持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第3天,点击查看活动详情
Attention score
本节内容主要是解释什么是attention打分函数。
当然我们首先需要了解什么是attention scoring(注意力分数)。
我们之前讲通用的注意力汇聚公式如下:
f(x)=i=1∑nα(x,xi)yi
就是用
x和
xi之间的距离关系对
y进行加权。
展开得到:
α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))∈R
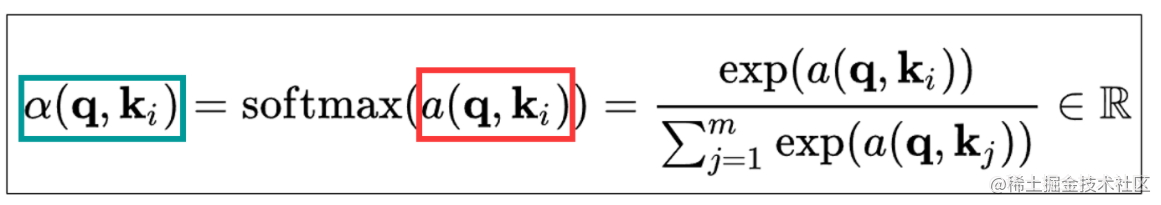
- 绿色框框里是α,对应的是注意力权重。
- 红色框框里是a,对应的是注意力分数。
也就说, 注意力分数 softmax之后变为 注意力权重 , 注意力权重 就是 注意力分数 经过softmax计算。
看一下下图: 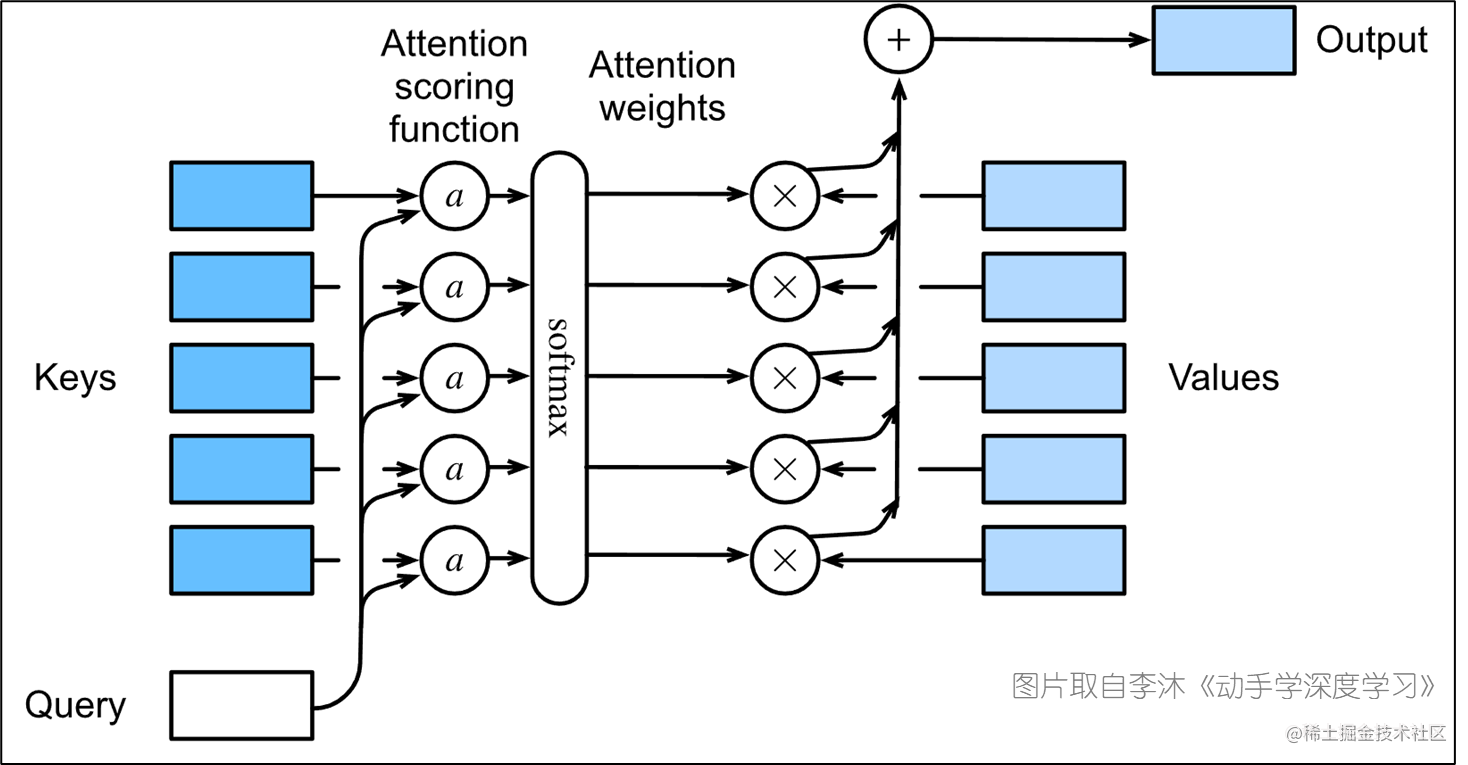
以softmax为界限,左边就是注意力分数(attention score)的计算部分,右边就转入注意力权重(attention weight)的计算了。
Attention scoring functions
我们之前在nadaraya-waston核回归之中讲过,我们选择高斯核作为计算方法。由此可知我们可以选择不同计算方法形成不同的注意力评分函数,不同的注意力评分函数会导致不同的注意力汇聚操作。这次我们介绍两种常用的注意力评分函数计算方法:
Scaled dot-product attention
之前我们在nadaraya-waston核回归key是一个向量,query是单个值。其实query也可以是一个张量的。
缩放点积注意力(scaled dot-product attention)主要就是为了处理当query也是向量的时候该如何进行计算,注意这里要求query和key长度必须相等!!!
公式如下:
