计算机视觉杂谈
计算机将越来越广泛地进入几乎所有领域。一方面是更多未经计算机专业训练的人也需要应用计算机,而另一方面是计算机的功能越来越强,使用方法越来越复杂。这就使人在进行交谈和通讯时的灵活性与在使用计算机时所要求的严格和死板之间产生了尖锐的矛盾。人可通过视觉和听觉,语言与外界交换信息,并且可用不同的方式表示相同的含义,而计算机却要求严格按照各种程序语言来编写程序,只有这样计算机才能运行。为使更多的人能使用复杂的计算机,必须改变过去的那种让人来适应计算机,来死记硬背计算机的使用规则的情况。而是反过来让计算机来适应人的习惯和要求,以人所习惯的方式与人进行信息交换,也就是让计算机具有视觉、听觉和说话等能力。这时计算机必须具有逻辑推理和决策的能力。具有上述能力的计算机就是智能计算机。
参考文献链接
https://baike.baidu.com/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/2803351?fr=aladdin
https://mp.weixin.qq.com/s/sTqiHkSvBN8NG–GxtpUeg
https://mp.weixin.qq.com/s/K7XASAAisgkPMX0juuZ3sA
智能计算机不但使计算机更便于为人们所使用,同时如果用这样的计算机来控制各种自动化装置特别是智能机器人,就可以使这些自动化系统和智能机器人具有适应环境,和自主作出决策的能力。这就可以在各种场合取代人的繁重工作,或代替人到各种危险和恶劣环境中完成任务。
应用范围从任务,比如工业机器视觉系统,比方说,检查瓶子上的生产线加速通过,研究为人工智能和计算机或机器人,可以理解他们周围的世界。计算机视觉和机器视觉领域有显著的重叠。计算机视觉涉及的被用于许多领域自动化图像分析的核心技术。机器视觉通常指的是结合自动图像分析与其他方法和技术,以提供自动检测和机器人指导在工业应用中的一个过程。在许多计算机视觉应用中,计算机被预编程,以解决特定的任务,但基于学习的方法现在正变得越来越普遍。计算机视觉应用的实例包括用于系统:
