高可用架构(扩容多Master架构)
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而Etcd我们已经采用3个节点组建集群实现高可用,本节将对Master节点高可用进行说明和实施。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。(master至少部署两个就行了,起到一个主备的作用)
多Master架构图:

多master的话,那就涉及到node连接到哪个master。所以必须提供一个地址给node去连接,并且可以保证其中一个master挂了,集群都不受到影响。(同时LB也不能单点故障)
安装Docker
同上,不再赘述。
部署Master2 Node(192.168.111.6)
Master2 与已部署的Master1所有操作一致。所以我们只需将Master1所有K8s文件拷贝过来,再修改下服务器IP和主机名启动即可。
1. 创建etcd证书目录
在Master2创建etcd证书目录:
[root@k8s-master2 ~]# mkdir -p /opt/etcd/ssl
2. 拷贝文件(Master1操作)
拷贝Master1上所有K8s文件和etcd证书到Master2:
scp -r /opt/kubernetes [email protected]:/opt
scp -r /opt/cni/ [email protected]:/opt
scp -r /opt/etcd/ssl [email protected]:/opt/etcd
scp /usr/lib/systemd/system/kube* [email protected]:/usr/lib/systemd/system
scp /usr/bin/kubectl [email protected]:/usr/bin 3. 删除证书文件
删除kubelet证书和kubeconfig文件:
rm -rf /opt/kubernetes/cfg/kubelet.kubeconfig
rm -rf /opt/kubernetes/ssl/kubelet* 4. 修改配置文件IP和主机名
修改apiserver、kubelet和kube-proxy配置文件为本地IP:
vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--bind-address=192.168.31.74 \
--advertise-address=192.168.31.74 \
...
vi /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8s-master2
vi /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8s-master25. 启动设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl start kube-controller-manager
systemctl start kube-scheduler
systemctl start kubelet
systemctl start kube-proxy
systemctl enable kube-apiserver
systemctl enable kube-controller-manager
systemctl enable kube-scheduler
systemctl enable kubelet
systemctl enable kube-proxy6. 查看集群状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}7. 批准kubelet证书申请
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU 85m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
kubectl certificate approve node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready <none> 34h v1.18.3
k8s-master2 Ready <none> 83m v1.18.3
k8s-node1 Ready <none> 33h v1.18.3
k8s-node2 Ready <none> 33h v1.18.3部署Nginx负载均衡器
kube-apiserver高可用架构图:
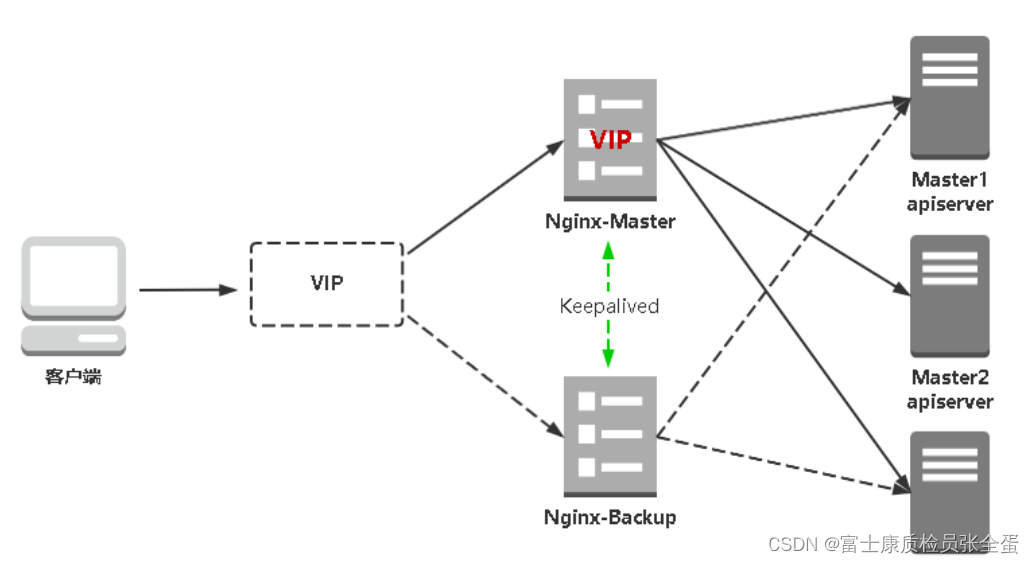
- Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
- Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
我这里就直接使用Haproxy了,原理和Nginx一样。
使用 Keepalived 和 HAproxy 创建高可用 Kubernetes 集群如何使用 Keepalived 和 HAproxy 配置高可用 Kubernetes 集群。
集群架构
示例集群有三个主节点,三个工作节点,两个用于负载均衡的节点,以及一个虚拟 IP 地址。本示例中的虚拟 IP 地址也可称为“浮动 IP 地址”。这意味着在节点故障的情况下,该 IP 地址可在节点之间漂移,从而实现高可用。