a(q,k)=q⊤k/d
我们之前是使用高斯核
K(u)=2π
1exp(−2u2)来计算
x和每个
xi之间的距离也就是query和keys之间的距离,现在我们直接使用内积一步到位。
学过线代的应该都知道,从几何意义上来说,是一个向量在另一个向量上的投影;从信号处理的角度来说,内积是两个信号的相似性。因此在这里使用向量内积直接求query和key之间的距离。
此外这样计算还有一个好处,就是我们实际操作中使用mini-batch,这里可以直接将其拼接乘矩阵进行非常简单的计算即可完成整个attention weight的计算。
公式如下:
softmax(d
QK⊤)V
- 其中key和query的长度都是d
- 假设有m个query和n个key,那其中:
- query:
Q∈Rm×d
- key:
K∈Rn×d
- value:
V∈Rn×v 。
- 最终结果维度是
Rm×v
Additive attention
讲完query和key等长,再看一下不等长时候怎么办。这种加性注意力(additive attention)这种主要是应对当query和key长度不同的时候是怎么操作的。
公式如下:
现在假设query的长度为q,key的长度为k,那么
q∈Rq 和键
k∈Rk。
a(q,k)=wv⊤tanh(Wqq+Wkk)
-
可以很直观得从公式看出这里是将q和k直接扔进了一个小的神经网络里边,经过一层tanh激活函数之后得到注意力分数。
-
其中
Wq∈Rh×q、
Wk∈Rh×k,这样经过计算之后可以将结果都转化为
Rh×1。
-
经过tanh激活之后在和维度为h的
wv∈Rh进行计算,得到最终结果是一个数,维度
R1。
补充
注意上边讲的两种方法是对于一个query和key的计算,中间插的那个mini-batch的简便计算是对整体的,是把Scaled dot-product attention所有的query和key一起计算,第二部分中additive attention中没写整体计算方法。以免有人看的迷糊,特此声明。