(1)控制过程,比如,一个工业机器人 ;
(2)导航,例如,通过自主汽车或移动机器人;
(3)检测的事件,如,对视频监控和人数统计 ;
(4)组织信息,例如,对于图像和图像序列的索引数据库;
(5)造型对象或环境,如,医学图像分析系统或地形模型;
(6)相互作用,例如,当输入到一个装置,用于计算机人的交互;
(7)自动检测,例如,在制造业的应用程序。
其中最突出的应用领域是医疗计算机视觉和医学图像处理。这个区域的特征的信息从图像数据中提取用于使患者的医疗诊断的目的。通常,图像数据是在形式显微镜图像,X射线图像,血管造影图像,超声图像和断层图像。的信息,可以从这样的图像数据中提取的一个例子是检测的肿瘤,动脉粥样硬化或其他恶性变化。也可以是器官的尺寸,血流量等。这种应用领域还支持通过提供新的信息,医学研究的测量例如,对脑的结构,或约医学治疗的质量。计算机视觉在医疗领域的应用还包括增强是由人类的解释,例如超声图像或X射线图像,以降低噪声的影响的图像。
第二个应用程序区域中的计算机视觉是在工业,有时也被称为机器视觉,在那里信息被提取为支撑的制造工序的目的。一个例子是质量控制,其中的信息或最终产品被以找到缺陷自动检测。另一个例子是,被拾取的位置和细节取向测量由机器人臂。机器视觉也被大量用于农业的过程,从散装材料,这个过程被称为去除不想要的东西,食物的光学分拣。
军事上的应用很可能是计算机视觉最大的地区之一。最明显的例子是探测敌方士兵或车辆和导弹制导。更先进的系统为导弹制导发送导弹的区域,而不是一个特定的目标,并且当导弹到达基于本地获取的图像数据的区域的目标做出选择。现代军事概念,如“战场感知”,意味着各种传感器,包括图像传感器,提供了丰富的有关作战的场景,可用于支持战略决策的信息。在这种情况下,数据的自动处理,用于减少复杂性和融合来自多个传感器的信息,以提高可靠性。
