目录
2.3.范围for遍历(其实也是依赖类中的迭代器进行遍历元素)
5.3.疑问(resize和reserve两种平台下的扩容规律)?
一、string类的默认存储字符类型:
- 1.string类是使用char(即作为它的字符类型)为默认的字符类型。

- 但是为了满足不同的需求比如说存储一个中文的字符串,我们知道英文在存储时是按照ASCII码表存储对应的数字,用数字来表示一个一个英文字符,那么其他语言一定也有一种对应的表来用数字对应相应的字符。例如中文就利用两个字节的数字对应一个中文字符。
- 我们可以看一下英文字符和中文字符在内存中的存储。
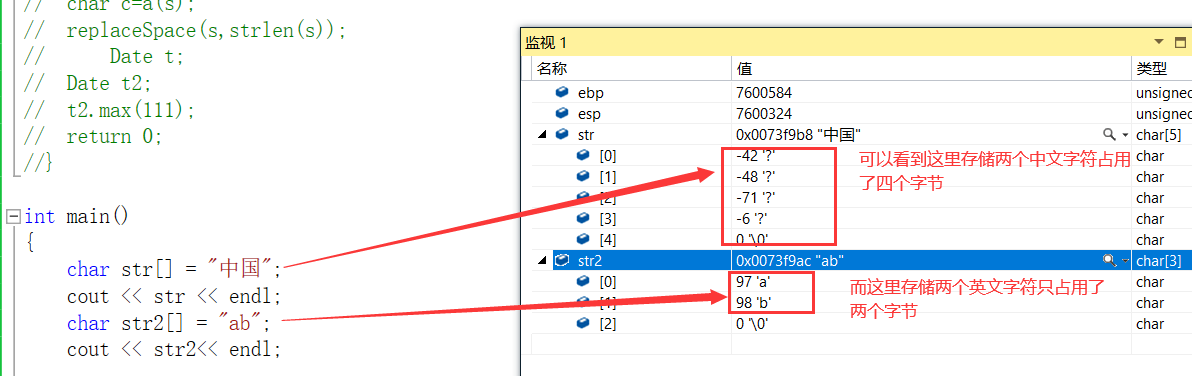
- 那么为了满足这种的需求,在C++中还有一种占两个字节的类型(宽字节Wide string)。

- 我们可以看到这种类型占两个字节

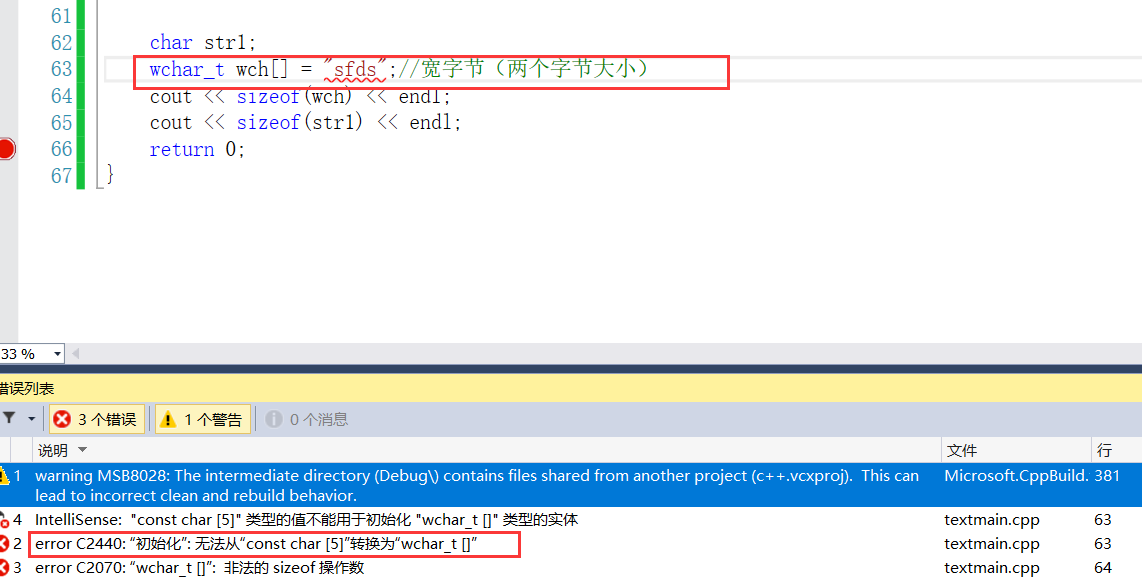
- 像宽字节这种类型我们不可以将字符串赋值给其,因为字符串类型是char*与宽字节类型不同
二、string类的使用:
-
1.创建对象

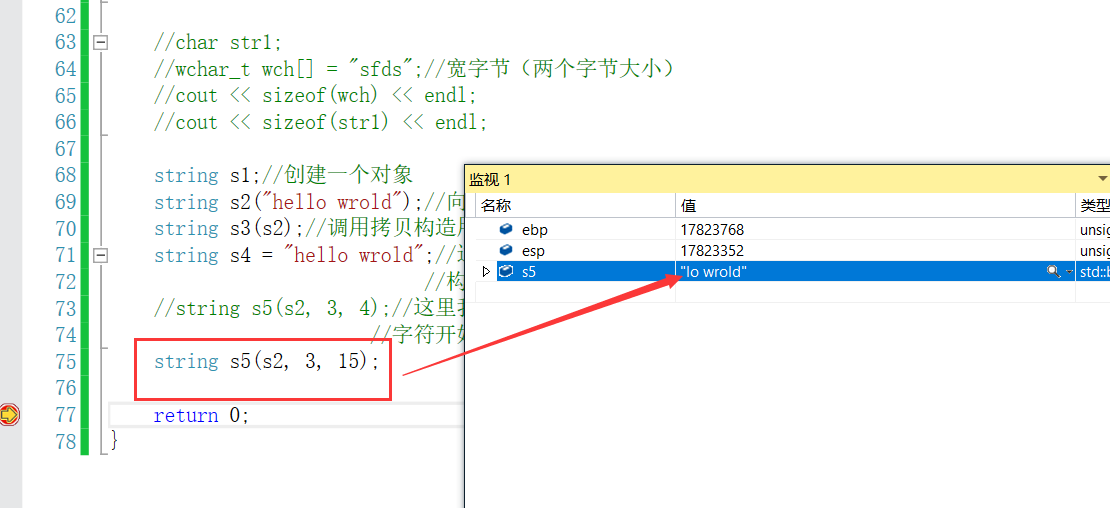
- 这这里我们对于s5这种构造方式,我们可以尝试一下将要拷贝的长度,多于字符串的长度,看看是否会报错。运行结果可以看到并没有报错,而是将3号元素下标以后的元素都拷贝到s5中。
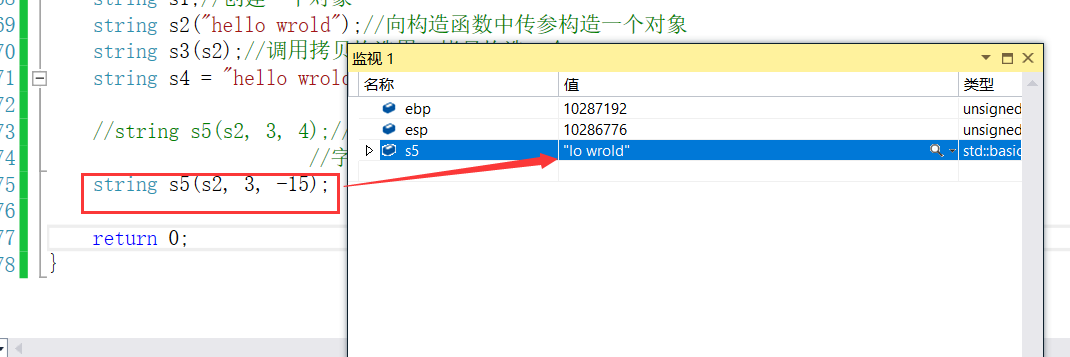
- 我们再将长度输入一个负数试一下:可以看到也将字符串全部的内容拷贝到s5中了。
- 这是为什么呢,我们可以看到三号构造函数,就是我们构造s5的方式,而它最后一个参数是一个无符号整型的参数。

- 我们可以看一下对于这个构造函数的解释,可以看到这里有个string::nops。

- 那么什么是string::nops呢?

