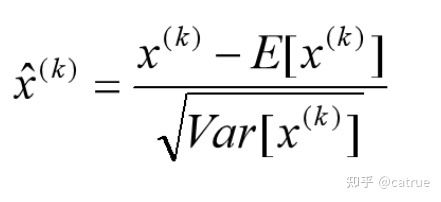
经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,加快训练收敛速度。但是这样会导致网络表达能力下降。比如说我原先学习到的是一个S型分布,但是被强制统一归一到0-1正态了。
为了防止这一点,每个神经元增加两个调节参数(scale和offset),计算得到的y作为该层的新输出,这两个参数是通过训练来学习到的,同时参加反向更新

推理的时候直接用全局统计的方差和均值,同时也可以通过融合conv+bn加速
其他方面是作者讨论分布式训练和硬件实现的内容