一个较新的应用领域是自主车,其中包括潜水,陆上车辆(带轮子,轿车或卡车的小机器人),高空作业车和无人机(UAV)。自主化水平,从完全独立的(无人)的车辆范围为汽车,其中基于计算机视觉的系统支持驱动程序或在不同情况下的试验。完全自主的汽车通常使用计算机视觉进行导航时,即知道在哪里,或用于生产的环境(地图SLAM)和用于检测障碍物。也可以被用于检测特定任务的特定事件,例如,一个UAV寻找森林火灾。支承系统的例子是障碍物警报系统中的汽车,以及用于飞行器的自主着陆系统。数家汽车制造商已经证明了系统的汽车自动驾驶,但该技术还没有达到一定的水平,就可以投放市场。有军事自主车型,从先进的导弹,无人机的侦察任务或导弹的制导充足的例子。太空探索已经正在使用计算机视觉,自主车比如,美国宇航局的火星探测漫游者和欧洲航天局的ExoMars火星漫游者。
其他应用领域包括:
(1)支持视觉特效制作的电影和广播,例如,摄像头跟踪(运动匹配)。
(2)监视。
深度学习和机器视觉分析
一、深度学习:理论和关注机制的进展(Yoshua Bengio)
顾名思义,Bengio的talk主要讲了两个部分:理论进展和attention mechanism。理论进展介绍了:
• 分布式表示的“指数级”优点
• 深度的“指数级”优点
• 非凸优化和局部最小值
• 自编码器的概率解释
Attention 机制则介绍了在机器翻译、语音、图像、视频和记忆单元中的应用。
分布式表示和深度的优点Bengio,简单的说,虽然类似local partition的方法可以得到有用的表示,浅层(2层)的神经网络也可近似任意的函数,但是分布式表示和深度的引入可以使特征表示和模型变得更加紧凑(compact),达到exponentially more statistically efficient的效果。
接下来提到了在深度学习中凸性质(convexity)可能并不是必要的。因为在高维空间中,鞍点(saddle point)的存在是主要问题,而局部最小值通常都会很接近全局最小值了。这部分的内容比较陌生,有兴趣可以看看最近的论文。
Attention 机制方面,讲了很多最新的进展。有很多相关的paper都非常有趣,要找个时间好好看看这个系列了。一个基本的思路是:给每一层引入一个额外的输入,这个输入反应的是之前的一个加权,来表示关注程度。在所谓的soft-attention中,这个加权的值可以直接通过BP训练得到。