- 这里可以看到nops其实是-1但是他是无符号整型的,在存储时是32个全1存储,但是我们取出时是按照无符号整型的形式取出来的,所以,这里取出来之后就是42多亿那就是说,我们这里要取出40多亿的数据。这肯定是不可能的,我们看他的使用,就是当参数是nops时就表示直到字符串结束。

-
2.三种遍历sting的方式:
-
2.1.for+[]的方式:

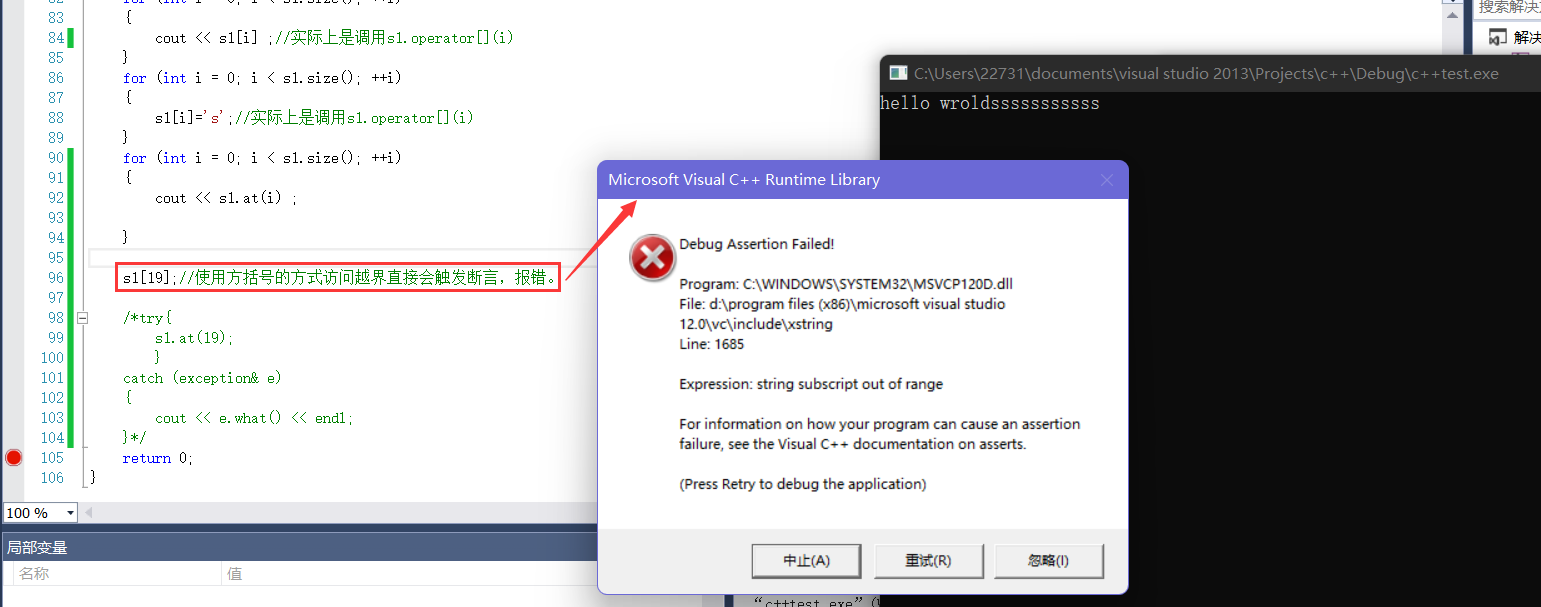
- 这里用s1.at()的方式也是可以的,与方括号的方式同理,但是我们一般还是用"[]"更加形象一点。
- 这里使用"[]"和"at"的区别在于使用方括号越界访问会直接触发断言报错,而at会抛出一个异常,我们可以捕获它。
-
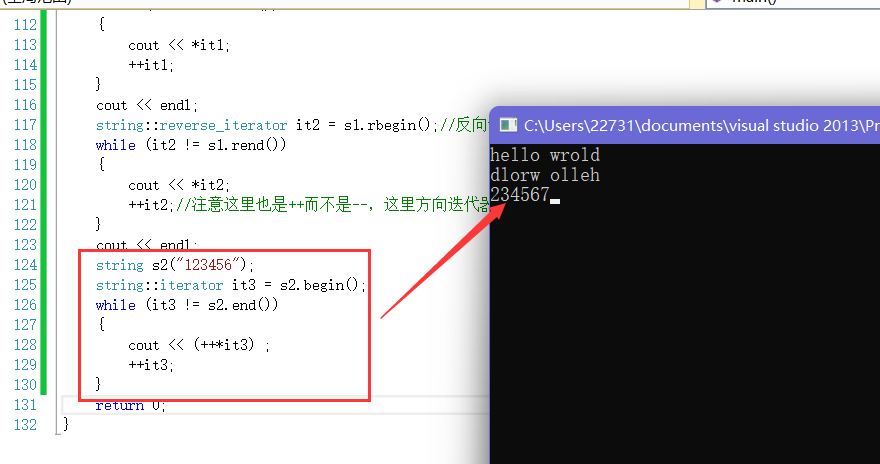
2.2.迭代器:
- 迭代器是类似于指针的东西,因为它的用法和指针是差不多的。
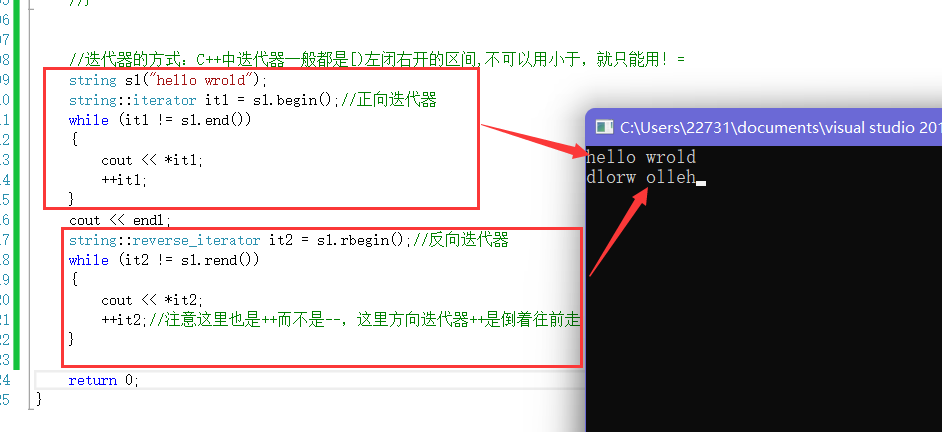
- 这里当然也可以修改串中保存的值
-
2.3.范围for遍历(其实也是依赖类中的迭代器进行遍历元素)
- 就是依次取容器中的数据,赋值给s,自动判断结束
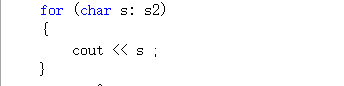
- 这里用范围for循环时不可以修改其中的值的,因为其中的s只是容器中的数据的一份拷贝。
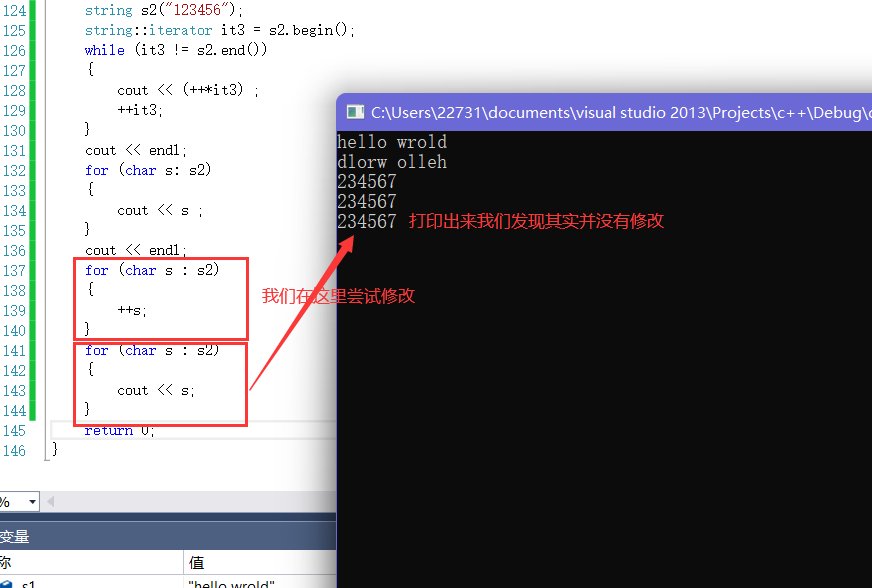
- 如果我们想要修改也是可以的,这里只要加上&让s成为容器中数据的引用即可
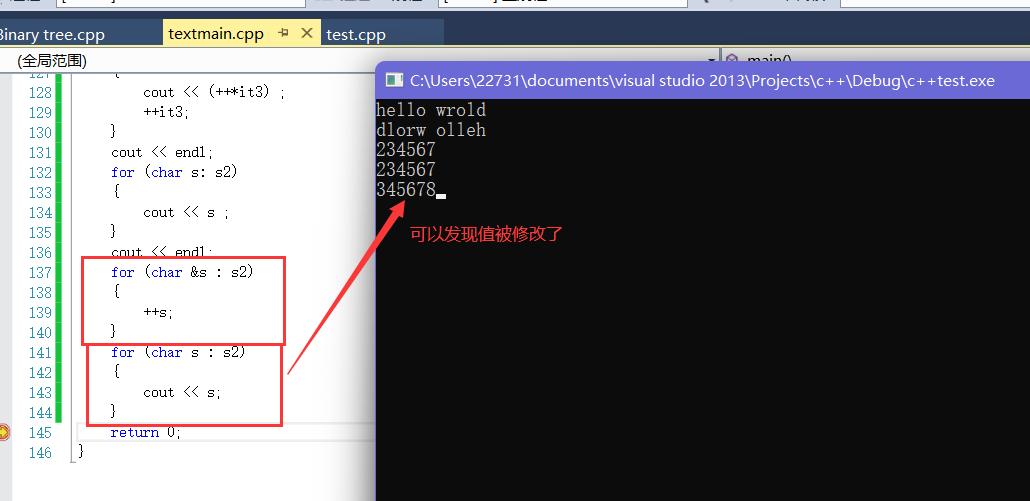
-
3.插入数据的方式:
- 1.可以调用push_back逐个字符插入
- 2.也可以调用append进行整体插入,插入一个字符串
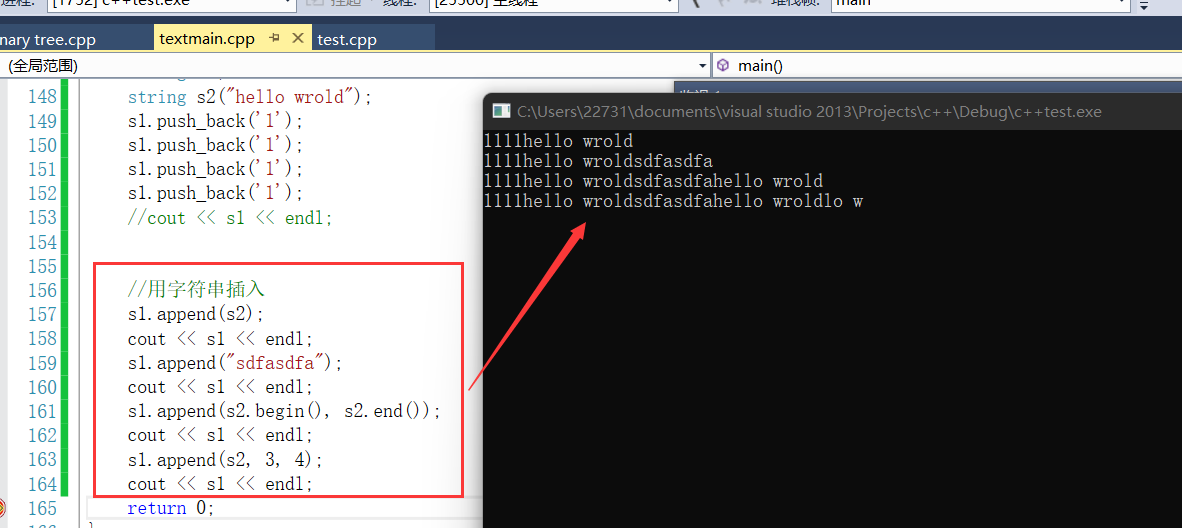
- 3.但是我们为了更直观一般都用"+="
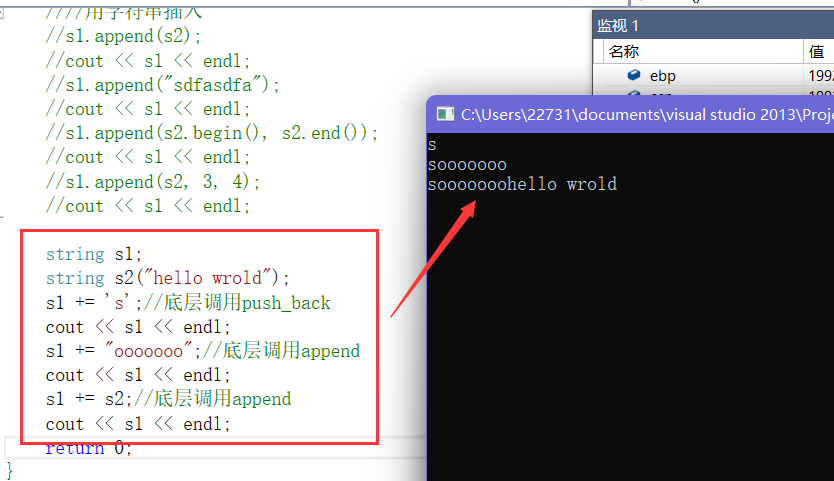
- 4.insert在任意位置插入
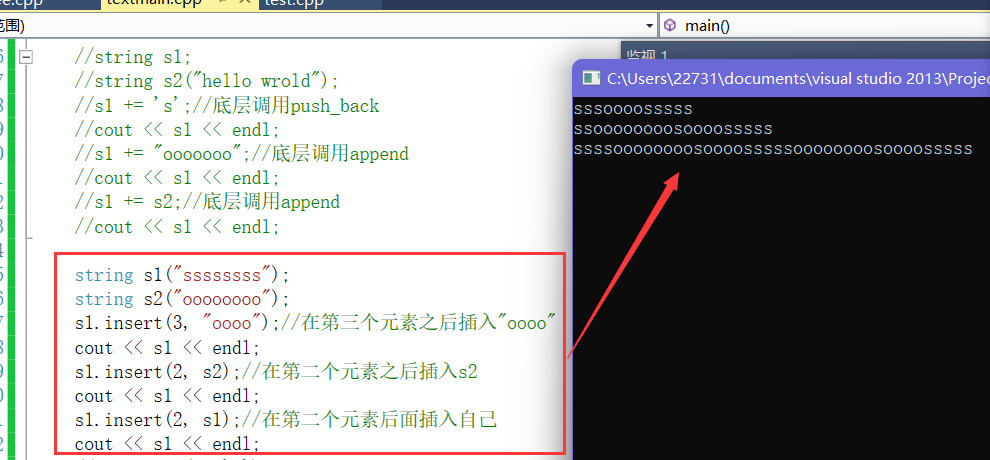
- 【使用注意】
- 1.不可以插入单个字符