请注意,在本示例中,Keepalived 和 HAproxy 没有安装在任何主节点上。但您也可以这样做,并同时实现高可用。然而,配置两个用于负载均衡的特定节点(您可以按需增加更多此类节点)会更加安全。这两个节点上只安装 Keepalived 和 HAproxy,以避免与任何 Kubernetes 组件和服务的潜在冲突。
配置负载均衡
Keepalived 提供 VRRP 实现,并允许您配置 Linux 机器使负载均衡,预防单点故障。HAProxy 提供可靠、高性能的负载均衡,能与 Keepalived 完美配合。
由于 lb1 和 lb2 上安装了 Keepalived 和 HAproxy,如果其中一个节点故障,虚拟 IP 地址(即浮动 IP 地址)将自动与另一个节点关联,使集群仍然可以正常运行,从而实现高可用。若有需要,也可以此为目的,添加更多安装 Keepalived 和 HAproxy 的节点。
先运行以下命令安装 Keepalived 和 HAproxy。
yum install keepalived haproxy psmisc -y
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时[root@k8s-master ~]# netstat -tpln | grep 6443
tcp 0 0 192.168.111.3:6443 0.0.0.0:* LISTEN 851/kube-apiserver
[root@k8s-master2 ~]# netstat -tpln | grep 6443
tcp 0 0 192.168.111.6:6443 0.0.0.0:* LISTEN 2947/kube-apiserver HAproxy
在两台用于负载均衡的机器上运行以下命令以配置 Proxy(两台机器的 Proxy 配置相同):
vi /etc/haproxy/haproxy.cfg以下是示例配置,供您参考(请注意 server 字段。请记住 6443 是 apiserver 端口):
global
log /dev/log local0 warning
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend kube-apiserver
bind *:6443
mode tcp
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server kube-apiserver-1 192.168.111.3:6443 check # Replace the IP address with your own.
server kube-apiserver-2 192.168.111.6:6443 check # Replace the IP address with your own.
listen admin_stat
bind 0.0.0.0:8888
mode http
stats refresh 30s
stats uri /haproxy_stats
stats realm Haproxy\ Statistics
stats auth admin:admin
stats hide-version使用HA后在配置文件里边配置了监控页面信息后,可以在浏览器中访问地址去看到。
#haproxy监控页面地址
listen admin_stat
#haproxy的web管理端口 8888,自行设置
bind 0.0.0.0:8888
mode http
stats refresh 30s
#haproxy web管理url,自行设置
stats uri /haproxy_stats
stats realm Haproxy\ Statistics
#haproxy web管理用户名密码,自行设置
stats auth admin:admin
stats hide-version
浏览器访问
http://192.168.1.1:xxxx/haproxy_stats-

保存文件并运行以下命令以重启 HAproxy。
systemctl restart haproxy -
使 HAproxy 在开机后自动运行:
systemctl enable haproxy -
确保您在另一台机器 (
lb2) 上也配置了 HAproxy。
Keepalived
两台机器上必须都安装 Keepalived,但在配置上略有不同。
(1) 运行以下命令以配置 Keepalived。
vi /etc/keepalived/keepalived.conf
(2) 以下是示例配置 (lb1),供您参考:
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 100
interface eno16777736 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 192.168.111.7 # The IP address of this machine
unicast_peer {
192.168.111.8 # The IP address of peer machines
}
virtual_ipaddress {
192.168.111.9/24 # The VIP address
}
track_script {
chk_haproxy
}
}
对于
interface字段,您必须提供自己的网卡信息。您可以在机器上运行ifconfig以获取该值。为
unicast_src_ip提供的 IP 地址是您当前机器的 IP 地址。对于也安装了 HAproxy 和 Keepalived 进行负载均衡的其他机器,必须在字段unicast_peer中输入其 IP 地址。
(3) 保存文件并运行以下命令以重启 Keepalived。
systemctl restart keepalived
(4) 使 Keepalived 在开机后自动运行:
systemctl enable keepalived
(5) 确保您在另一台机器 (lb2) 上也配置了 Keepalived。
验证高可用
在开始创建 Kubernetes 集群之前,请确保已经测试了高可用。
(1) 在机器 lb1 上,运行以下命令:
[root@lb1 ~]# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:9e:27:38:c8 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.2/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0
valid_lft 73334sec preferred_lft 73334sec
inet 172.16.0.10/24 scope global secondary eth0 # The VIP address
valid_lft forever preferred_lft forever
inet6 fe80::510e:f96:98b2:af40/64 scope link noprefixroute
valid_lft forever preferred_lft forever
(2) 如上图所示,虚拟 IP 地址已经成功添加。模拟此节点上的故障:
systemctl stop haproxy
(3) 再次检查浮动 IP 地址,您可以看到该地址在 lb1 上消失了。
[root@lb1 ~]# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:9e:27:38:c8 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.2/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0
valid_lft 72802sec preferred_lft 72802sec
inet6 fe80::510e:f96:98b2:af40/64 scope link noprefixroute
valid_lft forever preferred_lft forever
(4) 理论上讲,若配置成功,该虚拟 IP 会漂移到另一台机器 (lb2) 上。在 lb2 上运行以下命令,这是预期的输出:
[root@lb2 ~]# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:9e:3f:51:ba brd ff:ff:ff:ff:ff:ff
inet 172.16.0.3/24 brd 172.16.0.255 scope global noprefixroute dynamic eth0
valid_lft 72690sec preferred_lft 72690sec
inet 172.16.0.10/24 scope global secondary eth0 # The VIP address
valid_lft forever preferred_lft forever
inet6 fe80::f67c:bd4f:d6d5:1d9b/64 scope link noprefixroute
valid_lft forever preferred_lft forever
(5) 如上所示,高可用已经配置成功。
修改所有Worker Node连接LB VIP
试想下,虽然我们增加了Master2和负载均衡器,但是我们是从单Master架构扩容的,也就是说目前所有的Node组件连接都还是Master1,如果不改为连接VIP走负载均衡器,那么Master还是单点故障。
因此接下来就是要改所有Node组件配置文件,由原来192.168.111.3修改为192.168.111.9(VIP):
在上述所有Worker Node执行:
sed -i 's#192.168.111.3:6443#192.168.111.9:6443#' /opt/kubernetes/cfg/*
systemctl restart kubelet
systemctl restart kube-proxy[root@k8s-master k8s]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready etcd,master 18d v1.18.3
k8s-master2 Ready master 4h44m v1.18.3
k8s-node1 Ready etcd,worker 15d v1.18.3
k8s-node2 Ready etcd,worker 15d v1.18.3