二、深度语义学习 (Xiaodong He)
来自微软研究院的报告,主要内容:
• 学习文本的语义性(semantic)表示
• 知识库和问答系统
• 多模态(图片——文本)语义模型
讲座开始引入了一点有趣的motivation:一般测试机器是否能够理解图片(其实就是训练对了),方法是给图片标记标签然后计算其错误率。然而对于含有丰富内容的复杂场景来说,很难定义所有fine-grained的类别。因此,用自然语言的描述来测试对图片的理解是比较好的方式。
从 Word2Vec 到 Sent2Vec:Deep Structured Semantic Model (DSSM),虽然不知道该如何标记一个句子的语义,但知道哪些句子的语义是比较接近的,因此文章通过优化一个基于相似性的目标函数来训练模型,使具有相近语义的句子产生距离相近的向量。接着还介绍了很多模型的细节和变种(卷积DSSM、递归DSSM),在此就不赘述了。
Deep Multimodal Similarity Model (DMSM):将目标函数中两个句子的相似性改成句子和图片的相似性,便可以将DSSM扩展为一个多模态的模型。
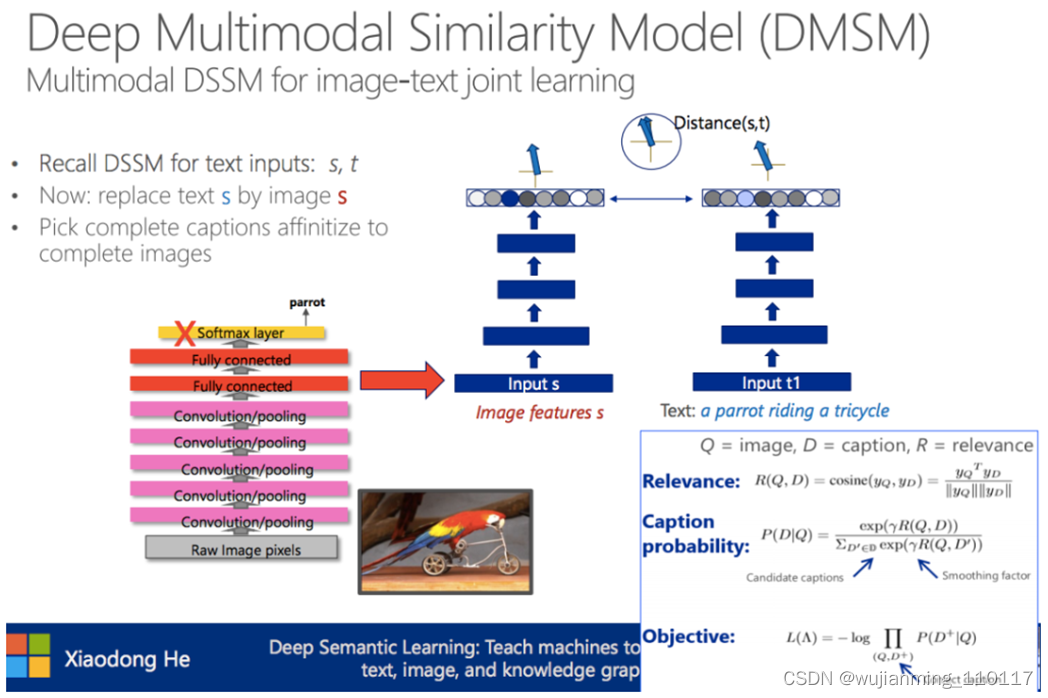
MSR系统解决图片–>语言问题:
• 图片词语检测(Image word detection)
• 句子生成(Language generation)
• 全局语义性重排序(Global semantic re-ranking)
其中图片词语检测用了CNN+MIL(Multiple Instance Learning)的方法,个人对此比较感兴趣,文章在此。
三、深度神经网络和GPU(Julie Bernauer)
换个口味,来看看NVIDIA关于深度学习和GPU的结合。总的来说,内容上跟NVIDIA官网上介绍深度学习的slides没什么不同。主要介绍了GPU有什么好处、GPU有多牛,还有一些支持GPU的库和工具。
一张比较好的图:

有用的工具:
• Lasagne:基于theano上的开源库,能方便搭建一个深度网络。(Keras用得不太爽,可以试试这个)