- 2.插入位置不可以超出字符串范围
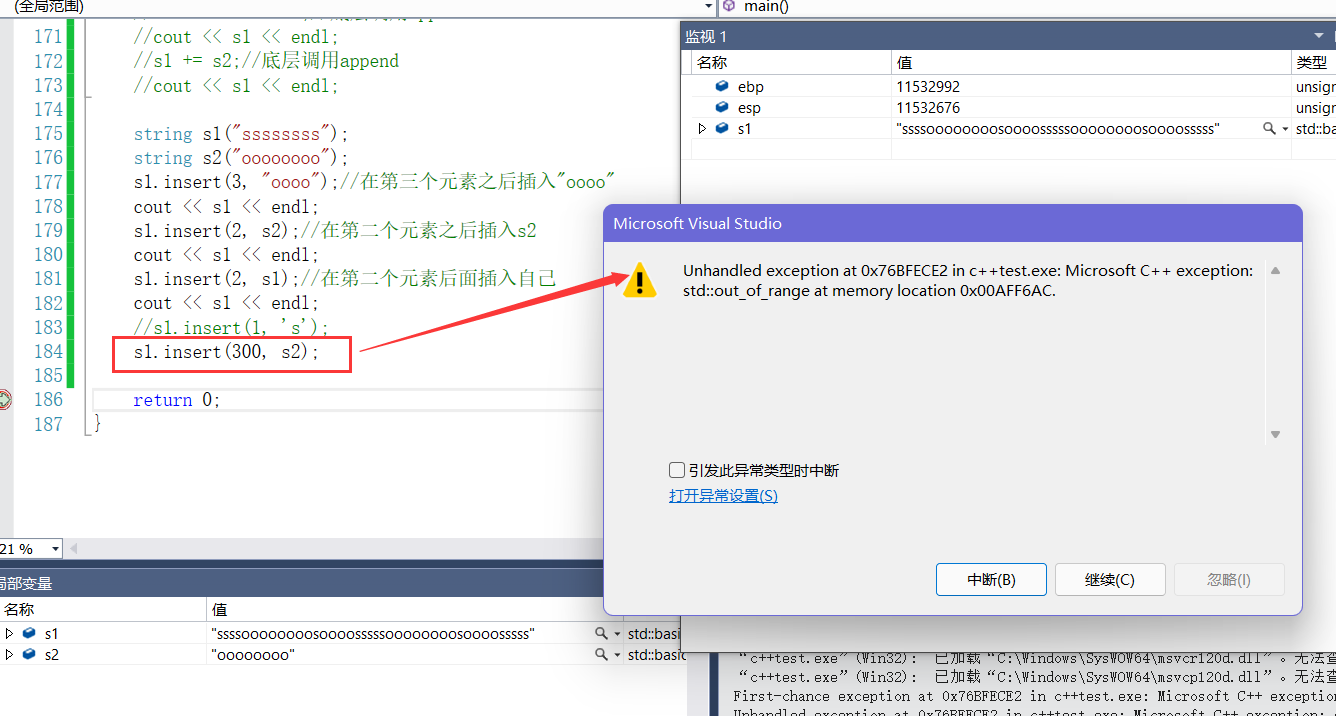
- 3.这里尽量少用insert因为底层实现是数组,头部或者中间插入需要移动元素
-
4.删除数据
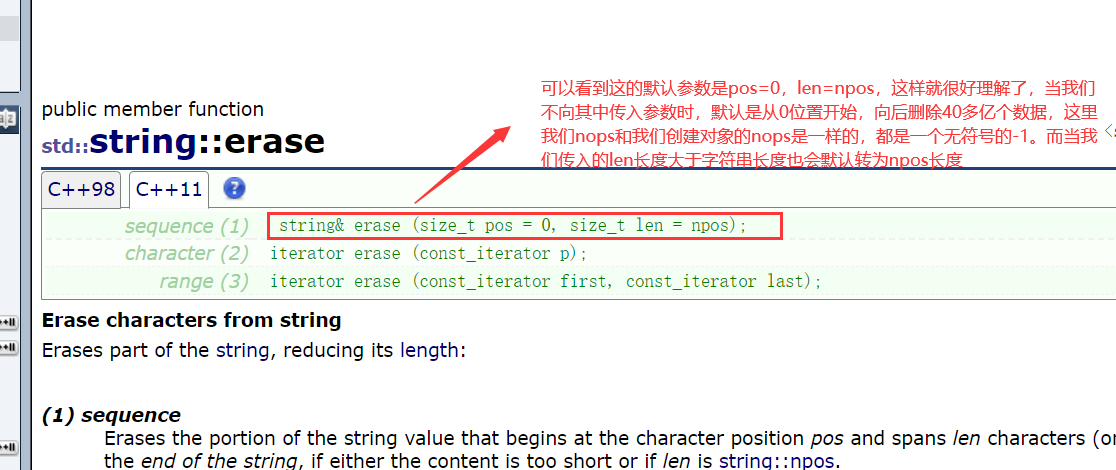
- erase
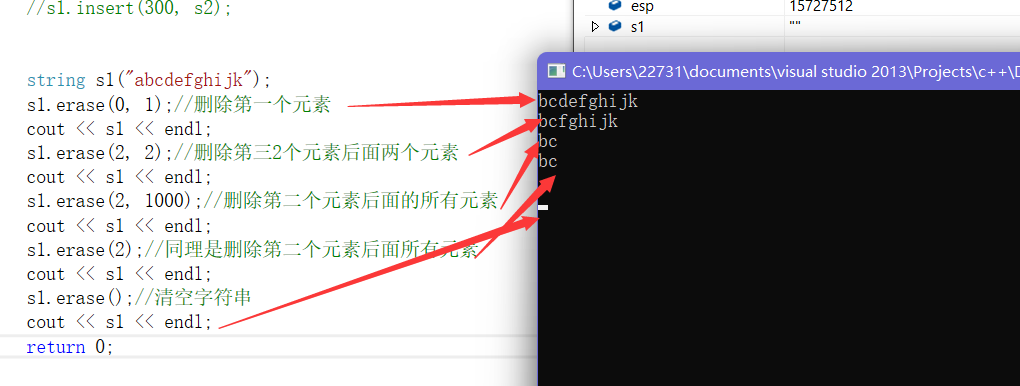
- 如何理解后面的三种传参情况呢?我们来看erase的介绍文档:
- 我们还可以用clear()清空数据