四、深度视觉Keynote(Rahul Sukthankar)
来看看来自google的报告。这个talk里面的内容都不太熟悉,但是看起来都非常有意思。主要内容有:
• 用Peer Presssure方法来找high value mistake
• 结合深度学习和其他机器学习方法来更好解决视觉问题
首先来看看Peer Pressure。这是Rahul组最近的一个工作:The Virtues of Peer Pressure: A Simple Method for Discovering High-Value Mistakes。所谓“high-value mistake”,指的是那些认为训练好的模型可以准确预测的样本,结果却“犯傻”了。因此这些样本也叫做“hard positive”,难以答对的样子。
从头说起,深度神经网络虽然有很多成功的应用,但同时也被发现很容易犯愚蠢的错误(比如上述的high-value mistake)。因此作者提出了Peer Pressure:集成+对抗训练(emsembles+adversarial training)的方法,来找到这些错误。简单来说就是,有一组训练于同样数据但是初始化或者结构不同的NN分类器(称作peers),如果一个样本出现其中一个NN输出与其它都不一致的情况(其它NN淡然都是一致的了),那么应该就是high-value mistake。寻找这类错误当然是有价值的啦:(1)可以用在发掘无标签的数据中(2)可以用来合成新的hard positive样本。
接下来提到将上述的方法应用到视频当中,找出anchor frame附近的hard positive 帧,用来训练更好的模型。其中具有semantic consistency的帧是通过Dense Trajectory来确定的。感觉挺有意思,可惜没找到相应的paper,那就上张图吧。

五、学习和理解视觉表示(Andrea Vedaldi)
来自牛津大学的报告,题目看起来还是很吸引人的。大纲如下(略有失望,好像就是讲CNN的):
• 黑盒:一个将CNN用于图片文字识别的例子
• 架构:卷积和纹理
• 可视化:CNN所知道的图片
• 性质:对比CNN和视觉几何
第一个例子用CNN做OCR,感觉并不是很有趣。一个challenge是类别特别多(90k个类,对应90k个单词)。他们解决的办法是增量地训练网络,即先只训练5k个类,再逐步添加5k个新的类,效果好像还不错。
第二部分讲分辨纹理。提出用CNN的卷积层加上Fisher Vector(替换全连接层)来做,效果不错不错的。
第三部分可视化,看看就好。
第四部分还不错,讲的是图像变换对特征表示的影响。除去语义层面上的影响(特征的不变性跟任务相关),通常希望图像的特征表示不受图像变换的影响,如翻转和仿射变换。
类内差异大,包括:部分出现(part existence)、颜色、遮挡、变形

六、用于目标检测的可变深度卷积神经网络(Xiaogang Wang)
最后一个talk,讲的是最近比较关注的目标检测问题,主要介绍他们的DeepID-Net。
第一部分他们的工作,用深度学习进行行人识别。其中着重讲了通过设计大小可变的卷积核来实现部分检测器(Part detector),对于行人识别应该是重要的一部分。
第二部分讲更general的目标检测问题。首先介绍目标检测的困难有(经筛选),
对比了他们的DeepID-Net和RCNN:

详细AI专家路线图谱
这个学习路线图几乎涵盖了人工智能领域的所有内容,点点鼠标,就能链接所需知识。
想从事人工智能领域的研究,盲目地在网上购买了一本又一本的参考资料,学习视频刷了一遍又一遍…… 反过头来看,这些方法可能作用并不是很大,却消耗了大量的时间和金钱。
这时,一种提纲式的学习途径就显得尤为重要了。如果想成为数据科学家、机器学习或者 AI 专家,而又苦于找不到合适的学习方法,本文将提供一组思路清晰、简单易懂的人工智能专家路线图。
超详细的AI 专家路线图
对学习者非常友好的是,这份 AI 专家路线图是一个互动版本。每个子模块所列内容都可以链接到指定网站,学习者可以找到词条的维基百科或其他来源的释义和拓展内容。此外,如果有新的研究出现时,该路线图会随时更新。