-
5.reserve和resize(扩容操作)
-
5.1.resize:
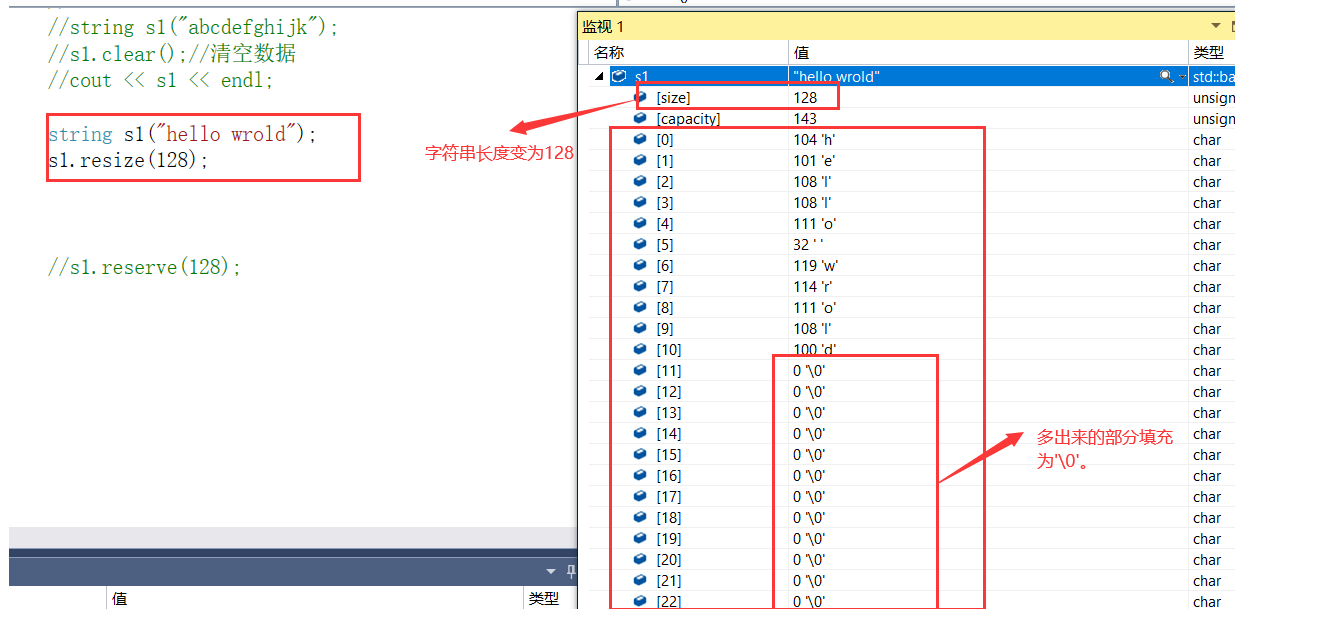
- 它有两个函数重载。

- 一个是传入一个n将字符串大小调整为n个字符的长度,然后将字符串内容保存,将多余 出来的空间填充'0'
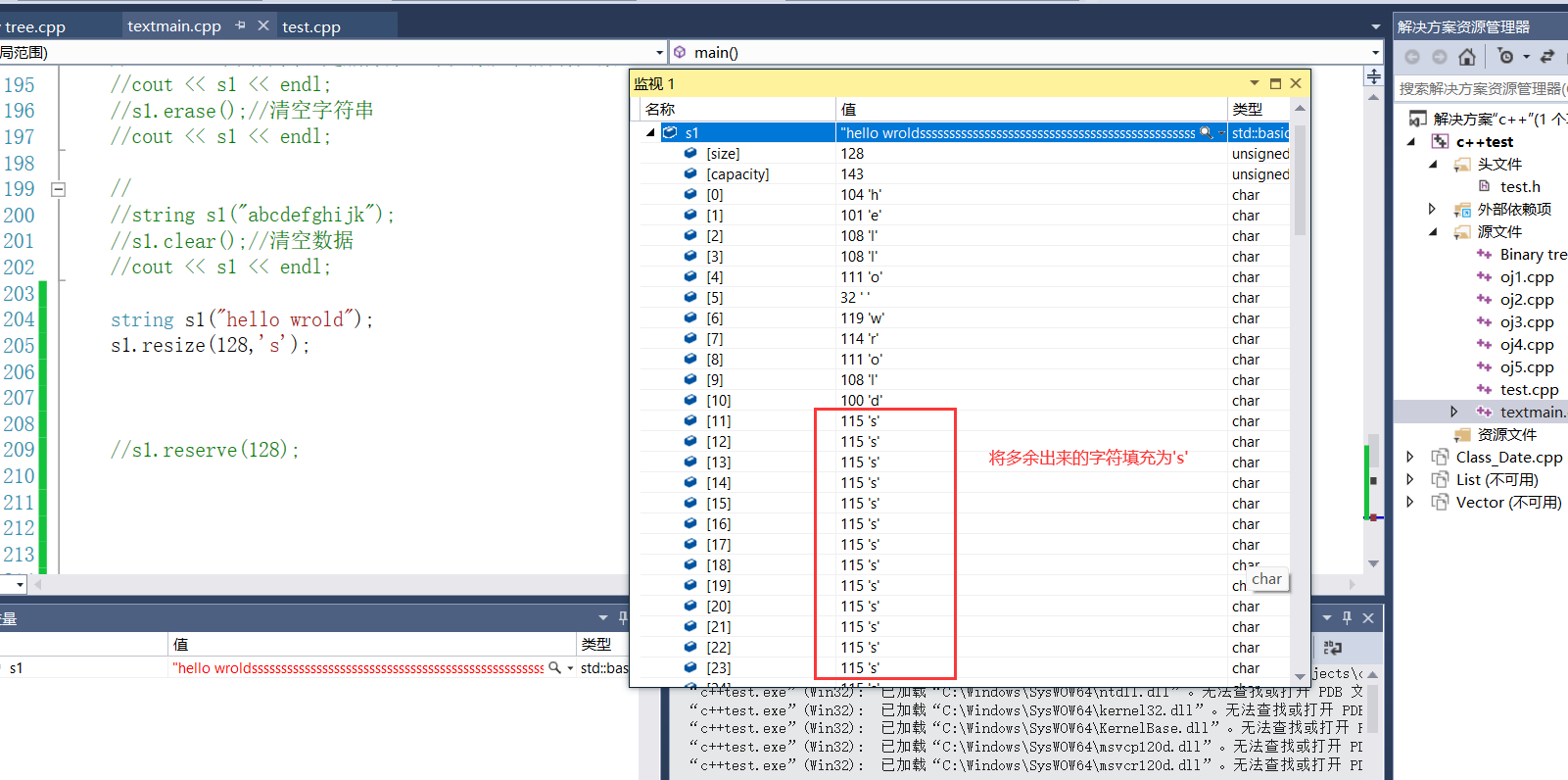
- 另一个多余出来的一个参数是要填充的字符。
-
5.2.reserve:

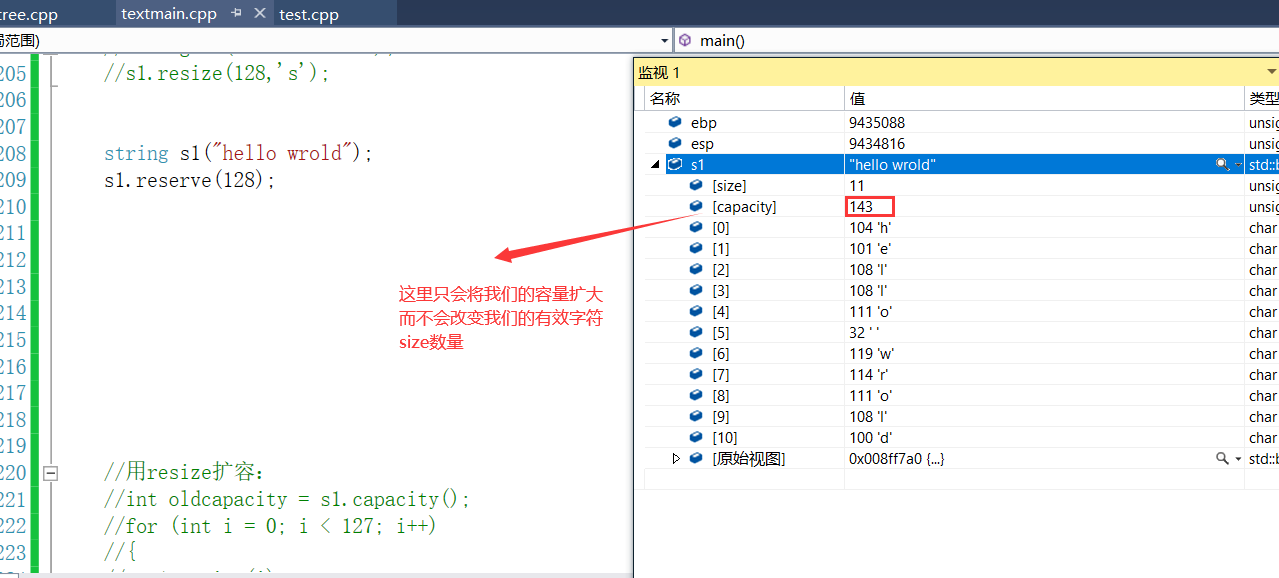
- 这里会将我们的传入128发现它只是将容量扩为143了并没将size个数改变。所以reserve只是扩容,而不改变有效元素个数。
-
5.3.疑问(resize和reserve两种平台下的扩容规律)?
- 再上面我们发现无论是resize还是reserve他们扩容时都不是按照我们所给数字大小而扩容的,这里我们就有一个疑问,那么他是咋样扩容的呢?我们会在vs平台下和g++平台下测试。
- 3.1.首先再vs下,用resize,从结果看好像毫无章法
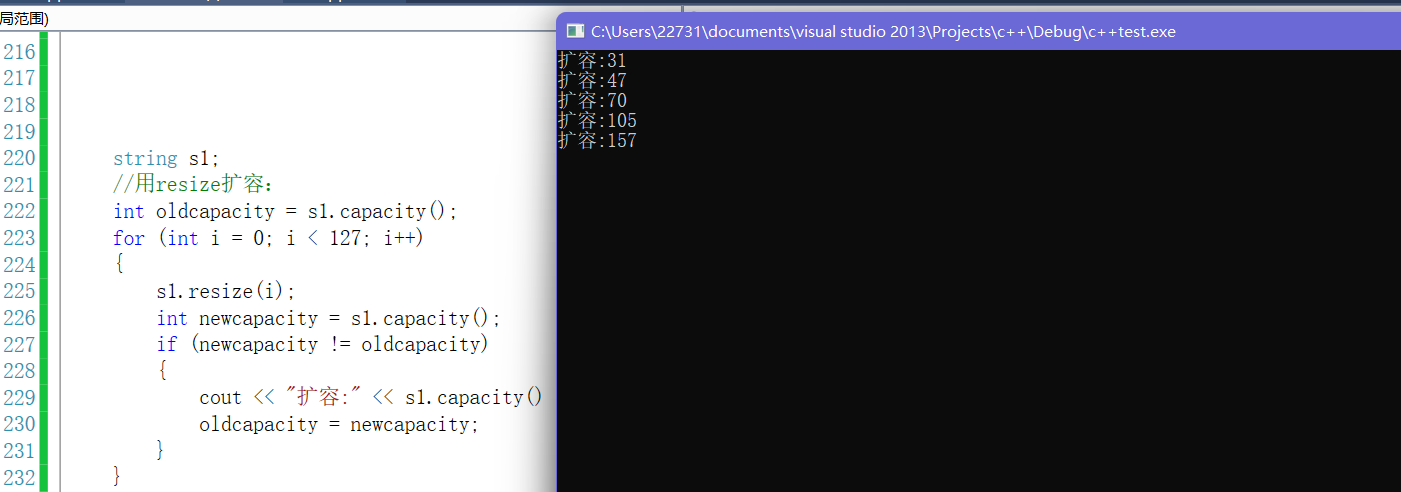
- 我们再用reserve可以发现和上面resize扩容规律一摸一样
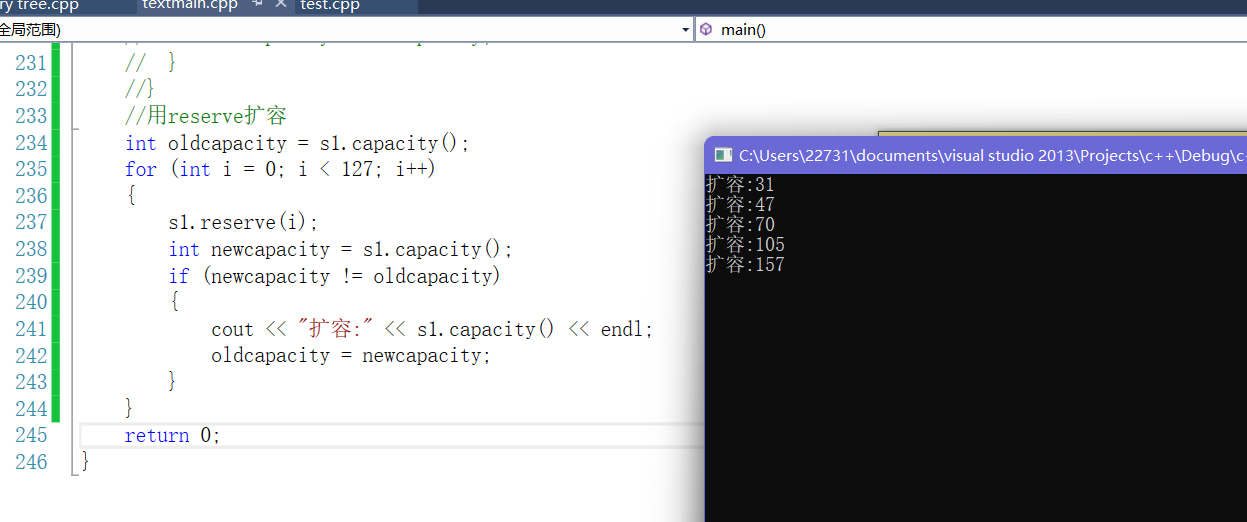
- 在g++下
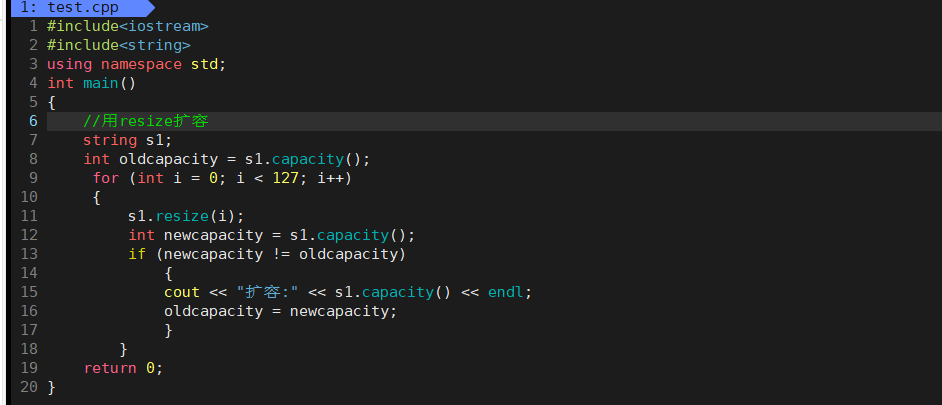
- 我们可以看到扩容是按照2的次幂扩容的。
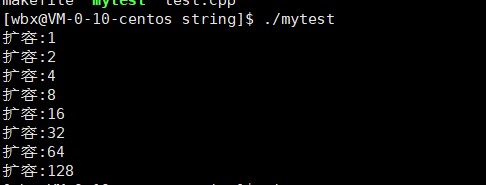
- 结论:不同的平台在实现扩容时是按照不同的方式实现的,这取决于创造编译器的人。
-
6.c_str()