该路线图旨在给学习者提供关于人工智能的整体概念,并在学习感到困惑时给予指导,而没有鼓励学习者一味地选择最先进、最热门的技术。这是因为在科研中,每个人都需要了解哪种工具最适合自己。换言之,最先进、最热门的技术不一定是最适合的。
就这份 AI 专家路线图而言,开发者列出了任何学习路径所必不可少的一些要素,如论文和代码、版本控制、语义化版本控制和更新日志。但就具体选择上,开发者认为在学习 AI 时不应直接过渡到当前热门的技术——深度学习,而应步步为营,并提供了 3 条可供选择的学习路径:数据科学家→机器学习→深度学习…;数据科学家→数据工程师…;大数据工程师→…
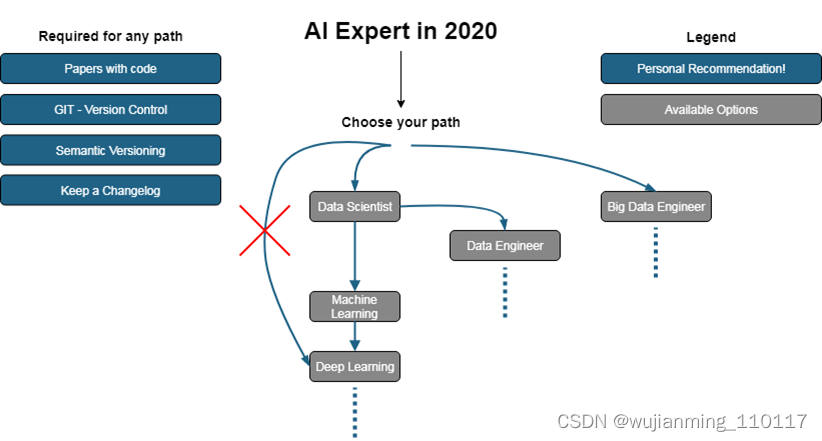
循序渐进才是「王道」。
AI 专家路线图概览
这部分内容简要总结了 AI 专家路线图,并从以下几个方面着手讲解:数据科学家、机器学习、深度学习、数据工程师以及大数据工程师。这 5 部分内容都有详细的学习路线图,点击图表任意模块,都会链接到对应的内容。
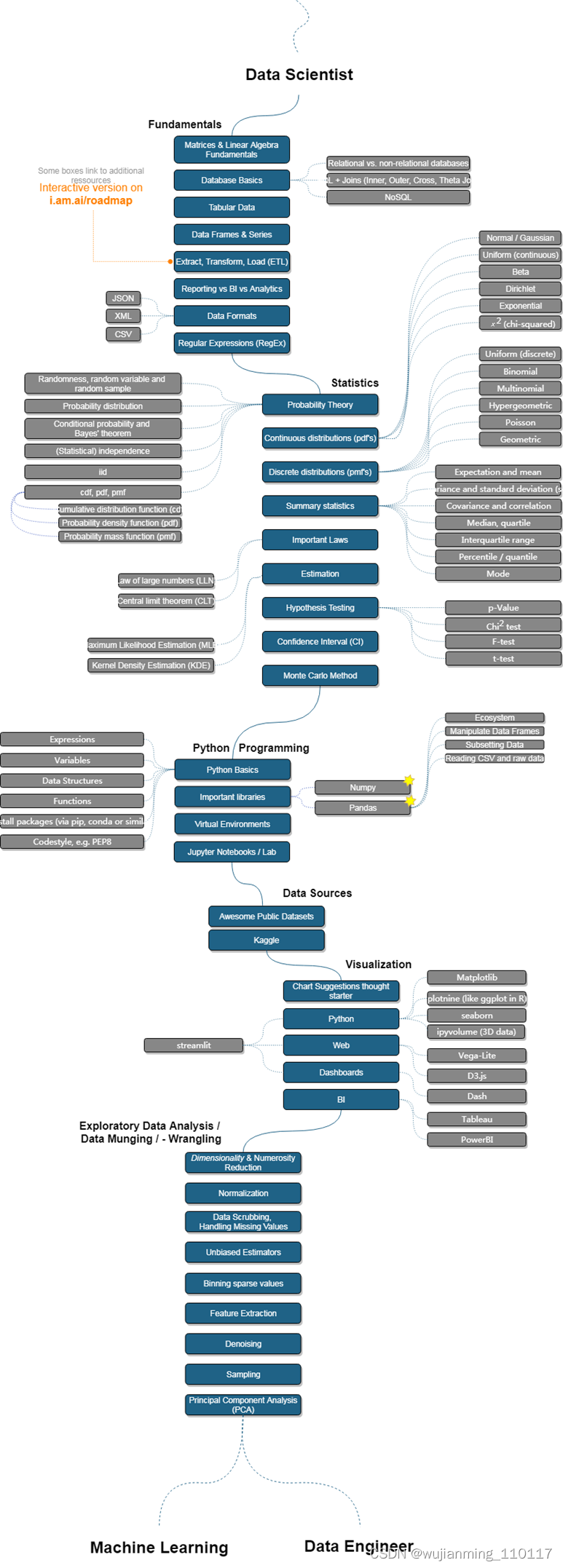
一、数据科学家路线图
在数据科学家路线图中,可以了解到进行 AI 研究所需要的基础:矩阵和线性代数、数据库、表格数据、数据格式(JSON、XML、CSV)、正则表达式等等。
在统计学方面,该路线图涵盖了概率论、概率分布、估计、假设检验、置信区间、大数定律、蒙特卡罗方法等等。
在 Python 编程方面,该路线图展示了 Python 基础、比较重要的 Python 库以及所需运行环境等。
在数据来源方面,学习者点击「Awesome Public Datasets」图标,就可以链接到整理好的公共数据集等。接着过渡到可视化和探索性数据分析 / 转换 / 整理相关内容,最后进入到机器学习和数据工程师两个不同的方向。
二、机器学习路线图
机器学习路线图主要分为 4 大部分:基础概念、算法、用例以及所用工具。其中基础概念部分主要包括机器学习中常用的概念、梯度下降、训练集、测试集、验证集等基础概念;算法部分列举了 4 类算法:监督学习、无监督学习、集成学习和强化学习;用例部分列举了情感分析、协同过滤、标注和预测;所用工具部分则介绍了 scikit-learn、spacy 等工具。每部分内容都有对应的详细文档。