- 我们可以看到上面两个同一个字符串输出不同,这是因为下面那个调用的是取出字符串数组,由于我们在用resize时在字符串后面加上了'\0'而我们,而我们在用下面的c_str()时输出时字符串遇到'\0'就会停止输出。
-
7.在字符串中找出子串
- 例如找出一个文件名的后缀:
- 第一种方式我们拷贝构造一个新的对象,内容为filename的一部分也就是它的后缀
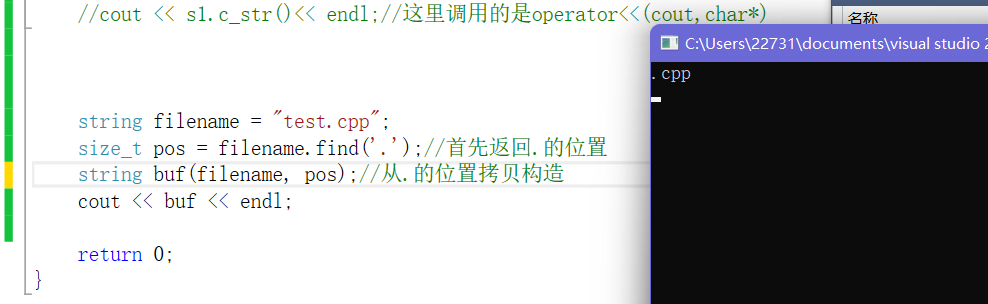
- 第二种方式我们可以用substr()

- 我们可以看到也可以找到
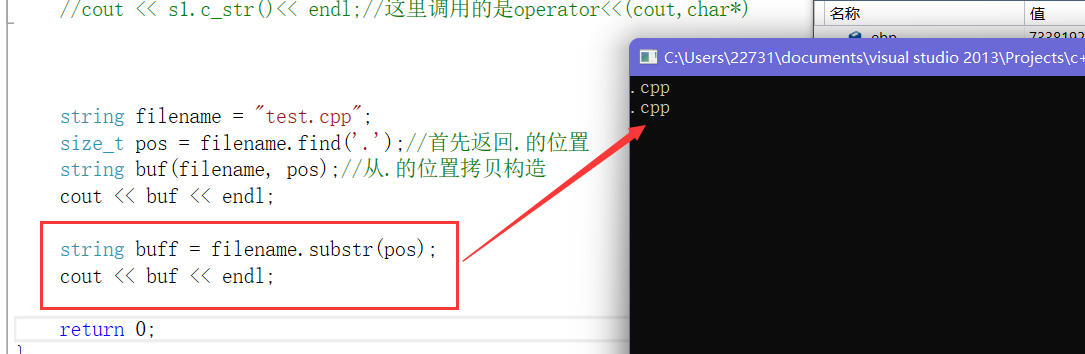
- 但是我们一般找后缀都不正着去找,一般都倒着去找。因为它有可能出现这种情况文件名为"test.cpp.zip"那这样找就会有问题后缀就会输出".cpp.zip"所以我们一般都倒着找。
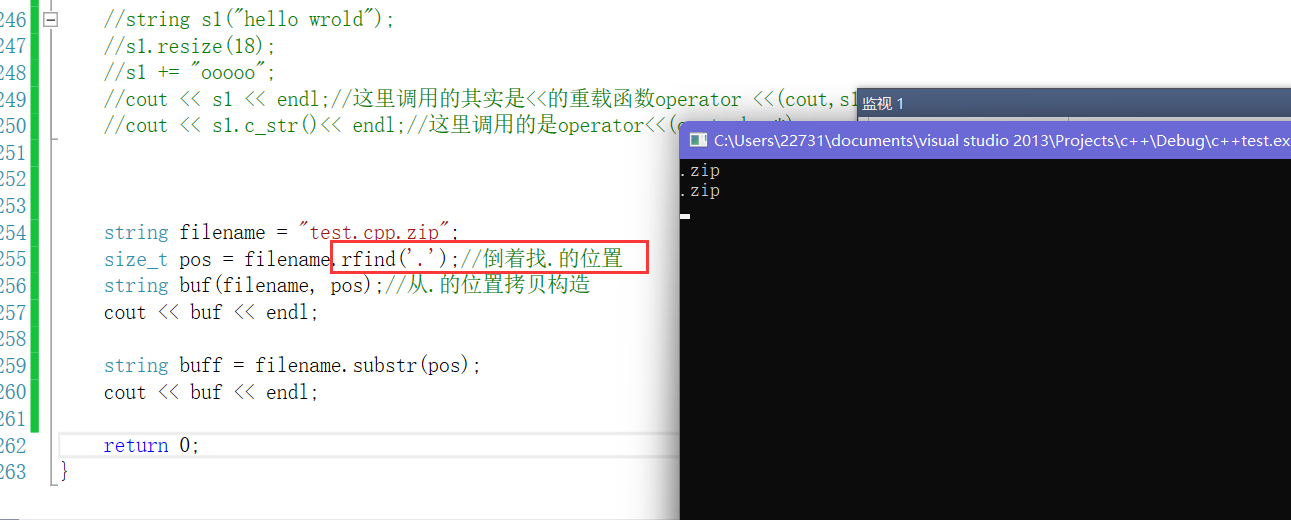
-
8.string中的迭代器失效:
-
1.什么是迭代器?
- 迭代器就是类似于指针的东西,对它操作就和对指针一样的操作方式。
-
2.为什么会迭代器失效?
- 我们先来看迭代器失效的一个场景
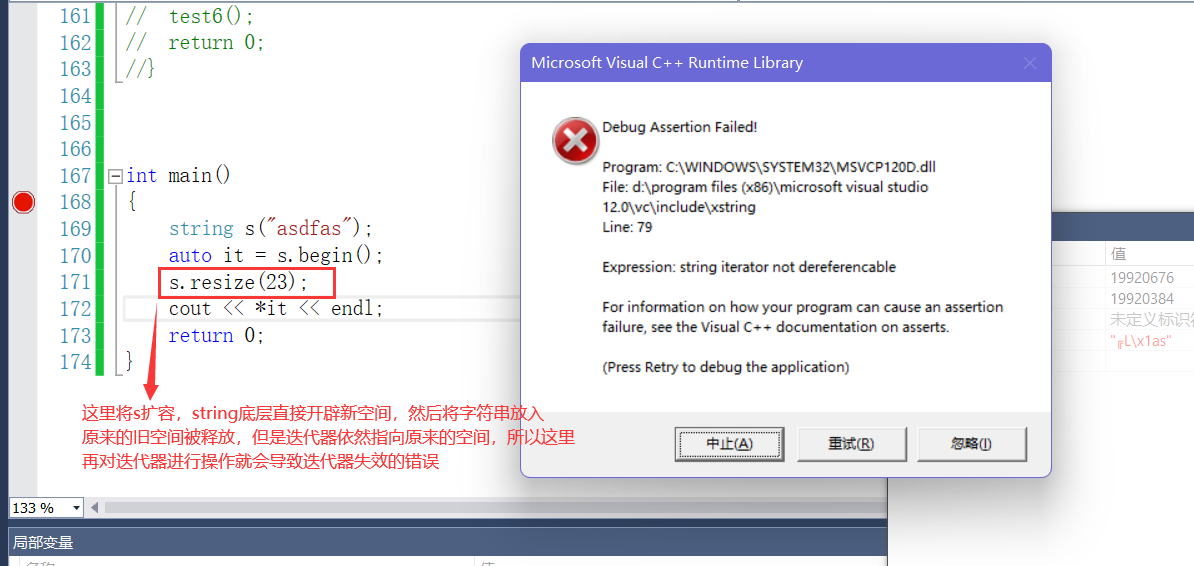
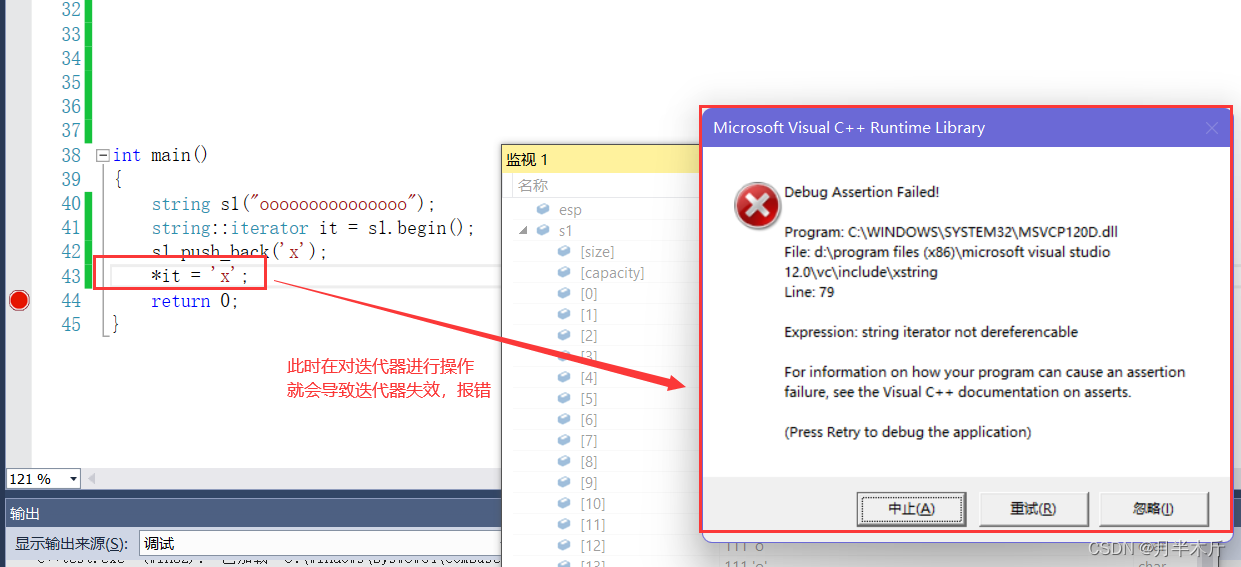
- 我们可以看到在一开始我们将迭代器创建出来,然后重新resize元素,当容器扩容后对迭代器进行解引用访问就报错了,这是因为,在进行扩容时,底层直接就将原来旧的空间释放掉,然后将内容拷贝到新开辟的空间中,将原来的指针指向新的空间,而这样迭代器的那片空间就被释放掉了,所以扩容之后再对迭代器进行操作,就有可能会导致迭代器失效问题。
- 我们先来看迭代器失效的一个场景
-
3.导致迭代器失效的一些场景
- 当push_back插入元素导致string扩容时:
-
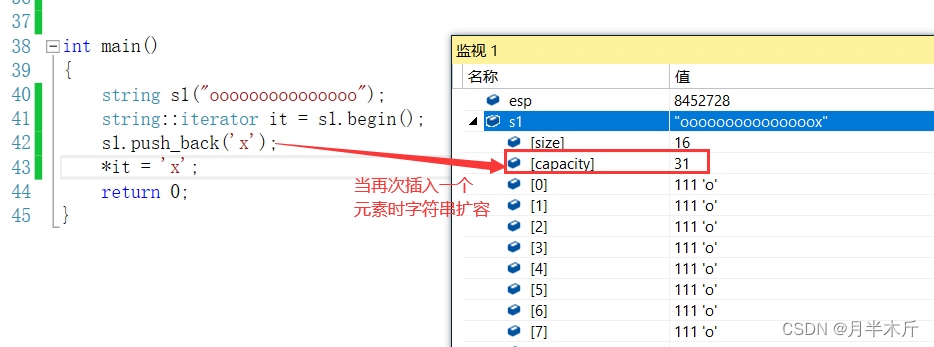
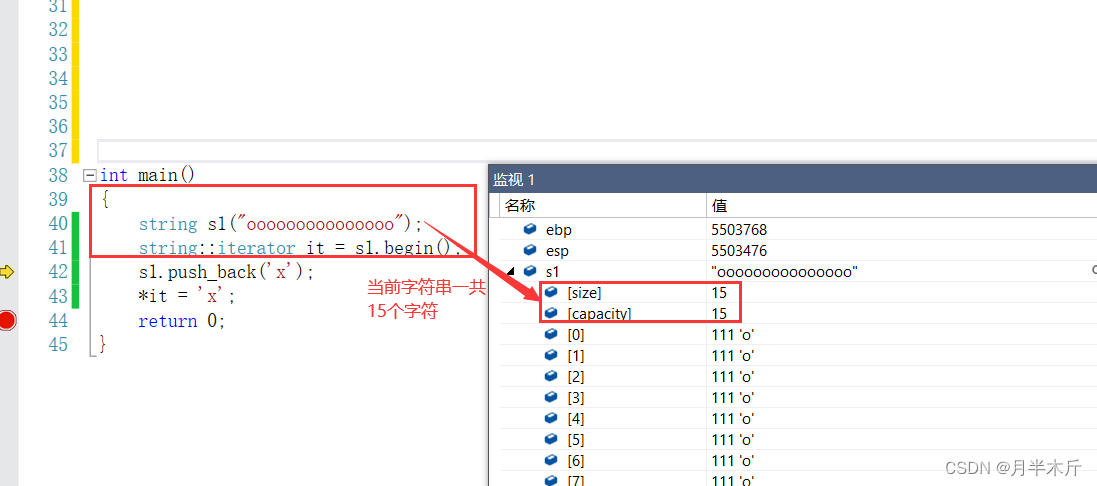
-
string中删除当前迭代器位置的元素是不会导致迭代器失效的:但是vector中会导致迭代器失效,具体可以看我关于vector的博客.。
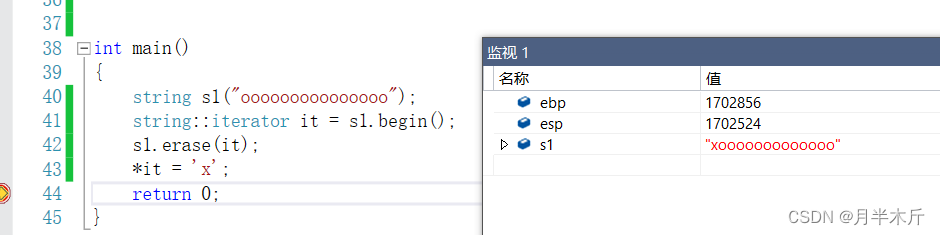
-
这里类似于push_back或者resize和reverse这一类的操作都会使得迭代器失效。
三、string的小应用:
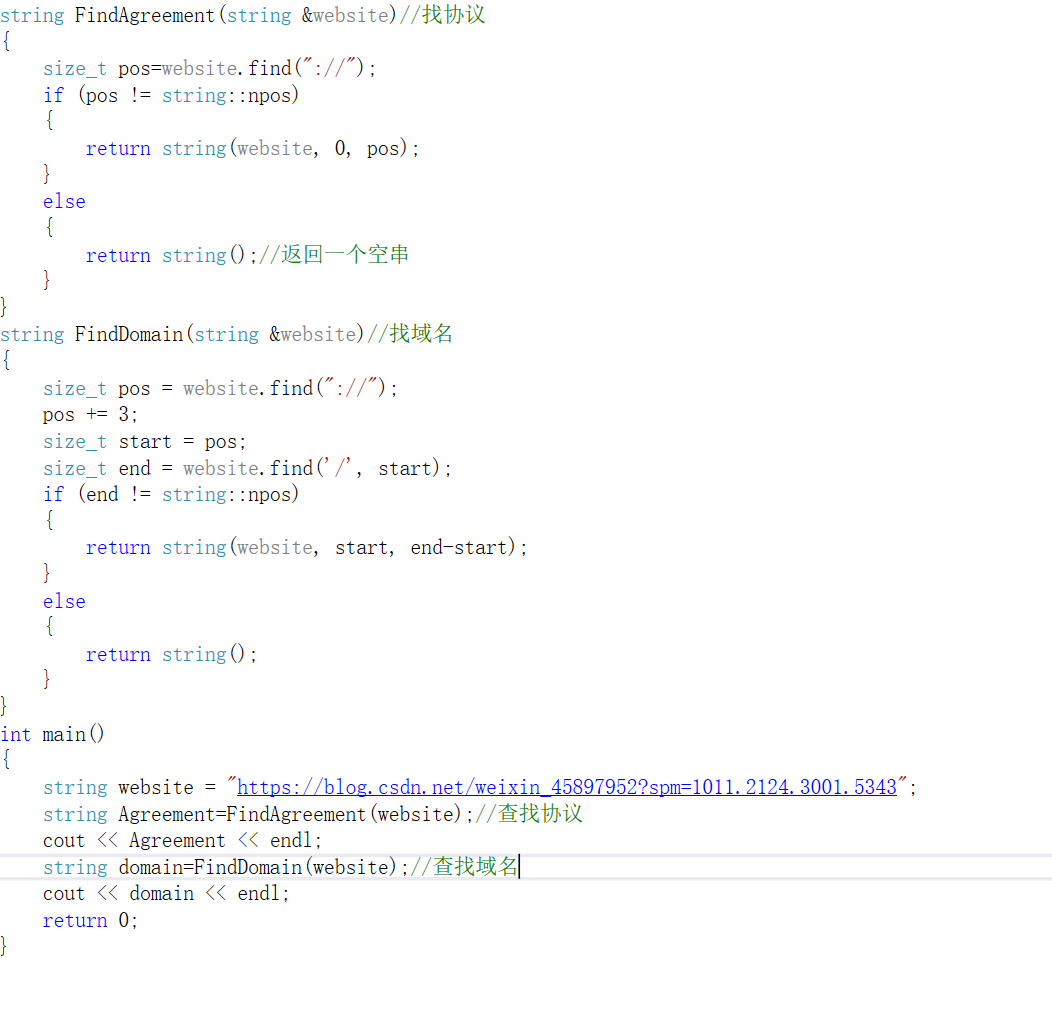
- 我们写一个查找网络的协议和域名的函数:
四、string类的模拟实现:
-
#include<iostream> #include<string> #include<string.h> #include<assert.h> //using namespace std; #pragma warning(disable:4996) namespace wbx { class string { public: friend class reverse_iterator; typedef char* iterator; //typedef char* reverse_iterator; class reverse_iterator; string(const char* str = "")//构造函数 { if (str == nullptr) { _size = 0; _capicity = 0; str = ""; _str = new char[strlen(str)+1]; _str = ""; } else { _size = strlen(str); _capicity = _size; _str = new char[_capicity+ 1]; strcpy(_str, str); } } string(const string &s)//拷贝构造 :_str(new char[s._size+1])//拷贝构造直接给当前对象开辟要拷贝的对象的空间大小 { strcpy(_str, s._str); _size = s._size; _capicity = s._capicity; } ~string()//析构 { if (_str != nullptr) { delete[] _str; _str = nullptr; _size = 0; _capicity = 0; } } void clear() { _str[0] = '\0'; _size = 0; } /重载运算符 string& operator=(const string& s)//string对象赋值 { if (&s != this) { delete[] _str; _str = new char[s._size + 1]; strcpy(_str, s._str); _size =s._size; _capicity = s._capicity; } return *this; } string& operator=(const char* str)//字符串复制 { if (str != nullptr) { delete[] _str; _str = new char[strlen(str) + 1]; strcpy(_str, str); _size = strlen(str); _capicity = _size; } return *this; } string &operator+=(const string& s) { return (*this).append(s); } string &operator+=(const char* s) { return (*this).append(s); } char operator[](size_t index) { if (index<0 || index>_size) { assert(false); } return _str[index]; } friend std::ostream& operator<<(std::ostream& _cout, const string& s) { _cout << s._str; return _cout;//返回之后支持连续输出cout<<a<<b<<endl;——》operator(operator(operator<<(cout,a),b),endl); } ///追加函数 string& append(const char* s)//追加字符串 { if (_capicity < _size + strlen(s)) { reserve(_size+strlen(s)); } strcpy(_str + _size, s); _size = _size + strlen(s); return *this; } string& append(const string &s)//追加字符串对象 { if (_capicity<_size + s._size) { reserve(_size + s._size); } strcpy(_str + _size, s._str); _size = _size + s._size; return *this; } string& append(size_t n,char s)//追加n个s字符 { if (_size + n>_capicity) { reserve(_size + n); } memset(_str + _size, s, n);//这里将字符串类型后面的空间内加入n个s字符会将'\0'覆盖,所以要手动加上 _size += n; _str[_size] = '\0'; return *this; } void push_back(char s) { append(1, s); } void pop_back(void) { _str[_size-1] = '\0'; _size--; } ///查找函数 char find(char c,size_t pos =0) { if (pos <_size) { for (size_t i = pos; i < _size; i++) { if (_str[i] ==c) { return i; } } } return npos;//找不到或者超出字符串范围都返回npos } char rfind(char c, size_t pos = npos) { if (pos >= _size) { pos = _size - 1; } for (; pos >= 0; pos--) { if (_str[pos] == c) { return pos; } } } string substr(size_t pos = 0, size_t len = npos) { if (pos >= _size) { assert(false); } if (len >= _size) { len = _size; } int newsize = len ; char* t = new char [newsize+1]; memcpy(t,((this->_str)+ pos), newsize); t[newsize] = '\0';/这里一定要加'\0'要不然构造的时候无法构造 string temp(t); return temp; } ///扩容函数 void reserve(size_t n)//扩容函数 { if (n > _capicity)//n大于当前容量的话扩容2倍 { size_t newcapicity = 2 * n; char *temp = new char[newcapicity]; strcpy(temp, _str); delete _str; _str = temp; _capicity = newcapicity; } } void resize(size_t n,char c='0') { if (n < _size)//如果小于_size就将n位置即n位置以后的元素置为0 { _str[n]='\0'; _size = n; } else { append(n-_size, c);//这里第一个参数要传递的是要在string后面追加的字符数量 } //append(n, c); } //返回基本信息 size_t size()const { return _size; } size_t capicity()const { return _capicity; } const char* c_str()const { return _str; } /迭代器 iterator begin() { return _str; } iterator end() { return _str + _size; } reverse_iterator rbegin() { return reverse_iterator(end()); } reverse_iterator rend() { return reverse_iterator(begin()); } class reverse_iterator { public: friend string; reverse_iterator(char *it = nullptr) :_it(it) { } reverse_iterator operator++()//前置++ { _it -= 1; return *this; } reverse_iterator operator++(int)//后置++ { reverse_iterator temp(*this); _it = _it - 1; return temp; } reverse_iterator operator--()//前置-- { _it += 1; return *this; } reverse_iterator operator--(int)//后置-- { reverse_iterator temp(*this); _it = _it + 1; return temp; } reverse_iterator& operator =(reverse_iterator& s) { return s; } char * _it; }; private: char * _str; size_t _capicity; size_t _size; static size_t npos; }; size_t string::npos = -1; } using namespace wbx; void test1() { string s1("head"); string s2; s2 = s1; s2 = "sssssss"; s1.append("ooooooo"); string s3=s1.append(s2); s3 += s1; } void test2() { string s1("ooooo"); s1.resize(3); s1.resize(7); s1.resize(8,'i'); s1.push_back('s'); s1.pop_back(); } using namespace wbx; void test3() { string s1("sadfasdg"); //size_t c=s1.find('a', 111); string s = s1.substr(2, 3); //char *s = "dsf"; s1.rbegin(); string::reverse_iterator it= s1.rbegin();//reverse_iterator在string类中所以要加string类的作用域限定符 string::reverse_iterator ii = s1.rend(); it++; ii--; } int main() { //string s("sdf"); //s.append(2, 's'); //test1(); //test2(); test3(); return 0; }