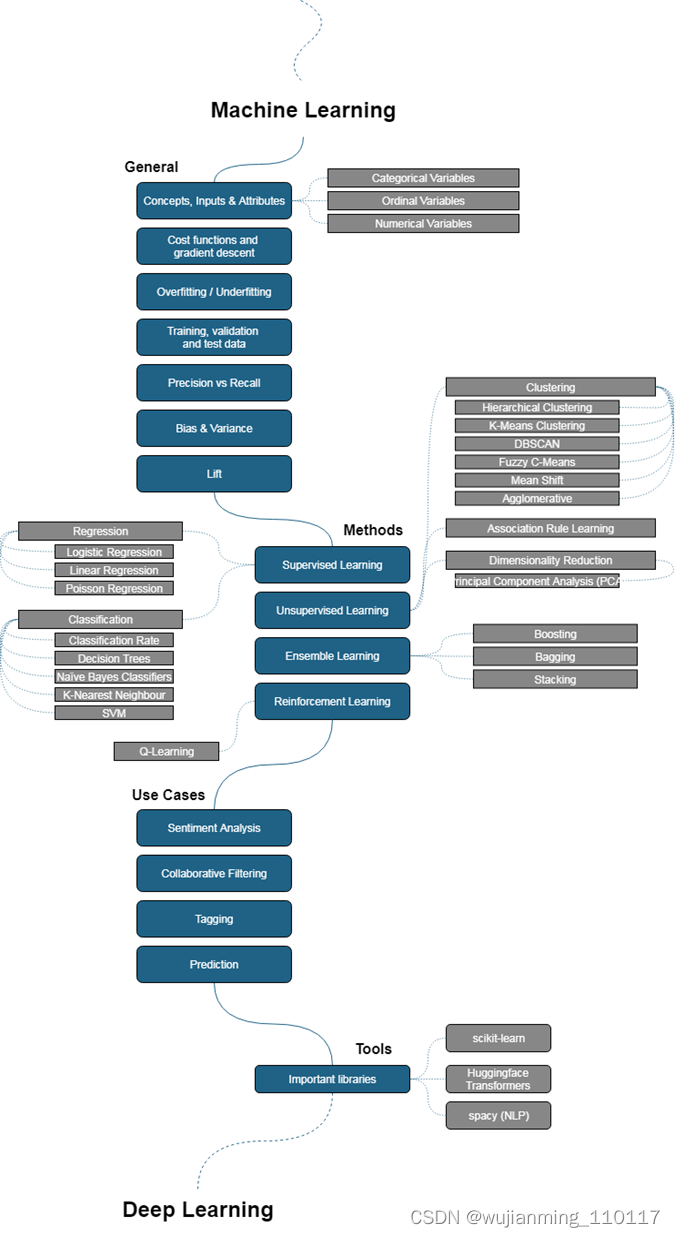
三、深度学习路线图
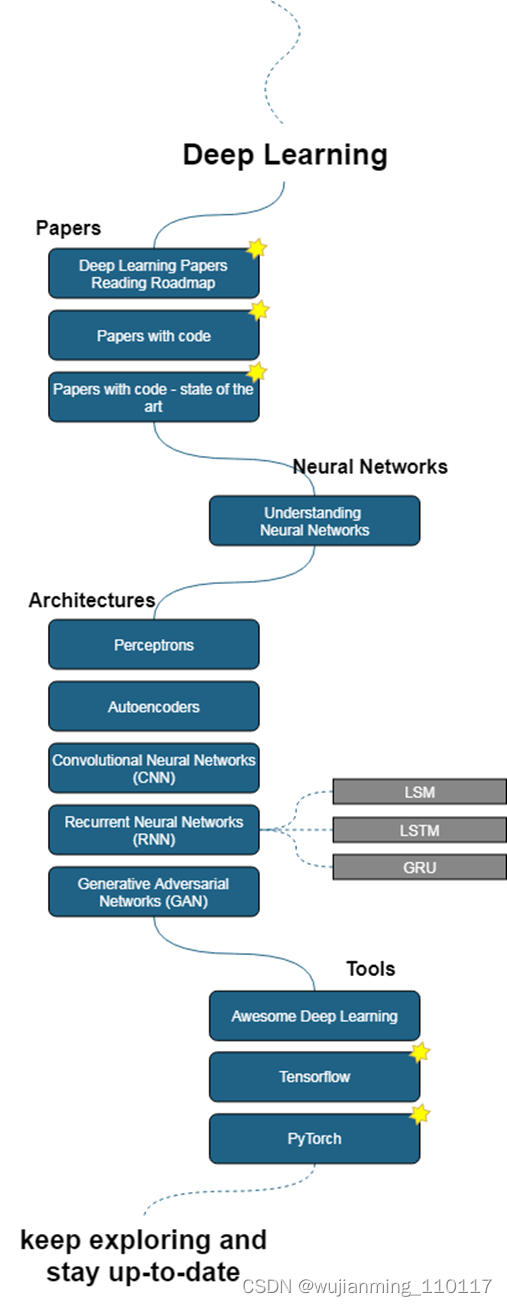
机器学习之后进入到了深度学习,这是第 1 条可选择学习路径的最后部分。深度学习路线图由 4 大部分组成:论文、神经网络、网络架构以及所用工具。论文部分提供了深度学习论文阅读路线图以及 SOTA 论文;神经网络部分提供了一篇详细介绍如何理解神经网络的博客文章;网络架构部分包括感知器、自动编码器、CNN、RNN;所用工具部分主要介绍了 TensorFlow 、PyTorch 等。最后给出建议:保持探索、与时俱进。
四、数据工程师路线图
在数据科学家路线图之后可以直接进入到数据工程师路线图,这是第 2 条可选择的学习路径。该路线图主要介绍了数据格式、数据发现、数据集成、数据融合、数据调研、数据湖和数据仓库以及如何使用 ETL 等多方面内容。

五、大数据工程师路线图
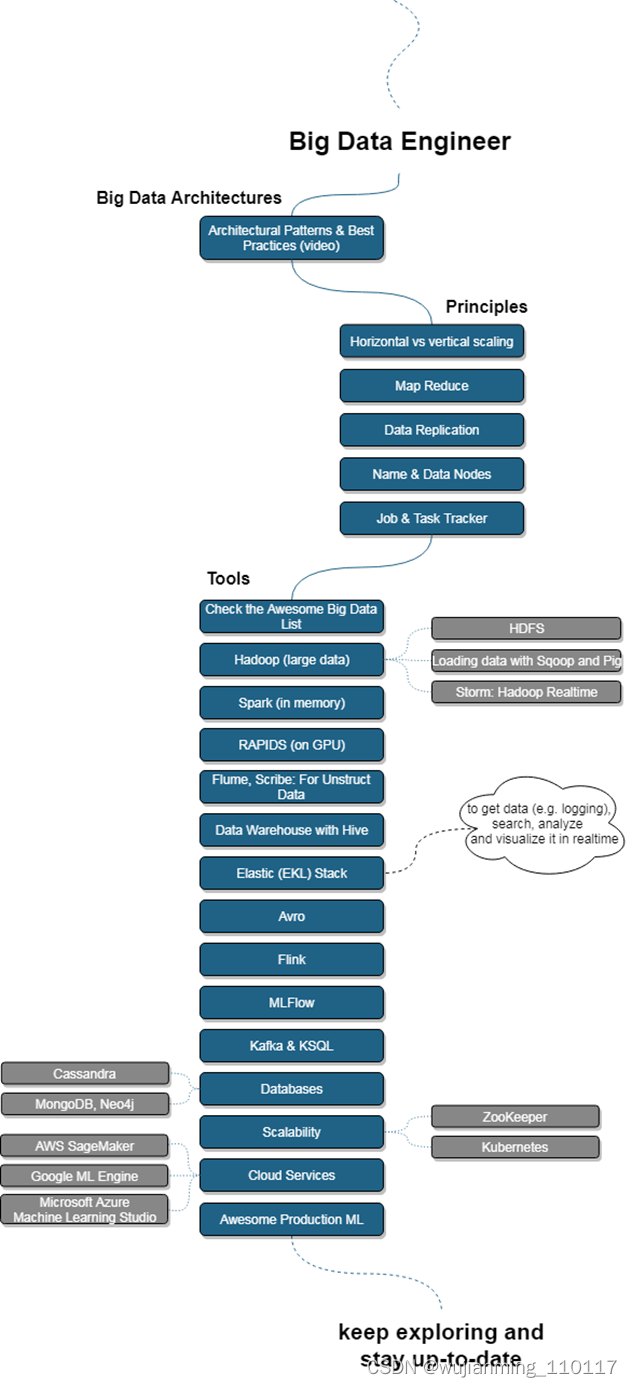
大数据工程师路线图是第 3 条可选择的学习路径,主要分为 3 部分内容:大数据架构、遵循的原则以及所用工具。大数据架构部分主要讲述了大数据分析架构模式和最佳实践;遵循的原则包括数据库管理系统中的数据复制,以及 Hadoop 中 NameNode 和 DataNode 的区别等;所用工具则介绍了 Hadoop、Spark 等。
参考文献链接
https://baike.baidu.com/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/2803351?fr=aladdin
https://mp.weixin.qq.com/s/sTqiHkSvBN8NG–GxtpUeg
https://mp.weixin.qq.com/s/K7XASAAisgkPMX0juuZ3sA